 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Social Intelligence Risks in Generative Multi-Agent Systems
Mar 29, 2026Multi-agent systems composed of large generative models are rapidly moving from laboratory prototypes to real-world deployments, where they jointly plan, negotiate, and allocate shared resources to solve complex tasks. While such systems promise unprecedented scalability and autonomy, their collective interaction also gives rise to failure modes that cannot be reduced to individual agents. Understanding these emergent risks is therefore critical. Here, we present a pioneer study of such emergent multi-agent risk in workflows that involve competition over shared resources (e.g., computing resources or market share), sequential handoff collaboration (where downstream agents see only predecessor outputs), collective decision aggregation, and others. Across these settings, we observe that such group behaviors arise frequently across repeated trials and a wide range of interaction conditions, rather than as rare or pathological cases. In particular, phenomena such as collusion-like coordination and conformity emerge with non-trivial frequency under realistic resource constraints, communication protocols, and role assignments, mirroring well-known pathologies in human societies despite no explicit instruction. Moreover, these risks cannot be prevented by existing agent-level safeguards alone. These findings expose the dark side of intelligent multi-agent systems: a social intelligence risk where agent collectives, despite no instruction to do so, spontaneously reproduce familiar failure patterns from human societies.
CineScene: Implicit 3D as Effective Scene Representation for Cinematic Video Generation
Feb 06, 2026Cinematic video production requires control over scene-subject composition and camera movement, but live-action shooting remains costly due to the need for constructing physical sets. To address this, we introduce the task of cinematic video generation with decoupled scene context: given multiple images of a static environment, the goal is to synthesize high-quality videos featuring dynamic subject while preserving the underlying scene consistency and following a user-specified camera trajectory. We present CineScene, a framework that leverages implicit 3D-aware scene representation for cinematic video generation. Our key innovation is a novel context conditioning mechanism that injects 3D-aware features in an implicit way: By encoding scene images into visual representations through VGGT, CineScene injects spatial priors into a pretrained text-to-video generation model by additional context concatenation, enabling camera-controlled video synthesis with consistent scenes and dynamic subjects. To further enhance the model's robustness, we introduce a simple yet effective random-shuffling strategy for the input scene images during training. To address the lack of training data, we construct a scene-decoupled dataset with Unreal Engine 5, containing paired videos of scenes with and without dynamic subjects, panoramic images representing the underlying static scene, along with their camera trajectories. Experiments show that CineScene achieves state-of-the-art performance in scene-consistent cinematic video generation, handling large camera movements and demonstrating generalization across diverse environments.
From Easy to Hard++: Promoting Differentially Private Image Synthesis Through Spatial-Frequency Curriculum
Jan 10, 2026To improve the quality of Differentially private (DP) synthetic images, most studies have focused on improving the core optimization techniques (e.g., DP-SGD). Recently, we have witnessed a paradigm shift that takes these techniques off the shelf and studies how to use them together to achieve the best results. One notable work is DP-FETA, which proposes using `central images' for `warming up' the DP training and then using traditional DP-SGD. Inspired by DP-FETA, we are curious whether there are other such tools we can use together with DP-SGD. We first observe that using `central images' mainly works for datasets where there are many samples that look similar. To handle scenarios where images could vary significantly, we propose FETA-Pro, which introduces frequency features as `training shortcuts.' The complexity of frequency features lies between that of spatial features (captured by `central images') and full images, allowing for a finer-grained curriculum for DP training. To incorporate these two types of shortcuts together, one challenge is to handle the training discrepancy between spatial and frequency features. To address it, we leverage the pipeline generation property of generative models (instead of having one model trained with multiple features/objectives, we can have multiple models working on different features, then feed the generated results from one model into another) and use a more flexible design. Specifically, FETA-Pro introduces an auxiliary generator to produce images aligned with noisy frequency features. Then, another model is trained with these images, together with spatial features and DP-SGD. Evaluated across five sensitive image datasets, FETA-Pro shows an average of 25.7% higher fidelity and 4.1% greater utility than the best-performing baseline, under a privacy budget $ε= 1$.
