 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
Jan 14, 2026General-purpose Large Vision-Language Models (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.
Frequency-Dynamic Attention Modulation for Dense Prediction
Jul 16, 2025Vision Transformers (ViTs) have significantly advanced computer vision, demonstrating strong performance across various tasks. However, the attention mechanism in ViTs makes each layer function as a low-pass filter, and the stacked-layer architecture in existing transformers suffers from frequency vanishing. This leads to the loss of critical details and textures. We propose a novel, circuit-theory-inspired strategy called Frequency-Dynamic Attention Modulation (FDAM), which can be easily plugged into ViTs. FDAM directly modulates the overall frequency response of ViTs and consists of two techniques: Attention Inversion (AttInv) and Frequency Dynamic Scaling (FreqScale). Since circuit theory uses low-pass filters as fundamental elements, we introduce AttInv, a method that generates complementary high-pass filtering by inverting the low-pass filter in the attention matrix, and dynamically combining the two. We further design FreqScale to weight different frequency components for fine-grained adjustments to the target response function. Through feature similarity analysis and effective rank evaluation, we demonstrate that our approach avoids representation collapse, leading to consistent performance improvements across various models, including SegFormer, DeiT, and MaskDINO. These improvements are evident in tasks such as semantic segmentation, object detection, and instance segmentation. Additionally, we apply our method to remote sensing detection, achieving state-of-the-art results in single-scale settings. The code is available at \href{https://github.com/Linwei-Chen/FDAM}{https://github.com/Linwei-Chen/FDAM}.
Spatial Frequency Modulation for Semantic Segmentation
Jul 16, 2025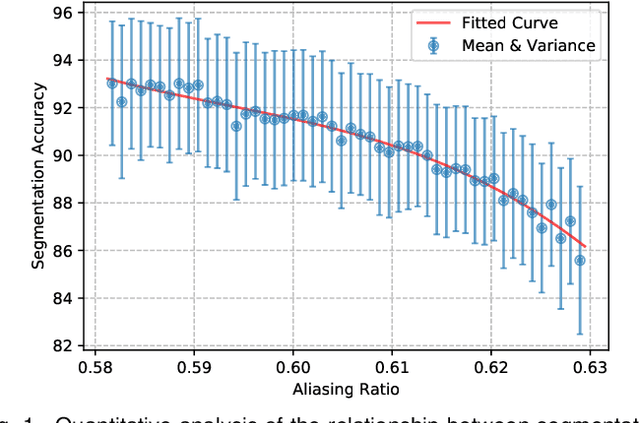
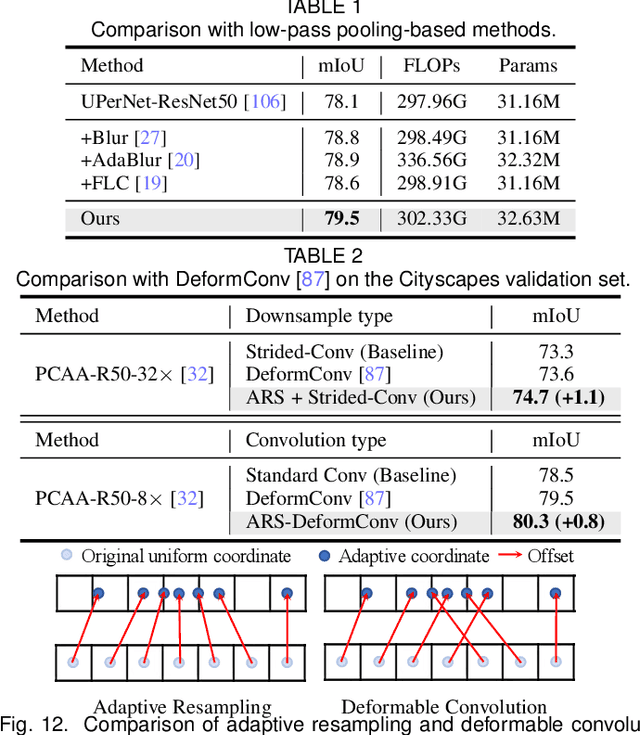
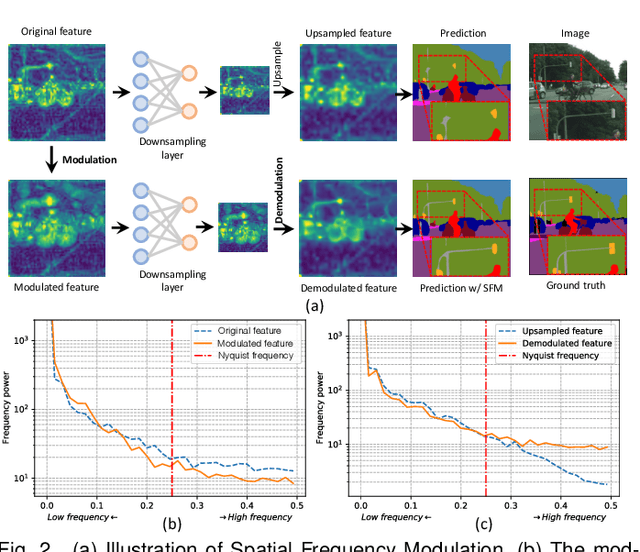
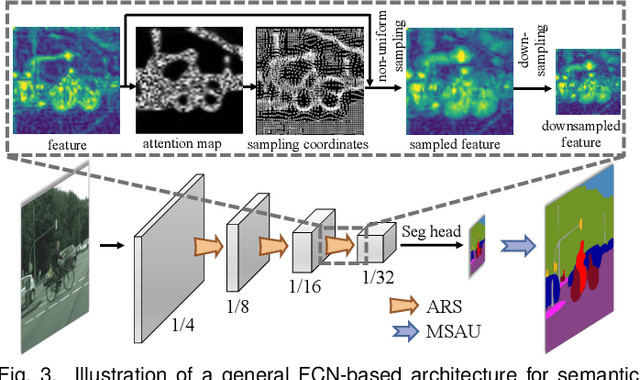
High spatial frequency information, including fine details like textures, significantly contributes to the accuracy of semantic segmentation. However, according to the Nyquist-Shannon Sampling Theorem, high-frequency components are vulnerable to aliasing or distortion when propagating through downsampling layers such as strided-convolution. Here, we propose a novel Spatial Frequency Modulation (SFM) that modulates high-frequency features to a lower frequency before downsampling and then demodulates them back during upsampling. Specifically, we implement modulation through adaptive resampling (ARS) and design a lightweight