 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Drift Resister for Non-Exemplar Continual Graph Learning
Apr 03, 2026Non-Exemplar Continual Graph Learning (NECGL) seeks to eliminate the privacy risks intrinsic to rehearsal-based paradigms by retaining solely class-level prototype representations rather than raw graph examples for mitigating catastrophic forgetting. However, this design choice inevitably precipitates feature drift. As a nascent alternative, Analytic Continual Learning (ACL) capitalizes on the intrinsic generalization properties of frozen pre-trained models to bolster continual learning performance. Nonetheless, a key drawback resides in the pronounced attenuation of model plasticity. To surmount these challenges, we propose Analytic Drift Resister (ADR), a novel and theoretically grounded NECGL framework. ADR exploits iterative backpropagation to break free from the frozen pre-trained constraint, adapting to evolving task graph distributions and fortifying model plasticity. Since parameter updates trigger feature drift, we further propose Hierarchical Analytic Merging (HAM), performing layer-wise merging of linear transformations in Graph Neural Networks (GNNs) via ridge regression, thereby ensuring absolute resistance to feature drift. On this basis, Analytic Classifier Reconstruction (ACR) enables theoretically zero-forgetting class-incremental learning. Empirical evaluation on four node classification benchmarks demonstrates that ADR maintains strong competitiveness against existing state-of-the-art methods.
RC-GRPO: Reward-Conditioned Group Relative Policy Optimization for Multi-Turn Tool Calling Agents
Feb 03, 2026Multi-turn tool calling is challenging for Large Language Models (LLMs) because rewards are sparse and exploration is expensive. A common recipe, SFT followed by GRPO, can stall when within-group reward variation is low (e.g., more rollouts in a group receive the all 0 or all 1 reward), making the group-normalized advantage uninformative and yielding vanishing updates. To address this problem, we propose RC-GRPO (Reward-Conditioned Group Relative Policy Optimization), which treats exploration as a controllable steering problem via discrete reward tokens. We first fine-tune a Reward-Conditioned Trajectory Policy (RCTP) on mixed-quality trajectories with reward goal special tokens (e.g., <|high_reward|>, <|low_reward|>) injected into the prompts, enabling the model to learn how to generate distinct quality trajectories on demand. Then during RL, we sample diverse reward tokens within each GRPO group and condition rollouts on the sampled token to improve within-group diversity, improving advantage gains. On the Berkeley Function Calling Leaderboard v4 (BFCLv4) multi-turn benchmark, our method yields consistently improved performance than baselines, and the performance on Qwen-2.5-7B-Instruct even surpasses all closed-source API models.
See Less, See Right: Bi-directional Perceptual Shaping For Multimodal Reasoning
