 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Easy to Hard++: Promoting Differentially Private Image Synthesis Through Spatial-Frequency Curriculum
Jan 10, 2026To improve the quality of Differentially private (DP) synthetic images, most studies have focused on improving the core optimization techniques (e.g., DP-SGD). Recently, we have witnessed a paradigm shift that takes these techniques off the shelf and studies how to use them together to achieve the best results. One notable work is DP-FETA, which proposes using `central images' for `warming up' the DP training and then using traditional DP-SGD. Inspired by DP-FETA, we are curious whether there are other such tools we can use together with DP-SGD. We first observe that using `central images' mainly works for datasets where there are many samples that look similar. To handle scenarios where images could vary significantly, we propose FETA-Pro, which introduces frequency features as `training shortcuts.' The complexity of frequency features lies between that of spatial features (captured by `central images') and full images, allowing for a finer-grained curriculum for DP training. To incorporate these two types of shortcuts together, one challenge is to handle the training discrepancy between spatial and frequency features. To address it, we leverage the pipeline generation property of generative models (instead of having one model trained with multiple features/objectives, we can have multiple models working on different features, then feed the generated results from one model into another) and use a more flexible design. Specifically, FETA-Pro introduces an auxiliary generator to produce images aligned with noisy frequency features. Then, another model is trained with these images, together with spatial features and DP-SGD. Evaluated across five sensitive image datasets, FETA-Pro shows an average of 25.7% higher fidelity and 4.1% greater utility than the best-performing baseline, under a privacy budget $ε= 1$.
PrivORL: Differentially Private Synthetic Dataset for Offline Reinforcement Learning
Dec 16, 2025Recently, offline reinforcement learning (RL) has become a popular RL paradigm. In offline RL, data providers share pre-collected datasets -- either as individual transitions or sequences of transitions forming trajectories -- to enable the training of RL models (also called agents) without direct interaction with the environments. Offline RL saves interactions with environments compared to traditional RL, and has been effective in critical areas, such as navigation tasks. Meanwhile, concerns about privacy leakage from offline RL datasets have emerged. To safeguard private information in offline RL datasets, we propose the first differential privacy (DP) offline dataset synthesis method, PrivORL, which leverages a diffusion model and diffusion transformer to synthesize transitions and trajectories, respectively, under DP. The synthetic dataset can then be securely released for downstream analysis and research. PrivORL adopts the popular approach of pre-training a synthesizer on public datasets, and then fine-tuning on sensitive datasets using DP Stochastic Gradient Descent (DP-SGD). Additionally, PrivORL introduces curiosity-driven pre-training, which uses feedback from the curiosity module to diversify the synthetic dataset and thus can generate diverse synthetic transitions and trajectories that closely resemble the sensitive dataset. Extensive experiments on five sensitive offline RL datasets show that our method achieves better utility and fidelity in both DP transition and trajectory synthesis compared to baselines. The replication package is available at the GitHub repository.
EnchTable: Unified Safety Alignment Transfer in Fine-tuned Large Language Models
Nov 13, 2025Many machine learning models are fine-tuned from large language models (LLMs) to achieve high performance in specialized domains like code generation, biomedical analysis, and mathematical problem solving. However, this fine-tuning process often introduces a critical vulnerability: the systematic degradation of safety alignment, undermining ethical guidelines and increasing the risk of harmful outputs. Addressing this challenge, we introduce EnchTable, a novel framework designed to transfer and maintain safety alignment in downstream LLMs without requiring extensive retraining. EnchTable leverages a Neural Tangent Kernel (NTK)-based safety vector distillation method to decouple safety constraints from task-specific reasoning, ensuring compatibility across diverse model architectures and sizes. Additionally, our interference-aware merging technique effectively balances safety and utility, minimizing performance compromises across various task domains. We implemented a fully functional prototype of EnchTable on three different task domains and three distinct LLM architectures, and evaluated its performance through extensive experiments on eleven diverse datasets, assessing both utility and model safety. Our evaluations include LLMs from different vendors, demonstrating EnchTable's generalization capability. Furthermore, EnchTable exhibits robust resistance to static and dynamic jailbreaking attacks, outperforming vendor-released safety models in mitigating adversarial prompts. Comparative analyses with six parameter modification methods and two inference-time alignment baselines reveal that EnchTable achieves a significantly lower unsafe rate, higher utility score, and universal applicability across different task domains. Additionally, we validate EnchTable can be seamlessly integrated into various deployment pipelines without significant overhead.
