 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore)
May 06, 2026This paper reports on the LoViF 2026 PhyScore challenge, a competition on holistic quality assessment of world-model-generated videos across both 2D and 4D generation settings. The challenge is motivated by a central gap in current evaluation practice: perceptual quality alone is insufficient to judge whether generated dynamics are physically plausible, temporally coherent, and consistent with input conditions. Participants are required to build a metric that jointly predicts four dimensions, i.e., Video Quality, Physical Realism, Condition-Video Alignment, and Temporal Consistency. Depart from that, participants also need to localize physical anomaly timestamps for fine-grained diagnosis. The benchmark dataset contains 1,554 videos generated by seven representative world generative models, organized into three tracks (text-2D, image-to-4D, and video-to-4D) and spanning 26 categories. These categories explicitly cover physics-relevant scenarios, including dynamics, optics, and thermodynamics, together with diverse real-world and creative content. To ensure label reliability, scores and anomaly timestamps are produced through trained human annotation with an additional automated quality-control pass. Evaluation is based on both score prediction and anomaly localization, with a composite protocol that combines TimeStamp_IOU and SRCC/PLCC. This report summarizes the challenge design and provides method-level insights from submitted solutions.
4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
Delving Aleatoric Uncertainty in Medical Image Segmentation via Vision Foundation Models
Apr 13, 2026Medical image segmentation supports clinical workflows by precisely delineating anatomical structures and lesions. However, medical image datasets medical image datasets suffer from acquisition noise and annotation ambiguity, causing pervasive data uncertainty that substantially undermines model robustness. Existing research focuses primarily on model architectural improvements and predictive reliability estimation, while systematic exploration of the intrinsic data uncertainty remains insufficient. To address this gap, this work proposes leveraging the universal representation capabilities of visual foundation models to estimate inherent data uncertainty. Specifically, we analyze the feature diversity of the model's decoded representations and quantify their singular value energy to define the semantic perception scale for each class, thereby measuring sample difficulty and aleatoric uncertainty. Based on this foundation, we design two uncertainty-driven application strategies: (1) the aleatoric uncertainty-aware data filtering mechanism to eliminate potentially noisy samples and enhance model learning quality; (2) the dynamic uncertainty-aware optimization strategy that adaptively adjusts class-specific loss weights during training based on the semantic perception scale, combined with a label denoising mechanism to improve training stability. Experimental results on five public datasets encompassing CT and MRI modalities and involving multi-organ and tumor segmentation tasks demonstrate that our method achieves significant and robust performance improvements across various mainstream network architectures, revealing the broad application potential of aleatoric uncertainty in medical image understanding and segmentation tasks.
Privacy-Concealing Cooperative Perception for BEV Scene Segmentation
Feb 14, 2026Cooperative perception systems for autonomous driving aim to overcome the limited perception range of a single vehicle by communicating with adjacent agents to share sensing information. While this improves perception performance, these systems also face a significant privacy-leakage issue, as sensitive visual content can potentially be reconstructed from the shared data. In this paper, we propose a novel Privacy-Concealing Cooperation (PCC) framework for Bird's Eye View (BEV) semantic segmentation. Based on commonly shared BEV features, we design a hiding network to prevent an image reconstruction network from recovering the input images from the shared features. An adversarial learning mechanism is employed to train the network, where the hiding network works to conceal the visual clues in the BEV features while the reconstruction network attempts to uncover these clues. To maintain segmentation performance, the perception network is integrated with the hiding network and optimized end-to-end. The experimental results demonstrate that the proposed PCC framework effectively degrades the quality of the reconstructed images with minimal impact on segmentation performance, providing privacy protection for cooperating vehicles. The source code will be made publicly available upon publication.
STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning
Feb 12, 2026In vision-language models (VLMs), misalignment between textual descriptions and visual coordinates often induces hallucinations. This issue becomes particularly severe in dense prediction tasks such as spatial-temporal video grounding (STVG). Prior approaches typically focus on enhancing visual-textual alignment or attaching auxiliary decoders. However, these strategies inevitably introduce additional trainable modules, leading to significant annotation costs and computational overhead. In this work, we propose a novel visual prompting paradigm that avoids the difficult problem of aligning coordinates across modalities. Specifically, we reformulate per-frame coordinate prediction as a compact instance-level identification problem by assigning each object a unique, temporally consistent ID. These IDs are embedded into the video as visual prompts, providing explicit and interpretable inputs to the VLMs. Furthermore, we introduce STVG-R1, the first reinforcement learning framework for STVG, which employs a task-driven reward to jointly optimize temporal accuracy, spatial consistency, and structural format regularization. Extensive experiments on six benchmarks demonstrate the effectiveness of our approach. STVG-R1 surpasses the baseline Qwen2.5-VL-7B by a remarkable margin of 20.9% on m_IoU on the HCSTVG-v2 benchmark, establishing a new state of the art (SOTA). Surprisingly, STVG-R1 also exhibits strong zero-shot generalization to multi-object referring video object segmentation tasks, achieving a SOTA 47.3% J&F on MeViS.
Task-free Adaptive Meta Black-box Optimization
