 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowth First, Care Second? Tracing the Landscape of LLM Value Preferences in Everyday Dilemmas
Feb 04, 2026People increasingly seek advice online from both human peers and large language model (LLM)-based chatbots. Such advice rarely involves identifying a single correct answer; instead, it typically requires navigating trade-offs among competing values. We aim to characterize how LLMs navigate value trade-offs across different advice-seeking contexts. First, we examine the value trade-off structure underlying advice seeking using a curated dataset from four advice-oriented subreddits. Using a bottom-up approach, we inductively construct a hierarchical value framework by aggregating fine-grained values extracted from individual advice options into higher-level value categories. We construct value co-occurrence networks to characterize how values co-occur within dilemmas and find substantial heterogeneity in value trade-off structures across advice-seeking contexts: a women-focused subreddit exhibits the highest network density, indicating more complex value conflicts; women's, men's, and friendship-related subreddits exhibit highly correlated value-conflict patterns centered on security-related tensions (security vs. respect/connection/commitment); by contrast, career advice forms a distinct structure where security frequently clashes with self-actualization and growth. We then evaluate LLM value preferences against these dilemmas and find that, across models and contexts, LLMs consistently prioritize values related to Exploration & Growth over Benevolence & Connection. This systemically skewed value orientation highlights a potential risk of value homogenization in AI-mediated advice, raising concerns about how such systems may shape decision-making and normative outcomes at scale.
Dep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
Standardizing Longitudinal Radiology Report Evaluation via Large Language Model Annotation
Jan 23, 2026Longitudinal information in radiology reports refers to the sequential tracking of findings across multiple examinations over time, which is crucial for monitoring disease progression and guiding clinical decisions. Many recent automated radiology report generation methods are designed to capture longitudinal information; however, validating their performance is challenging. There is no proper tool to consistently label temporal changes in both ground-truth and model-generated texts for meaningful comparisons. Existing annotation methods are typically labor-intensive, relying on the use of manual lexicons and rules. Complex rules are closed-source, domain specific and hard to adapt, whereas overly simple ones tend to miss essential specialised information. Large language models (LLMs) offer a promising annotation alternative, as they are capable of capturing nuanced linguistic patterns and semantic similarities without extensive manual intervention. They also adapt well to new contexts. In this study, we therefore propose an LLM-based pipeline to automatically annotate longitudinal information in radiology reports. The pipeline first identifies sentences containing relevant information and then extracts the progression of diseases. We evaluate and compare five mainstream LLMs on these two tasks using 500 manually annotated reports. Considering both efficiency and performance, Qwen2.5-32B was subsequently selected and used to annotate another 95,169 reports from the public MIMIC-CXR dataset. Our Qwen2.5-32B-annotated dataset provided us with a standardized benchmark for evaluating report generation models. Using this new benchmark, we assessed seven state-of-the-art report generation models. Our LLM-based annotation method outperforms existing annotation solutions, achieving 11.3\% and 5.3\% higher F1-scores for longitudinal information detection and disease tracking, respectively.
Towards Natural Language Environment: Understanding Seamless Natural-Language-Based Human-Multi-Robot Interactions
Jan 19, 2026As multiple robots are expected to coexist in future households, natural language is increasingly envisioned as a primary medium for human-robot and robot-robot communication. This paper introduces the concept of a Natural Language Environment (NLE), defined as an interaction space in which humans and multiple heterogeneous robots coordinate primarily through natural language. Rather than proposing a deployable system, this work aims to explore the design space of such environments. We first synthesize prior work on language-based human-robot interaction to derive a preliminary design space for NLEs. We then conduct a role-playing study in virtual reality to investigate how people conceptualize, negotiate, and coordinate human-multi-robot interactions within this imagined environment. Based on qualitative and quantitative analysis, we refine the preliminary design space and derive design implications that highlight key tensions and opportunities around task coordination dominance, robot autonomy, and robot personality in Natural Language Environments.
BeamCKMDiff: Beam-Aware Channel Knowledge Map Construction via Diffusion Transformer
Jan 15, 2026Channel knowledge map (CKM) is emerging as a critical enabler for environment-aware 6G networks, offering a site-specific database to significantly reduce pilot overhead. However, existing CKM construction methods typically rely on sparse sampling measurements and are restricted to either omnidirectional maps or discrete codebooks, hindering the exploitation of beamforming gain. To address these limitations, we propose BeamCKMDiff, a generative framework for constructing high-fidelity CKMs conditioned on arbitrary continuous beamforming vectors without site-specific sampling. Specifically, we incorporate a novel adaptive layer normalization (adaLN) mechanism into the noise prediction network of the Diffusion Transformer (DiT). This mechanism injects continuous beam embeddings as {global control parameters}, effectively steering the generative process to capture the complex coupling between beam patterns and environmental geometries. Simulation results demonstrate that BeamCKMDiff significantly outperforms state-of-the-art baselines, achieving superior reconstruction accuracy in capturing main lobes and side lobes.
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs
Jan 08, 2026Large Language Models (LLMs) augmented with external tools have demonstrated remarkable capabilities in complex reasoning tasks. However, existing frameworks rely heavily on natural language reasoning to determine when tools can be invoked and whether their results should be committed, lacking formal guarantees for logical safety and verifiability. We present \textbf{ToolGate}, a forward execution framework that provides logical safety guarantees and verifiable state evolution for LLM tool calling. ToolGate maintains an explicit symbolic state space as a typed key-value mapping representing trusted world information throughout the reasoning process. Each tool is formalized as a Hoare-style contract consisting of a precondition and a postcondition, where the precondition gates tool invocation by checking whether the current state satisfies the required conditions, and the postcondition determines whether the tool's result can be committed to update the state through runtime verification. Our approach guarantees that the symbolic state evolves only through verified tool executions, preventing invalid or hallucinated results from corrupting the world representation. Experimental validation demonstrates that ToolGate significantly improves the reliability and verifiability of tool-augmented LLM systems while maintaining competitive performance on complex multi-step reasoning tasks. This work establishes a foundation for building more trustworthy and debuggable AI systems that integrate language models with external tools.