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
FilMaster: Bridging Cinematic Principles and Generative AI for Automated Film Generation
Jun 23, 2025AI-driven content creation has shown potential in film production. However, existing film generation systems struggle to implement cinematic principles and thus fail to generate professional-quality films, particularly lacking diverse camera language and cinematic rhythm. This results in templated visuals and unengaging narratives. To address this, we introduce FilMaster, an end-to-end AI system that integrates real-world cinematic principles for professional-grade film generation, yielding editable, industry-standard outputs. FilMaster is built on two key principles: (1) learning cinematography from extensive real-world film data and (2) emulating professional, audience-centric post-production workflows. Inspired by these principles, FilMaster incorporates two stages: a Reference-Guided Generation Stage which transforms user input to video clips, and a Generative Post-Production Stage which transforms raw footage into audiovisual outputs by orchestrating visual and auditory elements for cinematic rhythm. Our generation stage highlights a Multi-shot Synergized RAG Camera Language Design module to guide the AI in generating professional camera language by retrieving reference clips from a vast corpus of 440,000 film clips. Our post-production stage emulates professional workflows by designing an Audience-Centric Cinematic Rhythm Control module, including Rough Cut and Fine Cut processes informed by simulated audience feedback, for effective integration of audiovisual elements to achieve engaging content. The system is empowered by generative AI models like (M)LLMs and video generation models. Furthermore, we introduce FilmEval, a comprehensive benchmark for evaluating AI-generated films. Extensive experiments show FilMaster's superior performance in camera language design and cinematic rhythm control, advancing generative AI in professional filmmaking.
Synthesize Privacy-Preserving High-Resolution Images via Private Textual Intermediaries
Jun 09, 2025



Generating high fidelity, differentially private (DP) synthetic images offers a promising route to share and analyze sensitive visual data without compromising individual privacy. However, existing DP image synthesis methods struggle to produce high resolution outputs that faithfully capture the structure of the original data. In this paper, we introduce a novel method, referred to as Synthesis via Private Textual Intermediaries (SPTI), that can generate high resolution DP images with easy adoption. The key idea is to shift the challenge of DP image synthesis from the image domain to the text domain by leveraging state of the art DP text generation methods. SPTI first summarizes each private image into a concise textual description using image to text models, then applies a modified Private Evolution algorithm to generate DP text, and finally reconstructs images using text to image models. Notably, SPTI requires no model training, only inference with off the shelf models. Given a private dataset, SPTI produces synthetic images of substantially higher quality than prior DP approaches. On the LSUN Bedroom dataset, SPTI attains an FID less than or equal to 26.71 under epsilon equal to 1.0, improving over Private Evolution FID of 40.36. Similarly, on MM CelebA HQ, SPTI achieves an FID less than or equal to 33.27 at epsilon equal to 1.0, compared to 57.01 from DP fine tuning baselines. Overall, our results demonstrate that Synthesis via Private Textual Intermediaries provides a resource efficient and proprietary model compatible framework for generating high resolution DP synthetic images, greatly expanding access to private visual datasets.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
Mar 18, 2025



Differentially private (DP) image synthesis aims to generate artificial images that retain the properties of sensitive images while protecting the privacy of individual images within the dataset. Despite recent advancements, we find that inconsistent--and sometimes flawed--evaluation protocols have been applied across studies. This not only impedes the understanding of current methods but also hinders future advancements. To address the issue, this paper introduces DPImageBench for DP image synthesis, with thoughtful design across several dimensions: (1) Methods. We study eleven prominent methods and systematically characterize each based on model architecture, pretraining strategy, and privacy mechanism. (2) Evaluation. We include nine datasets and seven fidelity and utility metrics to thoroughly assess them. Notably, we find that a common practice of selecting downstream classifiers based on the highest accuracy on the sensitive test set not only violates DP but also overestimates the utility scores. DPImageBench corrects for these mistakes. (3) Platform. Despite the methods and evaluation protocols, DPImageBench provides a standardized interface that accommodates current and future implementations within a unified framework. With DPImageBench, we have several noteworthy findings. For example, contrary to the common wisdom that pretraining on public image datasets is usually beneficial, we find that the distributional similarity between pretraining and sensitive images significantly impacts the performance of the synthetic images and does not always yield improvements. In addition, adding noise to low-dimensional features, such as the high-level characteristics of sensitive images, is less affected by the privacy budget compared to adding noise to high-dimensional features, like weight gradients. The former methods perform better than the latter under a low privacy budget.
Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching
Dec 24, 2024Autoregressive (AR) models have achieved state-of-the-art performance in text and image generation but suffer from slow generation due to the token-by-token process. We ask an ambitious question: can a pre-trained AR model be adapted to generate outputs in just one or two steps? If successful, this would significantly advance the development and deployment of AR models. We notice that existing works that try to speed up AR generation by generating multiple tokens at once fundamentally cannot capture the output distribution due to the conditional dependencies between tokens, limiting their effectiveness for few-step generation. To address this, we propose Distilled Decoding (DD), which uses flow matching to create a deterministic mapping from Gaussian distribution to the output distribution of the pre-trained AR model. We then train a network to distill this mapping, enabling few-step generation. DD doesn't need the training data of the original AR model, making it more practical. We evaluate DD on state-of-the-art image AR models and present promising results on ImageNet-256. For VAR, which requires 10-step generation, DD enables one-step generation (6.3$\times$ speed-up), with an acceptable increase in FID from 4.19 to 9.96. For LlamaGen, DD reduces generation from 256 steps to 1, achieving an 217.8$\times$ speed-up with a comparable FID increase from 4.11 to 11.35. In both cases, baseline methods completely fail with FID>100. DD also excels on text-to-image generation, reducing the generation from 256 steps to 2 for LlamaGen with minimal FID increase from 25.70 to 28.95. As the first work to demonstrate the possibility of one-step generation for image AR models, DD challenges the prevailing notion that AR models are inherently slow, and opens up new opportunities for efficient AR generation. The project website is at https://imagination-research.github.io/distilled-decoding.
GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration
Dec 05, 2024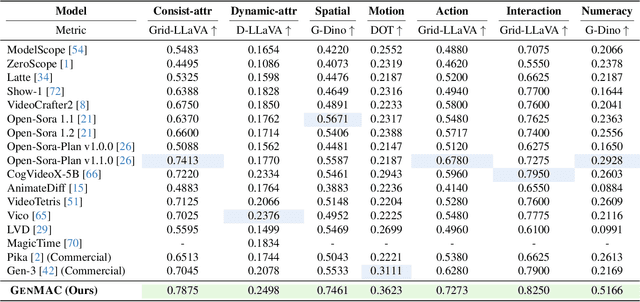
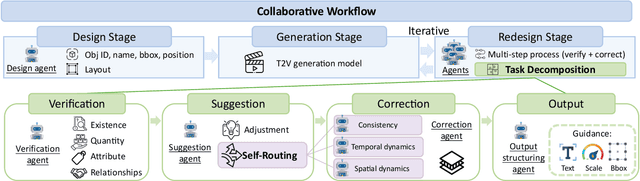
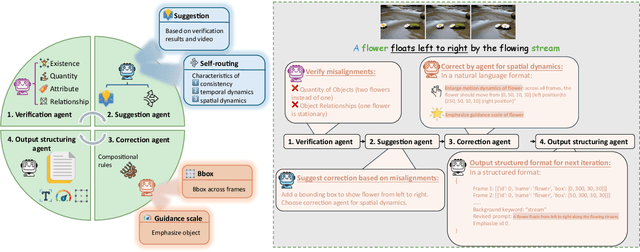

Text-to-video generation models have shown significant progress in the recent years. However, they still struggle with generating complex dynamic scenes based on compositional text prompts, such as attribute binding for multiple objects, temporal dynamics associated with different objects, and interactions between objects. Our key motivation is that complex tasks can be decomposed into simpler ones, each handled by a role-specialized MLLM agent. Multiple agents can collaborate together to achieve collective intelligence for complex goals. We propose GenMAC, an iterative, multi-agent framework that enables compositional text-to-video generation. The collaborative workflow includes three stages: Design, Generation, and Redesign, with an iterative loop between the Generation and Redesign stages to progressively verify and refine the generated videos. The Redesign stage is the most challenging stage that aims to verify the generated videos, suggest corrections, and redesign the text prompts, frame-wise layouts, and guidance scales for the next iteration of generation. To avoid hallucination of a single MLLM agent, we decompose this stage to four sequentially-executed MLLM-based agents: verification agent, suggestion agent, correction agent, and output structuring agent. Furthermore, to tackle diverse scenarios of compositional text-to-video generation, we design a self-routing mechanism to adaptively select the proper correction agent from a collection of correction agents each specialized for one scenario. Extensive experiments demonstrate the effectiveness of GenMAC, achieving state-of-the art performance in compositional text-to-video generation.