 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Nov 11, 2025Improving reasoning capabilities of Large Language Models (LLMs), especially under parameter constraints, is crucial for real-world applications. Prior work proposes recurrent transformers, which allocate a fixed number of extra iterations per token to improve generation quality. After the first, standard forward pass, instead of verbalization, last-layer hidden states are fed back as inputs for additional iterations to refine token predictions. Yet we identify a latent overthinking phenomenon: easy token predictions that are already correct after the first pass are sometimes revised into errors in additional iterations. To address this, we propose Think-at-Hard (TaH), a dynamic latent thinking method that iterates deeper only at hard tokens. It employs a lightweight neural decider to trigger latent iterations only at tokens that are likely incorrect after the standard forward pass. During latent iterations, Low-Rank Adaptation (LoRA) modules shift the LLM objective from general next-token prediction to focused hard-token refinement. We further introduce a duo-causal attention mechanism that extends attention from the token sequence dimension to an additional iteration depth dimension. This enables cross-iteration information flow while maintaining full sequential parallelism. Experiments show that TaH boosts LLM reasoning performance across five challenging benchmarks while maintaining the same parameter count. Compared with baselines that iterate twice for all output tokens, TaH delivers 8.1-11.3% accuracy gains while exempting 94% of tokens from the second iteration. Against strong single-iteration Qwen3 models finetuned with the same data, it also delivers 4.0-5.0% accuracy gains. When allowing less than 3% additional parameters from LoRA and the iteration decider, the gains increase to 8.5-12.6% and 5.3-5.4%, respectively. Our code is available at https://github.com/thu-nics/TaH.
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
May 27, 2025Large Language Models (LLMs) achieve impressive reasoning capabilities at the cost of substantial inference overhead, posing substantial deployment challenges. Although distilled Small Language Models (SLMs) significantly enhance efficiency, their performance suffers as they fail to follow LLMs' reasoning paths. Luckily, we reveal that only a small fraction of tokens genuinely diverge reasoning paths between LLMs and SLMs. Most generated tokens are either identical or exhibit neutral differences, such as minor variations in abbreviations or expressions. Leveraging this insight, we introduce **Roads to Rome (R2R)**, a neural token routing method that selectively utilizes LLMs only for these critical, path-divergent tokens, while leaving the majority of token generation to the SLM. We also develop an automatic data generation pipeline that identifies divergent tokens and generates token-level routing labels to train the lightweight router. We apply R2R to combine R1-1.5B and R1-32B models from the DeepSeek family, and evaluate on challenging math, coding, and QA benchmarks. With an average activated parameter size of 5.6B, R2R surpasses the average accuracy of R1-7B by 1.6x, outperforming even the R1-14B model. Compared to R1-32B, it delivers a 2.8x wall-clock speedup with comparable performance, advancing the Pareto frontier of test-time scaling efficiency. Our code is available at https://github.com/thu-nics/R2R.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025



Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
Policy-to-Language: Train LLMs to Explain Decisions with Flow-Matching Generated Rewards
Feb 18, 2025As humans increasingly share environments with diverse agents powered by RL, LLMs, and beyond, the ability to explain their policies in natural language will be vital for reliable coexistence. In this paper, we build a model-agnostic explanation generator based on an LLM. The technical novelty is that the rewards for training this LLM are generated by a generative flow matching model. This model has a specially designed structure with a hidden layer merged with an LLM to harness the linguistic cues of explanations into generating appropriate rewards. Experiments on both RL and LLM tasks demonstrate that our method can generate dense and effective rewards while saving on expensive human feedback; it thus enables effective explanations and even improves the accuracy of the decisions in original tasks.
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Visual Language Models
Dec 30, 2024
The increasing demand to process long and high-resolution videos significantly burdens Large Vision-Language Models (LVLMs) due to the enormous number of visual tokens. Existing token reduction methods primarily focus on importance-based token pruning, which overlooks the redundancy caused by frame resemblance and repetitive visual elements. In this paper, we analyze the high vision token similarities in LVLMs. We reveal that token similarity distribution condenses as layers deepen while maintaining ranking consistency. Leveraging the unique properties of similarity over importance, we introduce FrameFusion, a novel approach that combines similarity-based merging with importance-based pruning for better token reduction in LVLMs. FrameFusion identifies and merges similar tokens before pruning, opening up a new perspective for token reduction. We evaluate FrameFusion on diverse LVLMs, including Llava-Video-{7B,32B,72B}, and MiniCPM-V-8B, on video understanding, question-answering, and retrieval benchmarks. Experiments show that FrameFusion reduces vision tokens by 70$\%$, achieving 3.4-4.4x LLM speedups and 1.6-1.9x end-to-end speedups, with an average performance impact of less than 3$\%$. Our code is available at https://github.com/thu-nics/FrameFusion.
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Dec 17, 2024