NC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
AffordBot: 3D Fine-grained Embodied Reasoning via Multimodal Large Language Models
Nov 13, 2025
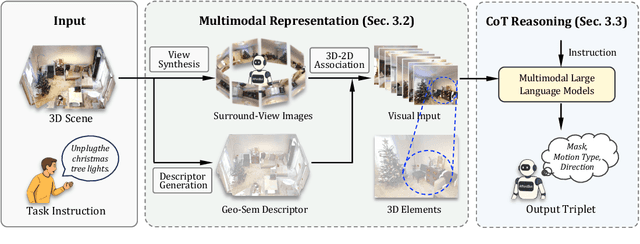


Effective human-agent collaboration in physical environments requires understanding not only what to act upon, but also where the actionable elements are and how to interact with them. Existing approaches often operate at the object level or disjointedly handle fine-grained affordance reasoning, lacking coherent, instruction-driven grounding and reasoning. In this work, we introduce a new task: Fine-grained 3D Embodied Reasoning, which requires an agent to predict, for each referenced affordance element in a 3D scene, a structured triplet comprising its spatial location, motion type, and motion axis, based on a task instruction. To solve this task, we propose AffordBot, a novel framework that integrates Multimodal Large Language Models (MLLMs) with a tailored chain-of-thought (CoT) reasoning paradigm. To bridge the gap between 3D input and 2D-compatible MLLMs, we render surround-view images of the scene and project 3D element candidates into these views, forming a rich visual representation aligned with the scene geometry. Our CoT pipeline begins with an active perception stage, prompting the MLLM to select the most informative viewpoint based on the instruction, before proceeding with step-by-step reasoning to localize affordance elements and infer plausible interaction motions. Evaluated on the SceneFun3D dataset, AffordBot achieves state-of-the-art performance, demonstrating strong generalization and physically grounded reasoning with only 3D point cloud input and MLLMs.
DPRM: A Dual Implicit Process Reward Model in Multi-Hop Question Answering
Nov 11, 2025In multi-hop question answering (MHQA) tasks, Chain of Thought (CoT) improves the quality of generation by guiding large language models (LLMs) through multi-step reasoning, and Knowledge Graphs (KGs) reduce hallucinations via semantic matching. Outcome Reward Models (ORMs) provide feedback after generating the final answers but fail to evaluate the process for multi-step reasoning. Traditional Process Reward Models (PRMs) evaluate the reasoning process but require costly human annotations or rollout generation. While implicit PRM is trained only with outcome signals and derives step rewards through reward parameterization without explicit annotations, it is more suitable for multi-step reasoning in MHQA tasks. However, existing implicit PRM has only been explored for plain text scenarios. When adapting to MHQA tasks, it cannot handle the graph structure constraints in KGs and capture the potential inconsistency between CoT and KG paths. To address these limitations, we propose the DPRM (Dual Implicit Process Reward Model). It trains two implicit PRMs for CoT and KG reasoning in MHQA tasks. Both PRMs, namely KG-PRM and CoT-PRM, derive step-level rewards from outcome signals via reward parameterization without additional explicit annotations. Among them, KG-PRM uses preference pairs to learn structural constraints from KGs. DPRM further introduces a consistency constraint between CoT and KG reasoning steps, making the two PRMs mutually verify and collaboratively optimize the reasoning paths. We also provide a theoretical demonstration of the derivation of process rewards. Experimental results show that our method outperforms 13 baselines on multiple datasets with up to 16.6% improvement on Hit@1.
CAMP-VQA: Caption-Embedded Multimodal Perception for No-Reference Quality Assessment of Compressed Video
Nov 10, 2025The prevalence of user-generated content (UGC) on platforms such as YouTube and TikTok has rendered no-reference (NR) perceptual video quality assessment (VQA) vital for optimizing video delivery. Nonetheless, the characteristics of non-professional acquisition and the subsequent transcoding of UGC video on sharing platforms present significant challenges for NR-VQA. Although NR-VQA models attempt to infer mean opinion scores (MOS), their modeling of subjective scores for compressed content remains limited due to the absence of fine-grained perceptual annotations of artifact types. To address these challenges, we propose CAMP-VQA, a novel NR-VQA framework that exploits the semantic understanding capabilities of large vision-language models. Our approach introduces a quality-aware prompting mechanism that integrates video metadata (e.g., resolution, frame rate, bitrate) with key fragments extracted from inter-frame variations to guide the BLIP-2 pretraining approach in generating fine-grained quality captions. A unified architecture has been designed to model perceptual quality across three dimensions: semantic alignment, temporal characteristics, and spatial characteristics. These multimodal features are extracted and fused, then regressed to video quality scores. Extensive experiments on a wide variety of UGC datasets demonstrate that our model consistently outperforms existing NR-VQA methods, achieving improved accuracy without the need for costly manual fine-grained annotations. Our method achieves the best performance in terms of average rank and linear correlation (SRCC: 0.928, PLCC: 0.938) compared to state-of-the-art methods. The source code and trained models, along with a user-friendly demo, are available at: https://github.com/xinyiW915/CAMP-VQA.