 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation VAEs for 3D CT Reconstruction, Augmentation, and Generation
May 29, 2026Variational autoencoders (VAEs) compress high resolution CT volumes into compact latents while preserving clinically relevant structure. However, training CT-specific VAEs from scratch or heavily fine-tuning them incurs substantial computational and engineering cost, and often degrades under heterogeneous scanners, protocols, and diseases. This paper makes a progressive stride toward training-free medical VAEs by leveraging a critical observation: a single Foundation VAE, pretrained at scale on natural images and videos, can serve as a unified interface for CT Reconstruction, Augmentation, and Generation. With both encoder and decoder frozen, the Foundation VAE reconstructs CT volumes with preserved anatomy while suppressing acquisition noise; training segmentation models on these reconstructions improves surface accuracy by 3.9% NSD on average for pancreatic tumor and lung tumor. Within the same Foundation VAE latent space, a conditional latent diffusion model achieves 3.9% lower average FVD with 36.2% higher CT CLIP score, and improves multi-disease generation faithfulness across 18 types by 2.76% AUC. These results demonstrate Foundation VAEs as a practical interface for scalable CT representation reuse and faithful CT generation. Our code and demo are available at https://github.com/qic999/Foundation-VAE.
GEAR: Granularity-Adaptive Advantage Reweighting for LLM Agents via Self-Distillation
May 14, 2026Reinforcement learning has become a widely used post-training approach for LLM agents, where training commonly relies on outcome-level rewards that provide only coarse supervision. While finer-grained credit assignment is promising for effective policy updates, obtaining reliable local credit and assigning it to the right parts of the long-horizon trajectory remains an open challenge. In this paper, we propose Granularity-adaptivE Advantage Reweighting (GEAR), an adaptive-granularity credit assignment framework that reshapes the trajectory-level GRPO advantage using token- and segment-level signals derived from self-distillation. GEAR compares an on-policy student with a ground-truth-conditioned teacher to obtain a reference-guided divergence signal for identifying adaptive segment boundaries and modulating local advantage weights. This divergence often spikes at the onset of a semantic deviation, while later tokens in the same autoregressive continuation may return to low divergence. GEAR therefore treats such spikes as anchors for adaptive credit regions: where the student remains aligned with the teacher, token-level resolution is preserved; where it departs, GEAR groups the corresponding continuation into an adaptive segment and uses the divergence at the departure point to modulate the segment' s advantage. Experiments across eight mathematical reasoning and agentic tool-use benchmarks with Qwen3 4B and 8B models show that GEAR consistently outperforms standard GRPO, self-distillation-only baselines, and token- or turn-level credit-assignment methods. The gains are especially strong on benchmarks with lower GRPO baseline accuracy, reaching up to around 20\% over GRPO, suggesting that the proposed adaptive reweighting scheme is especially useful in more challenging long-horizon settings.
What to Ignore, What to React: Visually Robust RL Fine-Tuning of VLA Models
May 13, 2026Reinforcement learning (RL) fine-tuning has shown promise for Vision-Language-Action (VLA) models in robotic manipulation, but deployment-time visual shifts pose practical challenges. A key difficulty is that standard task rewards supervise task success, but offer limited guidance on whether a visual change is task-irrelevant or changes the behavior required for manipulation. We propose PAIR-VLA (Paired Action Invariance & Sensitivity for Visually Robust VLA), an RL fine-tuning framework to address this difficulty by adding two auxiliary objectives over paired visual variants during PPO optimization: an invariance term that reduces the discrepancy between action distributions for a task-preserving pair (e.g., different distractors), and a sensitivity objective that encourages separable action distributions for a task-altering pair (e.g., target object in a different pose). Together, these objectives turn visual variants from mere observation diversity into behavior-level guidance on policy responses during RL fine-tuning. We evaluate on ManiSkill3 across two representative VLA architectures, OpenVLA and $π_{0.5}$, under diverse out-of-distribution visual shifts including unseen distractors, texture changes, target object pose variation, viewpoint shifts, and lighting changes. Our method consistently improves over standard PPO, achieving average improvements of 16.62% on $π_{0.5}$ and 9.10% on OpenVLA. Notably, ablations further show generalization across visual shifts: invariance guidance learned from distractor and texture variants transfers to target-pose and lighting shifts, while adding sensitivity guidance on target-pose variants further improves robustness to nuisance shifts, highlighting the broader transferability of behavior-level RL guidance.