Executing precise and agile flight maneuvers is critical for quadrotors in various applications. Traditional quadrotor control approaches are limited by their reliance on flat trajectories or time-consuming optimization, which restricts their flexibility. Recently, RL-based policy has emerged as a promising alternative due to its ability to directly map observations to actions, reducing the need for detailed system knowledge and actuation constraints. However, a significant challenge remains in bridging the sim-to-real gap, where RL-based policies often experience instability when deployed in real world. In this paper, we investigate key factors for learning robust RL-based control policies that are capable of zero-shot deployment in real-world quadrotors. We identify five critical factors and we develop a PPO-based training framework named SimpleFlight, which integrates these five techniques. We validate the efficacy of SimpleFlight on Crazyflie quadrotor, demonstrating that it achieves more than a 50% reduction in trajectory tracking error compared to state-of-the-art RL baselines, and achieves 70% improvement over the traditional MPC. The policy derived by SimpleFlight consistently excels across both smooth polynominal trajectories and challenging infeasible zigzag trajectories on small thrust-to-weight quadrotors. In contrast, baseline methods struggle with high-speed or infeasible trajectories. To support further research and reproducibility, we integrate SimpleFlight into a GPU-based simulator Omnidrones and provide open-source access to the code and model checkpoints. We hope SimpleFlight will offer valuable insights for advancing RL-based quadrotor control. For more details, visit our project website at https://sites.google.com/view/simpleflight/.
Multi-UAV Pursuit-Evasion with Online Planning in Unknown Environments by Deep Reinforcement Learning
Sep 25, 2024



Multi-UAV pursuit-evasion, where pursuers aim to capture evaders, poses a key challenge for UAV swarm intelligence. Multi-agent reinforcement learning (MARL) has demonstrated potential in modeling cooperative behaviors, but most RL-based approaches remain constrained to simplified simulations with limited dynamics or fixed scenarios. Previous attempts to deploy RL policy to real-world pursuit-evasion are largely restricted to two-dimensional scenarios, such as ground vehicles or UAVs at fixed altitudes. In this paper, we address multi-UAV pursuit-evasion by considering UAV dynamics and physical constraints. We introduce an evader prediction-enhanced network to tackle partial observability in cooperative strategy learning. Additionally, we propose an adaptive environment generator within MARL training, enabling higher exploration efficiency and better policy generalization across diverse scenarios. Simulations show our method significantly outperforms all baselines in challenging scenarios, generalizing to unseen scenarios with a 100% capture rate. Finally, we derive a feasible policy via a two-stage reward refinement and deploy the policy on real quadrotors in a zero-shot manner. To our knowledge, this is the first work to derive and deploy an RL-based policy using collective thrust and body rates control commands for multi-UAV pursuit-evasion in unknown environments. The open-source code and videos are available at https://sites.google.com/view/pursuit-evasion-rl.
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Jul 01, 2024The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8\times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
Jun 21, 2024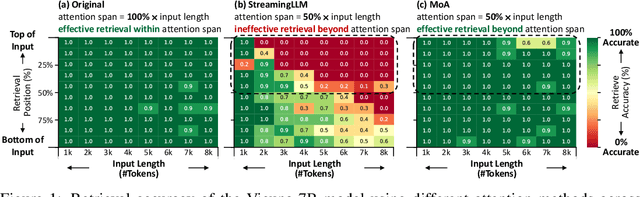
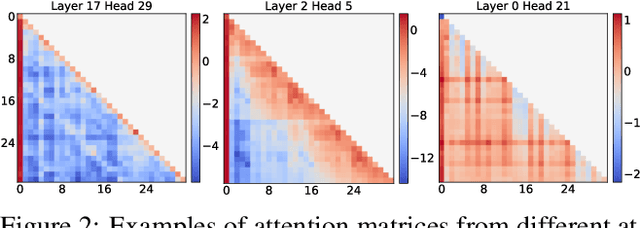

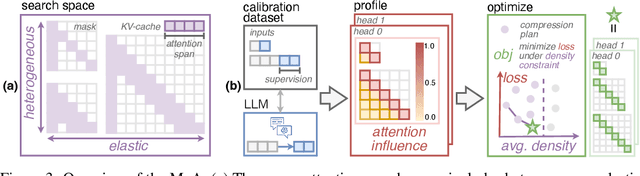
Sparse attention can effectively mitigate the significant memory and throughput demands of Large Language Models (LLMs) in long contexts. Existing methods typically employ a uniform sparse attention mask, applying the same sparse pattern across different attention heads and input lengths. However, this uniform approach fails to capture the diverse attention patterns inherent in LLMs, ignoring their distinct accuracy-latency trade-offs. To address this challenge, we propose the Mixture of Attention (MoA), which automatically tailors distinct sparse attention configurations to different heads and layers. MoA constructs and navigates a search space of various attention patterns and their scaling rules relative to input sequence lengths. It profiles the model, evaluates potential configurations, and pinpoints the optimal sparse attention compression plan. MoA adapts to varying input sizes, revealing that some attention heads expand their focus to accommodate longer sequences, while other heads consistently concentrate on fixed-length local contexts. Experiments show that MoA increases the effective context length by $3.9\times$ with the same average attention span, boosting retrieval accuracy by $1.5-7.1\times$ over the uniform-attention baseline across Vicuna-7B, Vicuna-13B, and Llama3-8B models. Moreover, MoA narrows the capability gaps between sparse and dense models, reducing the maximum relative performance drop from $9\%-36\%$ to within $5\%$ across two long-context understanding benchmarks. MoA achieves a $1.2-1.4\times$ GPU memory reduction and boosts decode throughput by $5.5-6.7 \times$ for 7B and 13B dense models on a single GPU, with minimal impact on performance.