add-on that can densely sample the high-frequency areas to scale up the signal, thereby lowering its frequency in accordance with the Frequency Scaling Property. We also propose Multi-Scale Adaptive Upsampling (MSAU) to demodulate the modulated feature and recover high-frequency information through non-uniform upsampling This module further improves segmentation by explicitly exploiting information interaction between densely and sparsely resampled areas at multiple scales. Both modules can seamlessly integrate with various architectures, extending from convolutional neural networks to transformers. Feature visualization and analysis confirm that our method effectively alleviates aliasing while successfully retaining details after demodulation. Finally, we validate the broad applicability and effectiveness of SFM by extending it to image classification, adversarial robustness, instance segmentation, and panoptic segmentation tasks. The code is available at \href{https://github.com/Linwei-Chen/SFM}{https://github.com/Linwei-Chen/SFM}.
Frequency Dynamic Convolution for Dense Image Prediction
Mar 25, 2025While Dynamic Convolution (DY-Conv) has shown promising performance by enabling adaptive weight selection through multiple parallel weights combined with an attention mechanism, the frequency response of these weights tends to exhibit high similarity, resulting in high parameter costs but limited adaptability. In this work, we introduce Frequency Dynamic Convolution (FDConv), a novel approach that mitigates these limitations by learning a fixed parameter budget in the Fourier domain. FDConv divides this budget into frequency-based groups with disjoint Fourier indices, enabling the construction of frequency-diverse weights without increasing the parameter cost. To further enhance adaptability, we propose Kernel Spatial Modulation (KSM) and Frequency Band Modulation (FBM). KSM dynamically adjusts the frequency response of each filter at the spatial level, while FBM decomposes weights into distinct frequency bands in the frequency domain and modulates them dynamically based on local content. Extensive experiments on object detection, segmentation, and classification validate the effectiveness of FDConv. We demonstrate that when applied to ResNet-50, FDConv achieves superior performance with a modest increase of +3.6M parameters, outperforming previous methods that require substantial increases in parameter budgets (e.g., CondConv +90M, KW +76.5M). Moreover, FDConv seamlessly integrates into a variety of architectures, including ConvNeXt, Swin-Transformer, offering a flexible and efficient solution for modern vision tasks. The code is made publicly available at https://github.com/Linwei-Chen/FDConv.