See Less, See Right: Bi-directional Perceptual Shaping For Multimodal Reasoning
Dec 26, 2025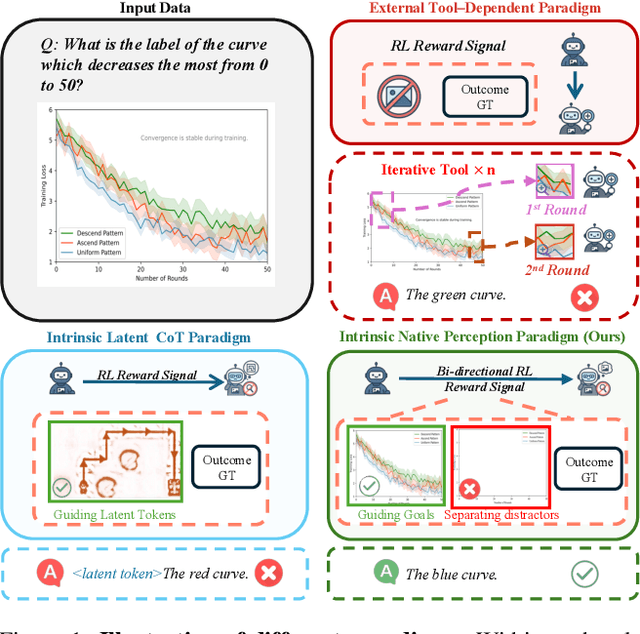

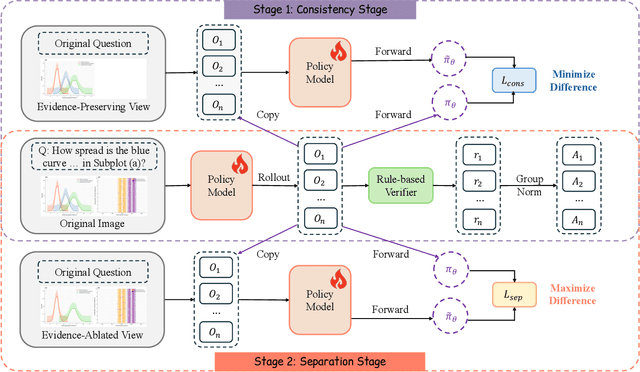
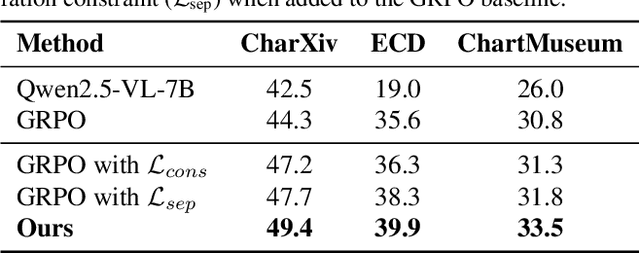
Large vision-language models (VLMs) often benefit from intermediate visual cues, either injected via external tools or generated as latent visual tokens during reasoning, but these mechanisms still overlook fine-grained visual evidence (e.g., polylines in charts), generalize poorly across domains, and incur high inference-time cost. In this paper, we propose Bi-directional Perceptual Shaping (BiPS), which transforms question-conditioned masked views into bidirectional where-to-look signals that shape perception during training. BiPS first applies a KL-consistency constraint between the original image and an evidence-preserving view that keeps only question-relevant regions, encouraging coarse but complete coverage of supporting pixels. It then applies a KL-separation constraint between the original and an evidence-ablated view where critical pixels are masked so the image no longer supports the original answer, discouraging text-only shortcuts (i.e., answering from text alone) and enforcing fine-grained visual reliance. Across eight benchmarks, BiPS boosts Qwen2.5-VL-7B by 8.2% on average and shows strong out-of-domain generalization to unseen datasets and image types.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
AURAD: Anatomy-Pathology Unified Radiology Synthesis with Progressive Representations
Sep 05, 2025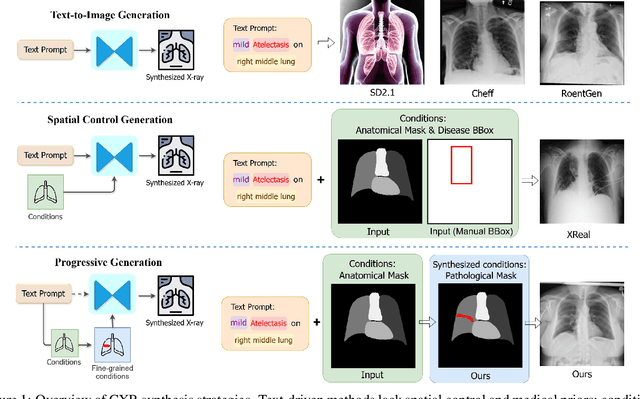

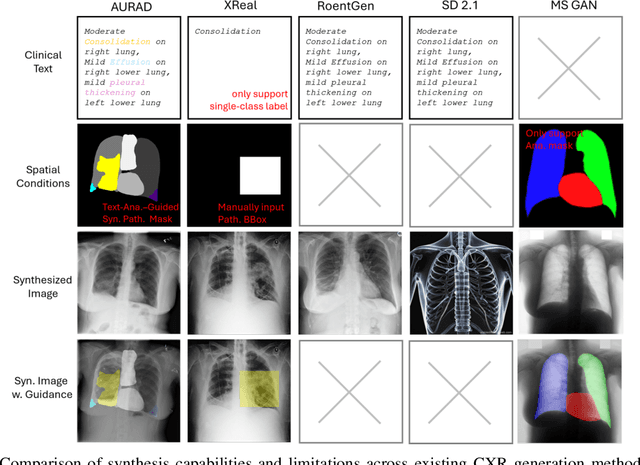
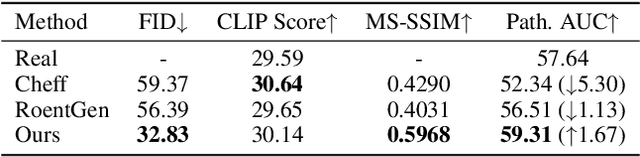