Dec 26, 2025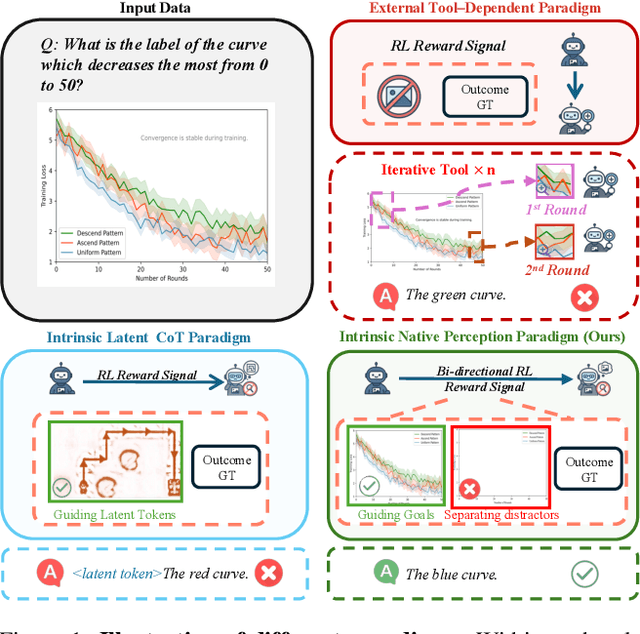

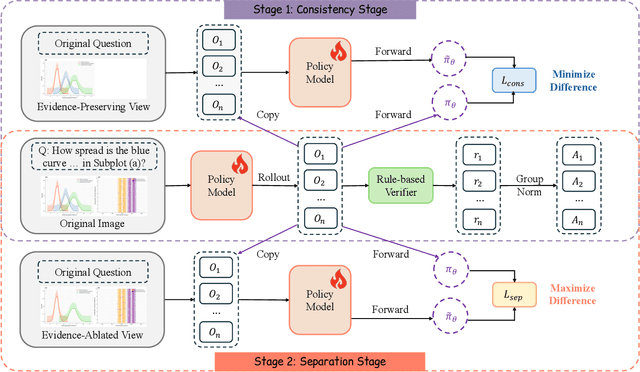
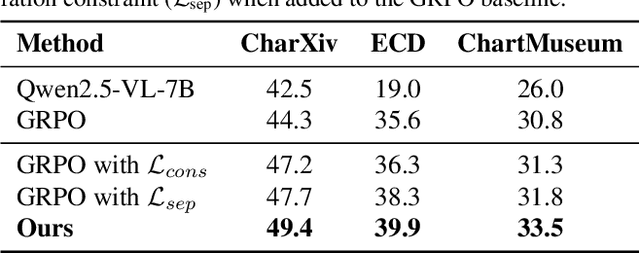
Large vision-language models (VLMs) often benefit from intermediate visual cues, either injected via external tools or generated as latent visual tokens during reasoning, but these mechanisms still overlook fine-grained visual evidence (e.g., polylines in charts), generalize poorly across domains, and incur high inference-time cost. In this paper, we propose Bi-directional Perceptual Shaping (BiPS), which transforms question-conditioned masked views into bidirectional where-to-look signals that shape perception during training. BiPS first applies a KL-consistency constraint between the original image and an evidence-preserving view that keeps only question-relevant regions, encouraging coarse but complete coverage of supporting pixels. It then applies a KL-separation constraint between the original and an evidence-ablated view where critical pixels are masked so the image no longer supports the original answer, discouraging text-only shortcuts (i.e., answering from text alone) and enforcing fine-grained visual reliance. Across eight benchmarks, BiPS boosts Qwen2.5-VL-7B by 8.2% on average and shows strong out-of-domain generalization to unseen datasets and image types.
SIT-Graph: State Integrated Tool Graph for Multi-Turn Agents
Dec 08, 2025Despite impressive advances in agent systems, multi-turn tool-use scenarios remain challenging. It is mainly because intent is clarified progressively and the environment evolves with each tool call. While reusing past experience is natural, current LLM agents either treat entire trajectories or pre-defined subtasks as indivisible units, or solely exploit tool-to-tool dependencies, hindering adaptation as states and information evolve across turns. In this paper, we propose a State Integrated Tool Graph (SIT-Graph), which enhances multi-turn tool use by exploiting partially overlapping experience. Inspired by human decision-making that integrates episodic and procedural memory, SIT-Graph captures both compact state representations (episodic-like fragments) and tool-to-tool dependencies (procedural-like routines) from historical trajectories. Specifically, we first build a tool graph from accumulated tool-use sequences, and then augment each edge with a compact state summary of the dialog and tool history that may shape the next action. At inference time, SIT-Graph enables a human-like balance between episodic recall and procedural execution: when the next decision requires recalling prior context, the agent retrieves the state summaries stored on relevant edges and uses them to guide its next action; when the step is routine, it follows high-confidence tool dependencies without explicit recall. Experiments across multiple stateful multi-turn tool-use benchmarks show that SIT-Graph consistently outperforms strong memory- and graph-based baselines, delivering more robust tool selection and more effective experience transfer.