Jan 29, 2026Handcrafted optimizers become prohibitively inefficient for complex black-box optimization (BBO) tasks. MetaBBO addresses this challenge by meta-learning to automatically configure optimizers for low-level BBO tasks, thereby eliminating heuristic dependencies. However, existing methods typically require extensive handcrafted training tasks to learn meta-strategies that generalize to target tasks, which poses a critical limitation for realistic applications with unknown task distributions. To overcome the issue, we propose the Adaptive meta Black-box Optimization Model (ABOM), which performs online parameter adaptation using solely optimization data from the target task, obviating the need for predefined task distributions. Unlike conventional metaBBO frameworks that decouple meta-training and optimization phases, ABOM introduces a closed-loop adaptive parameter learning mechanism, where parameterized evolutionary operators continuously self-update by leveraging generated populations during optimization. This paradigm shift enables zero-shot optimization: ABOM achieves competitive performance on synthetic BBO benchmarks and realistic unmanned aerial vehicle path planning problems without any handcrafted training tasks. Visualization studies reveal that parameterized evolutionary operators exhibit statistically significant search patterns, including natural selection and genetic recombination.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
ContextRefine-CLIP for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2025
Jun 12, 2025

This report presents ContextRefine-CLIP (CR-CLIP), an efficient model for visual-textual multi-instance retrieval tasks. The approach is based on the dual-encoder AVION, on which we introduce a cross-modal attention flow module to achieve bidirectional dynamic interaction and refinement between visual and textual features to generate more context-aware joint representations. For soft-label relevance matrices provided in tasks such as EPIC-KITCHENS-100, CR-CLIP can work with Symmetric Multi-Similarity Loss to achieve more accurate semantic alignment and optimization using the refined features. Without using ensemble learning, the CR-CLIP model achieves 66.78mAP and 82.08nDCG on the EPIC-KITCHENS-100 public leaderboard, which significantly outperforms the baseline model and fully validates its effectiveness in cross-modal retrieval. The code will be released open-source on https://github.com/delCayr/ContextRefine-Clip
Logits DeConfusion with CLIP for Few-Shot Learning
Apr 16, 2025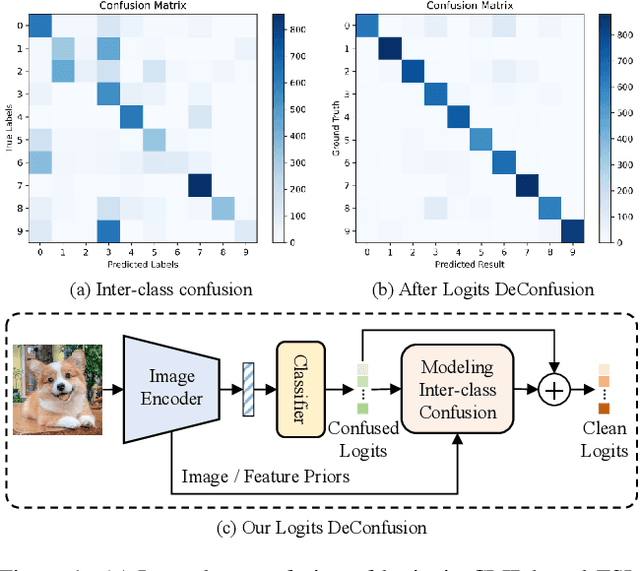
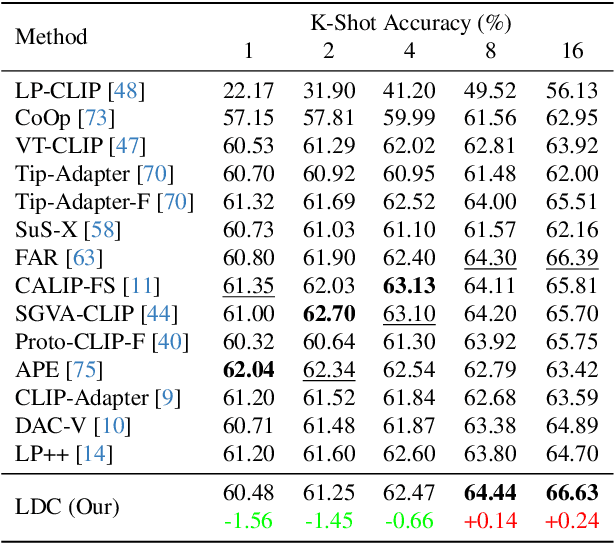
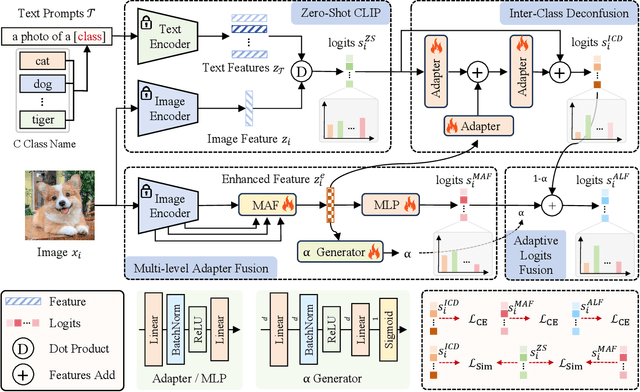
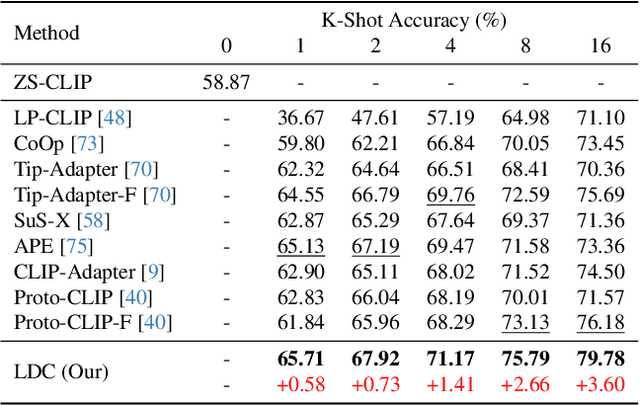
With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. Our MAF extracts features from different levels and fuses them uniformly to enhance feature representation. Our ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results show that our method can significantly improve the classification performance and alleviate the inter-class confusion problem. The code is available at https://github.com/LiShuo1001/LDC.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025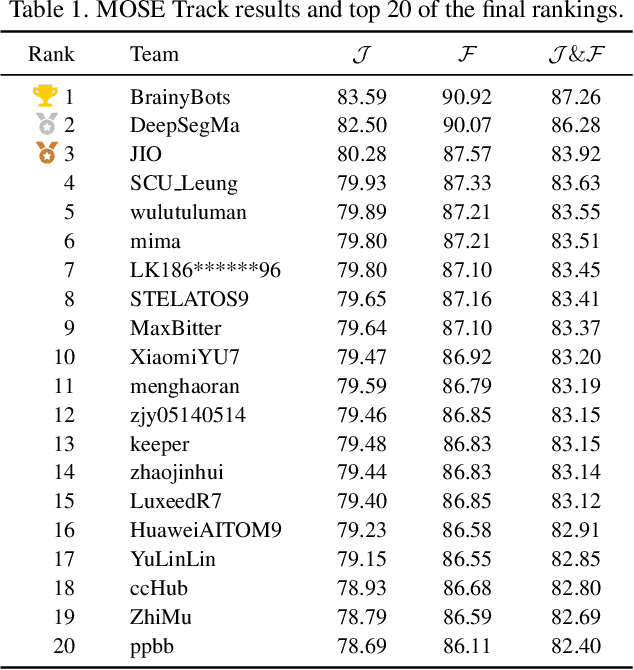
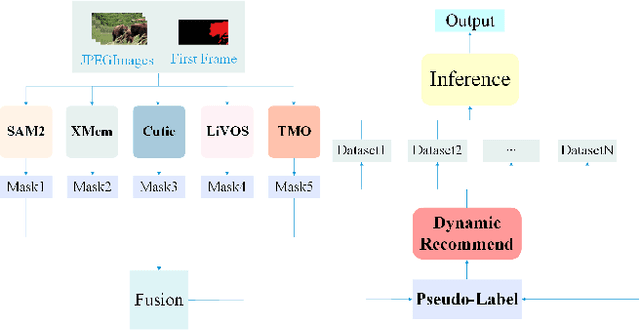
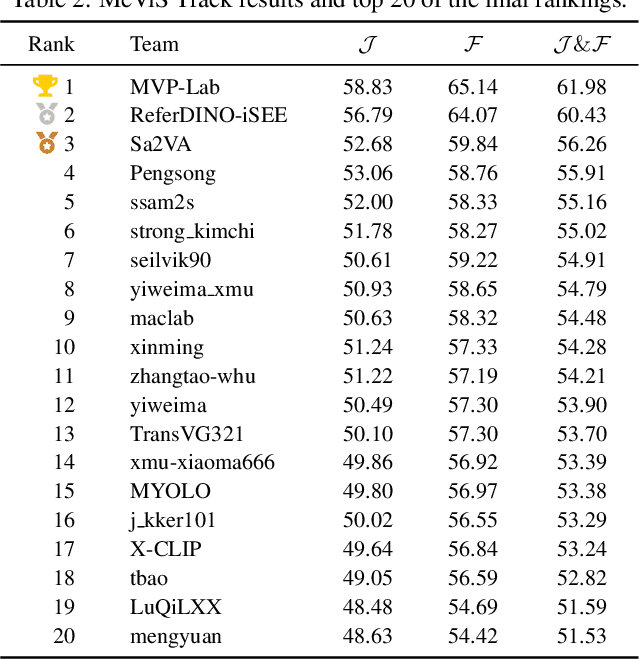
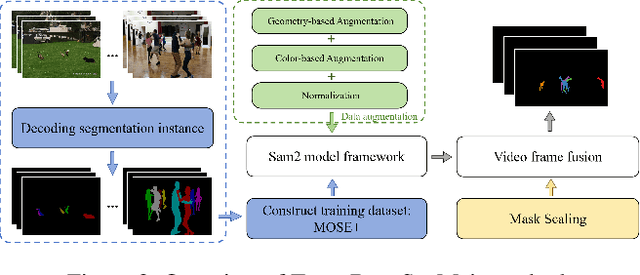
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.