Medical image synthesis has become an essential strategy for augmenting datasets and improving model generalization in data-scarce clinical settings. However, fine-grained and controllable synthesis remains difficult due to limited high-quality annotations and domain shifts across datasets. Existing methods, often designed for natural images or well-defined tumors, struggle to generalize to chest radiographs, where disease patterns are morphologically diverse and tightly intertwined with anatomical structures. To address these challenges, we propose AURAD, a controllable radiology synthesis framework that jointly generates high-fidelity chest X-rays and pseudo semantic masks. Unlike prior approaches that rely on randomly sampled masks-limiting diversity, controllability, and clinical relevance-our method learns to generate masks that capture multi-pathology coexistence and anatomical-pathological consistency. It follows a progressive pipeline: pseudo masks are first generated from clinical prompts conditioned on anatomical structures, and then used to guide image synthesis. We also leverage pretrained expert medical models to filter outputs and ensure clinical plausibility. Beyond visual realism, the synthesized masks also serve as labels for downstream tasks such as detection and segmentation, bridging the gap between generative modeling and real-world clinical applications. Extensive experiments and blinded radiologist evaluations demonstrate the effectiveness and generalizability of our method across tasks and datasets. In particular, 78% of our synthesized images are classified as authentic by board-certified radiologists, and over 40% of predicted segmentation overlays are rated as clinically useful. All code, pre-trained models, and the synthesized dataset will be released upon publication.