Holdout-Loss-Based Data Selection for LLM Finetuning via In-Context Learning
Oct 16, 2025Fine-tuning large pretrained language models is a common approach for aligning them with human preferences, but noisy or off-target examples can dilute supervision. While small, well-chosen datasets often match the performance of much larger ones, systematic and efficient ways to identify high-value training data remain underexplored. Many current methods rely on heuristics or expensive retraining. We present a theoretically grounded, resource-efficient framework for data selection and reweighting. At its core is an In-Context Approximation (ICA) that estimates the holdout loss a model would incur after training on a candidate example by conditioning on a small, curated holdout set in context. ICA requires no reference model and no additional finetuning. Under a local linearization, ICA is equivalent to a first-order update toward the holdout optimum, motivating its use as a proxy for data value. We derive per-example weights from ICA scores, dynamically reweighting gradient updates as model parameters evolve. Across SFT, DPO, and SimPO, and over diverse backbones and datasets, ICA-based reweighting consistently improves model alignment with minimal overhead. We analyze sensitivity to score update frequency and the choice of $k$ holdout examples for in-context demonstrations, and note limitations for rapidly drifting on-policy updates, highlighting directions for future work. Code and prompts will be released.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Sample-efficient LLM Optimization with Reset Replay
Aug 08, 2025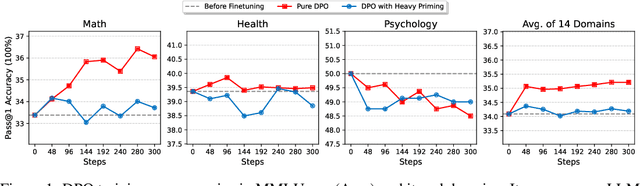
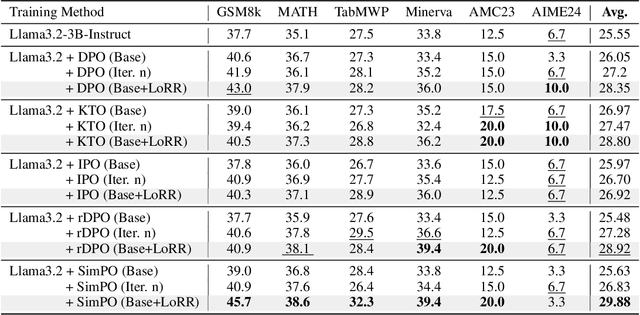
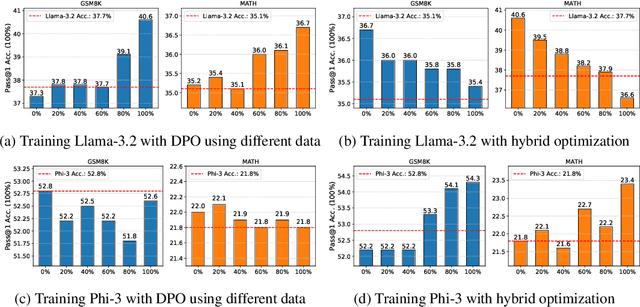
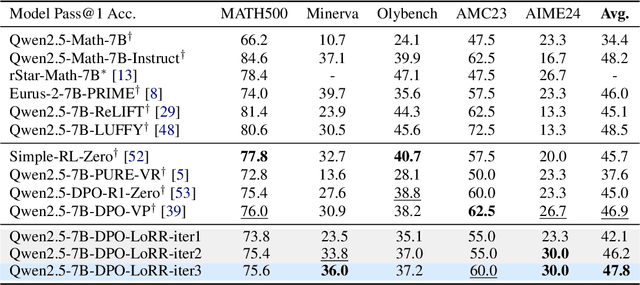
Recent advancements in post-training Large Language Models (LLMs), particularly through Reinforcement Learning (RL) and preference optimization methods, are key drivers for enhancing their reasoning capabilities. However, these methods are often plagued by low sample efficiency and a susceptibility to primacy bias, where overfitting to initial experiences degrades policy quality and damages the learning process. To address these challenges, we introduce LLM optimization with Reset Replay (LoRR), a general and powerful plugin designed to enhance sample efficiency in any preference-based optimization framework. LoRR core mechanism enables training at a high replay number, maximizing the utility of each collected data batch. To counteract the risk of overfitting inherent in high-replay training, LoRR incorporates a periodic reset strategy with reusing initial data, which preserves network plasticity. Furthermore, it leverages a hybrid optimization objective, combining supervised fine-tuning (SFT) and preference-based losses to further bolster data exploitation. Our extensive experiments demonstrate that LoRR significantly boosts the performance of various preference optimization methods on both mathematical and general reasoning benchmarks. Notably, an iterative DPO approach augmented with LoRR achieves comparable performance on challenging math tasks, outperforming some complex and computationally intensive RL-based algorithms. These findings highlight that LoRR offers a practical, sample-efficient, and highly effective paradigm for LLM finetuning, unlocking greater performance from limited data.