Frequency-aware Feature Fusion for Dense Image Prediction
Aug 23, 2024Dense image prediction tasks demand features with strong category information and precise spatial boundary details at high resolution. To achieve this, modern hierarchical models often utilize feature fusion, directly adding upsampled coarse features from deep layers and high-resolution features from lower levels. In this paper, we observe rapid variations in fused feature values within objects, resulting in intra-category inconsistency due to disturbed high-frequency features. Additionally, blurred boundaries in fused features lack accurate high frequency, leading to boundary displacement. Building upon these observations, we propose Frequency-Aware Feature Fusion (FreqFusion), integrating an Adaptive Low-Pass Filter (ALPF) generator, an offset generator, and an Adaptive High-Pass Filter (AHPF) generator. The ALPF generator predicts spatially-variant low-pass filters to attenuate high-frequency components within objects, reducing intra-class inconsistency during upsampling. The offset generator refines large inconsistent features and thin boundaries by replacing inconsistent features with more consistent ones through resampling, while the AHPF generator enhances high-frequency detailed boundary information lost during downsampling. Comprehensive visualization and quantitative analysis demonstrate that FreqFusion effectively improves feature consistency and sharpens object boundaries. Extensive experiments across various dense prediction tasks confirm its effectiveness. The code is made publicly available at https://github.com/Linwei-Chen/FreqFusion.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
When Semantic Segmentation Meets Frequency Aliasing
Mar 25, 2024



Despite recent advancements in semantic segmentation, where and what pixels are hard to segment remains largely unexplored. Existing research only separates an image into easy and hard regions and empirically observes the latter are associated with object boundaries. In this paper, we conduct a comprehensive analysis of hard pixel errors, categorizing them into three types: false responses, merging mistakes, and displacements. Our findings reveal a quantitative association between hard pixels and aliasing, which is distortion caused by the overlapping of frequency components in the Fourier domain during downsampling. To identify the frequencies responsible for aliasing, we propose using the equivalent sampling rate to calculate the Nyquist frequency, which marks the threshold for aliasing. Then, we introduce the aliasing score as a metric to quantify the extent of aliasing. While positively correlated with the proposed aliasing score, three types of hard pixels exhibit different patterns. Here, we propose two novel de-aliasing filter (DAF) and frequency mixing (FreqMix) modules to alleviate aliasing degradation by accurately removing or adjusting frequencies higher than the Nyquist frequency. The DAF precisely removes the frequencies responsible for aliasing before downsampling, while the FreqMix dynamically selects high-frequency components within the encoder block. Experimental results demonstrate consistent improvements in semantic segmentation and low-light instance segmentation tasks. The code is available at: https://github.com/Linwei-Chen/Seg-Aliasing.