GaussMarker: Robust Dual-Domain Watermark for Diffusion Models
Jun 13, 2025As Diffusion Models (DM) generate increasingly realistic images, related issues such as copyright and misuse have become a growing concern. Watermarking is one of the promising solutions. Existing methods inject the watermark into the single-domain of initial Gaussian noise for generation, which suffers from unsatisfactory robustness. This paper presents the first dual-domain DM watermarking approach using a pipelined injector to consistently embed watermarks in both the spatial and frequency domains. To further boost robustness against certain image manipulations and advanced attacks, we introduce a model-independent learnable Gaussian Noise Restorer (GNR) to refine Gaussian noise extracted from manipulated images and enhance detection robustness by integrating the detection scores of both watermarks. GaussMarker efficiently achieves state-of-the-art performance under eight image distortions and four advanced attacks across three versions of Stable Diffusion with better recall and lower false positive rates, as preferred in real applications.
Dual-Priv Pruning : Efficient Differential Private Fine-Tuning in Multimodal Large Language Models
Jun 08, 2025Differential Privacy (DP) is a widely adopted technique, valued for its effectiveness in protecting the privacy of task-specific datasets, making it a critical tool for large language models. However, its effectiveness in Multimodal Large Language Models (MLLMs) remains uncertain. Applying Differential Privacy (DP) inherently introduces substantial computation overhead, a concern particularly relevant for MLLMs which process extensive textual and visual data. Furthermore, a critical challenge of DP is that the injected noise, necessary for privacy, scales with parameter dimensionality, leading to pronounced model degradation; This trade-off between privacy and utility complicates the application of Differential Privacy (DP) to complex architectures like MLLMs. To address these, we propose Dual-Priv Pruning, a framework that employs two complementary pruning mechanisms for DP fine-tuning in MLLMs: (i) visual token pruning to reduce input dimensionality by removing redundant visual information, and (ii) gradient-update pruning during the DP optimization process. This second mechanism selectively prunes parameter updates based on the magnitude of noisy gradients, aiming to mitigate noise impact and improve utility. Experiments demonstrate that our approach achieves competitive results with minimal performance degradation. In terms of computational efficiency, our approach consistently utilizes less memory than standard DP-SGD. While requiring only 1.74% more memory than zeroth-order methods which suffer from severe performance issues on A100 GPUs, our method demonstrates leading memory efficiency on H20 GPUs. To the best of our knowledge, we are the first to explore DP fine-tuning in MLLMs. Our code is coming soon.
VideoMarkBench: Benchmarking Robustness of Video Watermarking
May 27, 2025The rapid development of video generative models has led to a surge in highly realistic synthetic videos, raising ethical concerns related to disinformation and copyright infringement. Recently, video watermarking has been proposed as a mitigation strategy by embedding invisible marks into AI-generated videos to enable subsequent detection. However, the robustness of existing video watermarking methods against both common and adversarial perturbations remains underexplored. In this work, we introduce VideoMarkBench, the first systematic benchmark designed to evaluate the robustness of video watermarks under watermark removal and watermark forgery attacks. Our study encompasses a unified dataset generated by three state-of-the-art video generative models, across three video styles, incorporating four watermarking methods and seven aggregation strategies used during detection. We comprehensively evaluate 12 types of perturbations under white-box, black-box, and no-box threat models. Our findings reveal significant vulnerabilities in current watermarking approaches and highlight the urgent need for more robust solutions. Our code is available at https://github.com/zhengyuan-jiang/VideoMarkBench.
From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis
Apr 02, 2025