OMGM: Orchestrate Multiple Granularities and Modalities for Efficient Multimodal Retrieval
May 10, 2025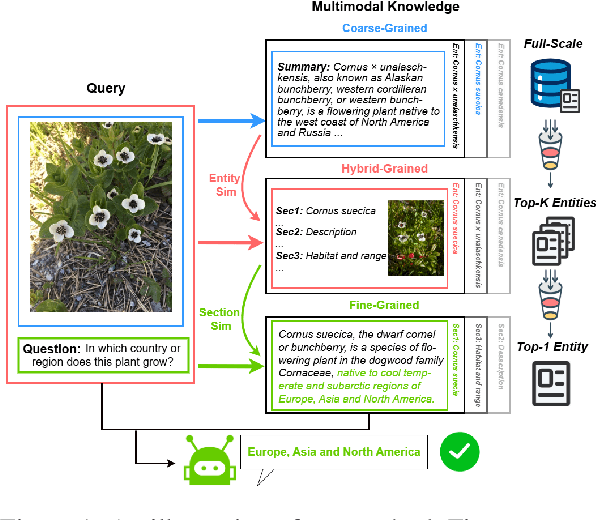
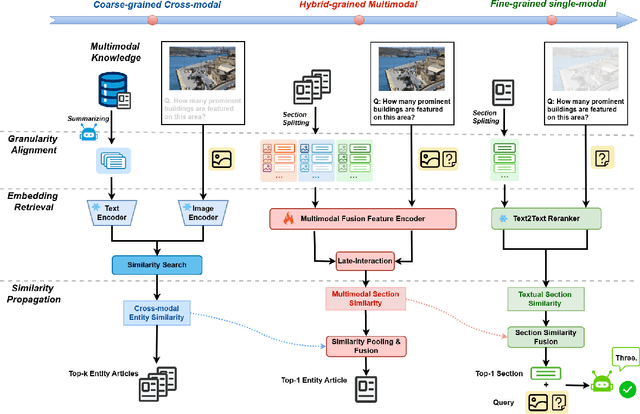
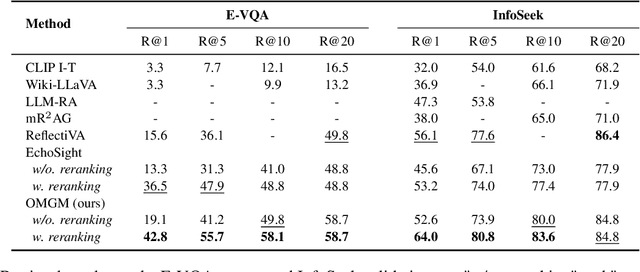
Vision-language retrieval-augmented generation (RAG) has become an effective approach for tackling Knowledge-Based Visual Question Answering (KB-VQA), which requires external knowledge beyond the visual content presented in images. The effectiveness of Vision-language RAG systems hinges on multimodal retrieval, which is inherently challenging due to the diverse modalities and knowledge granularities in both queries and knowledge bases. Existing methods have not fully tapped into the potential interplay between these elements. We propose a multimodal RAG system featuring a coarse-to-fine, multi-step retrieval that harmonizes multiple granularities and modalities to enhance efficacy. Our system begins with a broad initial search aligning knowledge granularity for cross-modal retrieval, followed by a multimodal fusion reranking to capture the nuanced multimodal information for top entity selection. A text reranker then filters out the most relevant fine-grained section for augmented generation. Extensive experiments on the InfoSeek and Encyclopedic-VQA benchmarks show our method achieves state-of-the-art retrieval performance and highly competitive answering results, underscoring its effectiveness in advancing KB-VQA systems.