HeurAgenix: Leveraging LLMs for Solving Complex Combinatorial Optimization Challenges
Jun 18, 2025Heuristic algorithms play a vital role in solving combinatorial optimization (CO) problems, yet traditional designs depend heavily on manual expertise and struggle to generalize across diverse instances. We introduce \textbf{HeurAgenix}, a two-stage hyper-heuristic framework powered by large language models (LLMs) that first evolves heuristics and then selects among them automatically. In the heuristic evolution phase, HeurAgenix leverages an LLM to compare seed heuristic solutions with higher-quality solutions and extract reusable evolution strategies. During problem solving, it dynamically picks the most promising heuristic for each problem state, guided by the LLM's perception ability. For flexibility, this selector can be either a state-of-the-art LLM or a fine-tuned lightweight model with lower inference cost. To mitigate the scarcity of reliable supervision caused by CO complexity, we fine-tune the lightweight heuristic selector with a dual-reward mechanism that jointly exploits singals from selection preferences and state perception, enabling robust selection under noisy annotations. Extensive experiments on canonical benchmarks show that HeurAgenix not only outperforms existing LLM-based hyper-heuristics but also matches or exceeds specialized solvers. Code is available at https://github.com/microsoft/HeurAgenix.
Learning to Select In-Context Demonstration Preferred by Large Language Model
May 26, 2025In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks during inference using only a few demonstrations. However, ICL performance is highly dependent on the selection of these demonstrations. Recent work explores retrieval-based methods for selecting query-specific demonstrations, but these approaches often rely on surrogate objectives such as metric learning, failing to directly optimize ICL performance. Consequently, they struggle to identify truly beneficial demonstrations. Moreover, their discriminative retrieval paradigm is ineffective when the candidate pool lacks sufficient high-quality demonstrations. To address these challenges, we propose GenICL, a novel generative preference learning framework that leverages LLM feedback to directly optimize demonstration selection for ICL. Experiments on 19 datasets across 11 task categories demonstrate that GenICL achieves superior performance than existing methods in selecting the most effective demonstrations, leading to better ICL performance.
Instance-Prototype Affinity Learning for Non-Exemplar Continual Graph Learning
May 15, 2025Graph Neural Networks (GNN) endure catastrophic forgetting, undermining their capacity to preserve previously acquired knowledge amid the assimilation of novel information. Rehearsal-based techniques revisit historical examples, adopted as a principal strategy to alleviate this phenomenon. However, memory explosion and privacy infringements impose significant constraints on their utility. Non-Exemplar methods circumvent the prior issues through Prototype Replay (PR), yet feature drift presents new challenges. In this paper, our empirical findings reveal that Prototype Contrastive Learning (PCL) exhibits less pronounced drift than conventional PR. Drawing upon PCL, we propose Instance-Prototype Affinity Learning (IPAL), a novel paradigm for Non-Exemplar Continual Graph Learning (NECGL). Exploiting graph structural information, we formulate Topology-Integrated Gaussian Prototypes (TIGP), guiding feature distributions towards high-impact nodes to augment the model's capacity for assimilating new knowledge. Instance-Prototype Affinity Distillation (IPAD) safeguards task memory by regularizing discontinuities in class relationships. Moreover, we embed a Decision Boundary Perception (DBP) mechanism within PCL, fostering greater inter-class discriminability. Evaluations on four node classification benchmark datasets demonstrate that our method outperforms existing state-of-the-art methods, achieving a better trade-off between plasticity and stability.