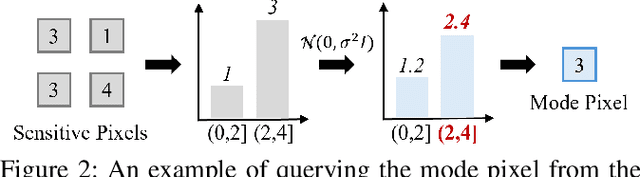

Differentially private (DP) image synthesis aims to generate synthetic images from a sensitive dataset, alleviating the privacy leakage concerns of organizations sharing and utilizing synthetic images. Although previous methods have significantly progressed, especially in training diffusion models on sensitive images with DP Stochastic Gradient Descent (DP-SGD), they still suffer from unsatisfactory performance. In this work, inspired by curriculum learning, we propose a two-stage DP image synthesis framework, where diffusion models learn to generate DP synthetic images from easy to hard. Unlike existing methods that directly use DP-SGD to train diffusion models, we propose an easy stage in the beginning, where diffusion models learn simple features of the sensitive images. To facilitate this easy stage, we propose to use `central images', simply aggregations of random samples of the sensitive dataset. Intuitively, although those central images do not show details, they demonstrate useful characteristics of all images and only incur minimal privacy costs, thus helping early-phase model training. We conduct experiments to present that on the average of four investigated image datasets, the fidelity and utility metrics of our synthetic images are 33.1% and 2.1% better than the state-of-the-art method.
DPImageBench: A Unified Benchmark for Differentially Private Image Synthesis
Mar 18, 2025



Differentially private (DP) image synthesis aims to generate artificial images that retain the properties of sensitive images while protecting the privacy of individual images within the dataset. Despite recent advancements, we find that inconsistent--and sometimes flawed--evaluation protocols have been applied across studies. This not only impedes the understanding of current methods but also hinders future advancements. To address the issue, this paper introduces DPImageBench for DP image synthesis, with thoughtful design across several dimensions: (1) Methods. We study eleven prominent methods and systematically characterize each based on model architecture, pretraining strategy, and privacy mechanism. (2) Evaluation. We include nine datasets and seven fidelity and utility metrics to thoroughly assess them. Notably, we find that a common practice of selecting downstream classifiers based on the highest accuracy on the sensitive test set not only violates DP but also overestimates the utility scores. DPImageBench corrects for these mistakes. (3) Platform. Despite the methods and evaluation protocols, DPImageBench provides a standardized interface that accommodates current and future implementations within a unified framework. With DPImageBench, we have several noteworthy findings. For example, contrary to the common wisdom that pretraining on public image datasets is usually beneficial, we find that the distributional similarity between pretraining and sensitive images significantly impacts the performance of the synthetic images and does not always yield improvements. In addition, adding noise to low-dimensional features, such as the high-level characteristics of sensitive images, is less affected by the privacy budget compared to adding noise to high-dimensional features, like weight gradients. The former methods perform better than the latter under a low privacy budget.
DAS3D: Dual-modality Anomaly Synthesis for 3D Anomaly Detection
Oct 13, 2024



Synthesizing anomaly samples has proven to be an effective strategy for self-supervised 2D industrial anomaly detection. However, this approach has been rarely explored in multi-modality anomaly detection, particularly involving 3D and RGB images. In this paper, we propose a novel dual-modality augmentation method for 3D anomaly synthesis, which is simple and capable of mimicking the characteristics of 3D defects. Incorporating with our anomaly synthesis method, we introduce a reconstruction-based discriminative anomaly detection network, in which a dual-modal discriminator is employed to fuse the original and reconstructed embedding of two modalities for anomaly detection. Additionally, we design an augmentation dropout mechanism to enhance the generalizability of the discriminator. Extensive experiments show that our method outperforms the state-of-the-art methods on detection precision and achieves competitive segmentation performance on both MVTec 3D-AD and Eyescandies datasets.
TrajDeleter: Enabling Trajectory Forgetting in Offline Reinforcement Learning Agents
Apr 18, 2024



Reinforcement learning (RL) trains an agent from experiences interacting with the environment. In scenarios where online interactions are impractical, offline RL, which trains the agent using pre-collected datasets, has become popular. While this new paradigm presents remarkable effectiveness across various real-world domains, like healthcare and energy management, there is a growing demand to enable agents to rapidly and completely eliminate the influence of specific trajectories from both the training dataset and the trained agents. To meet this problem, this paper advocates Trajdeleter, the first practical approach to trajectory unlearning for offline RL agents. The key idea of Trajdeleter is to guide the agent to demonstrate deteriorating performance when it encounters states associated with unlearning trajectories. Simultaneously, it ensures the agent maintains its original performance level when facing other remaining trajectories. Additionally, we introduce Trajauditor, a simple yet efficient method to evaluate whether Trajdeleter successfully eliminates the specific trajectories of influence from the offline RL agent. Extensive experiments conducted on six offline RL algorithms and three tasks demonstrate that Trajdeleter requires only about 1.5% of the time needed for retraining from scratch. It effectively unlearns an average of 94.8% of the targeted trajectories yet still performs well in actual environment interactions after unlearning. The replication package and agent parameters are available online.