Chain of Functions: A Programmatic Pipeline for Fine-Grained Chart Reasoning Data
Mar 20, 2025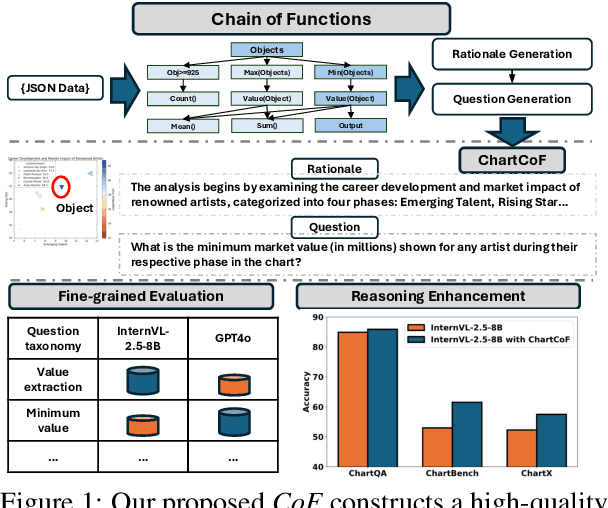

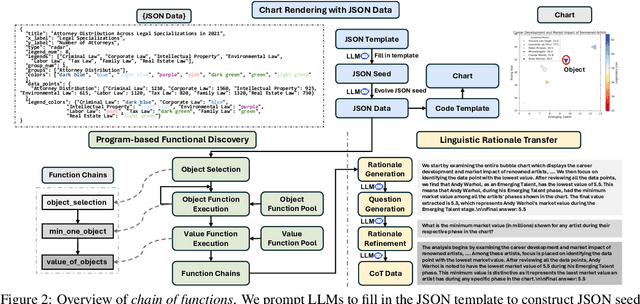
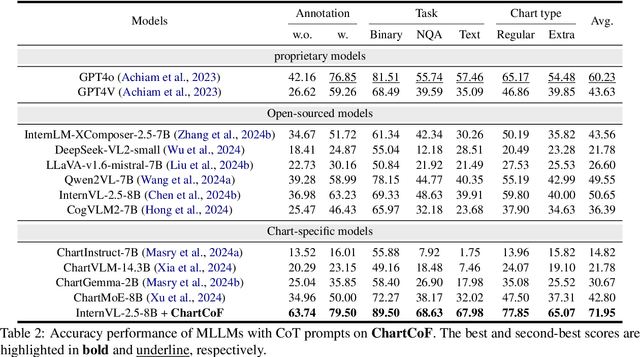
Visual reasoning is crucial for multimodal large language models (MLLMs) to address complex chart queries, yet high-quality rationale data remains scarce. Existing methods leveraged (M)LLMs for data generation, but direct prompting often yields limited precision and diversity. In this paper, we propose \textit{Chain of Functions (CoF)}, a novel programmatic reasoning data generation pipeline that utilizes freely-explored reasoning paths as supervision to ensure data precision and diversity. Specifically, it starts with human-free exploration among the atomic functions (e.g., maximum data and arithmetic operations) to generate diverse function chains, which are then translated into linguistic rationales and questions with only a moderate open-sourced LLM. \textit{CoF} provides multiple benefits: 1) Precision: function-governed generation reduces hallucinations compared to freeform generation; 2) Diversity: enumerating function chains enables varied question taxonomies; 3) Explainability: function chains serve as built-in rationales, allowing fine-grained evaluation beyond overall accuracy; 4) Practicality: eliminating reliance on extremely large models. Employing \textit{CoF}, we construct the \textit{ChartCoF} dataset, with 1.4k complex reasoning Q\&A for fine-grained analysis and 50k Q\&A for reasoning enhancement. The fine-grained evaluation on \textit{ChartCoF} reveals varying performance across question taxonomies for each MLLM, and the experiments also show that finetuning with \textit{ChartCoF} achieves state-of-the-art performance among same-scale MLLMs on widely used benchmarks. Furthermore, the novel paradigm of function-governed rationale generation in \textit{CoF} could inspire broader applications beyond charts.
PIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation
Jan 20, 2025

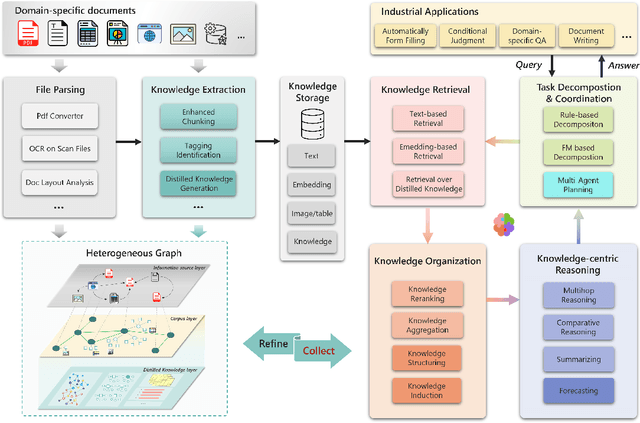
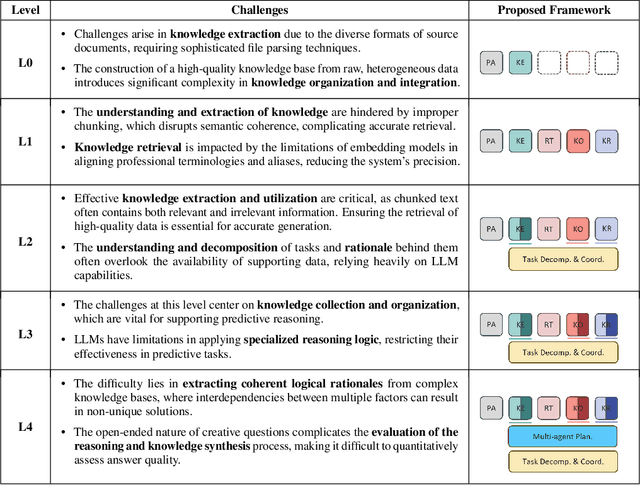
Despite notable advancements in Retrieval-Augmented Generation (RAG) systems that expand large language model (LLM) capabilities through external retrieval, these systems often struggle to meet the complex and diverse needs of real-world industrial applications. The reliance on retrieval alone proves insufficient for extracting deep, domain-specific knowledge performing in logical reasoning from specialized corpora. To address this, we introduce sPecIalized KnowledgE and Rationale Augmentation Generation (PIKE-RAG), focusing on extracting, understanding, and applying specialized knowledge, while constructing coherent rationale to incrementally steer LLMs toward accurate responses. Recognizing the diverse challenges of industrial tasks, we introduce a new paradigm that classifies tasks based on their complexity in knowledge extraction and application, allowing for a systematic evaluation of RAG systems' problem-solving capabilities. This strategic approach offers a roadmap for the phased development and enhancement of RAG systems, tailored to meet the evolving demands of industrial applications. Furthermore, we propose knowledge atomizing and knowledge-aware task decomposition to effectively extract multifaceted knowledge from the data chunks and iteratively construct the rationale based on original query and the accumulated knowledge, respectively, showcasing exceptional performance across various benchmarks.
DAS3D: Dual-modality Anomaly Synthesis for 3D Anomaly Detection
Oct 13, 2024



Synthesizing anomaly samples has proven to be an effective strategy for self-supervised 2D industrial anomaly detection. However, this approach has been rarely explored in multi-modality anomaly detection, particularly involving 3D and RGB images. In this paper, we propose a novel dual-modality augmentation method for 3D anomaly synthesis, which is simple and capable of mimicking the characteristics of 3D defects. Incorporating with our anomaly synthesis method, we introduce a reconstruction-based discriminative anomaly detection network, in which a dual-modal discriminator is employed to fuse the original and reconstructed embedding of two modalities for anomaly detection. Additionally, we design an augmentation dropout mechanism to enhance the generalizability of the discriminator. Extensive experiments show that our method outperforms the state-of-the-art methods on detection precision and achieves competitive segmentation performance on both MVTec 3D-AD and Eyescandies datasets.