Frequency-Adaptive Dilated Convolution for Semantic Segmentation
Mar 12, 2024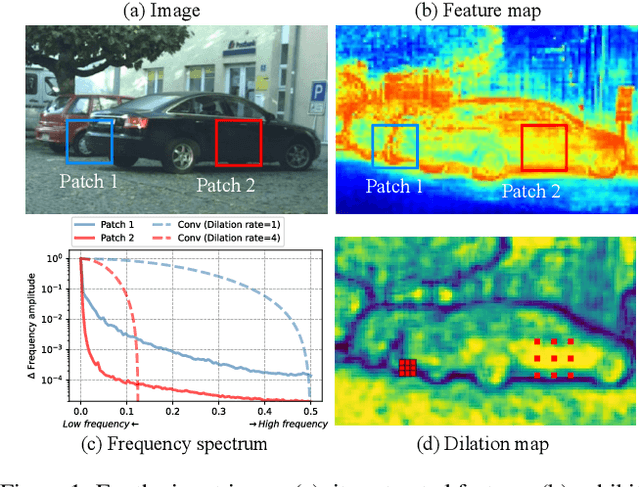
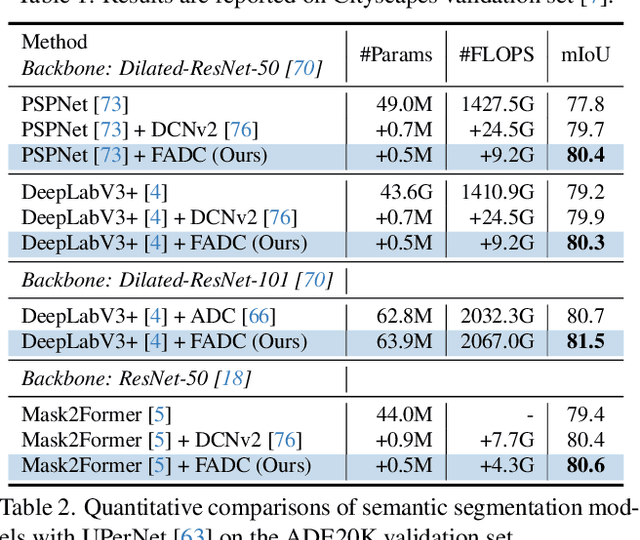
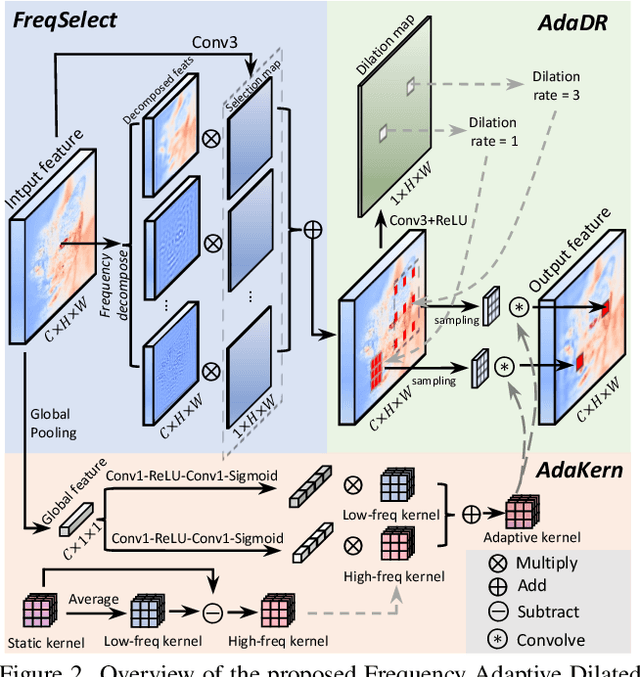

Dilated convolution, which expands the receptive field by inserting gaps between its consecutive elements, is widely employed in computer vision. In this study, we propose three strategies to improve individual phases of dilated convolution from the view of spectrum analysis. Departing from the conventional practice of fixing a global dilation rate as a hyperparameter, we introduce Frequency-Adaptive Dilated Convolution (FADC), which dynamically adjusts dilation rates spatially based on local frequency components. Subsequently, we design two plug-in modules to directly enhance effective bandwidth and receptive field size. The Adaptive Kernel (AdaKern) module decomposes convolution weights into low-frequency and high-frequency components, dynamically adjusting the ratio between these components on a per-channel basis. By increasing the high-frequency part of convolution weights, AdaKern captures more high-frequency components, thereby improving effective bandwidth. The Frequency Selection (FreqSelect) module optimally balances high- and low-frequency components in feature representations through spatially variant reweighting. It suppresses high frequencies in the background to encourage FADC to learn a larger dilation, thereby increasing the receptive field for an expanded scope. Extensive experiments on segmentation and object detection consistently validate the efficacy of our approach. The code is publicly available at \url{https://github.com/Linwei-Chen/FADC}.
Instance Segmentation in the Dark
Apr 27, 2023Existing instance segmentation techniques are primarily tailored for high-visibility inputs, but their performance significantly deteriorates in extremely low-light environments. In this work, we take a deep look at instance segmentation in the dark and introduce several techniques that substantially boost the low-light inference accuracy. The proposed method is motivated by the observation that noise in low-light images introduces high-frequency disturbances to the feature maps of neural networks, thereby significantly degrading performance. To suppress this ``feature noise", we propose a novel learning method that relies on an adaptive weighted downsampling layer, a smooth-oriented convolutional block, and disturbance suppression learning. These components effectively reduce feature noise during downsampling and convolution operations, enabling the model to learn disturbance-invariant features. Furthermore, we discover that high-bit-depth RAW images can better preserve richer scene information in low-light conditions compared to typical camera sRGB outputs, thus supporting the use of RAW-input algorithms. Our analysis indicates that high bit-depth can be critical for low-light instance segmentation. To mitigate the scarcity of annotated RAW datasets, we leverage a low-light RAW synthetic pipeline to generate realistic low-light data. In addition, to facilitate further research in this direction, we capture a real-world low-light instance segmentation dataset comprising over two thousand paired low/normal-light images with instance-level pixel-wise annotations. Remarkably, without any image preprocessing, we achieve satisfactory performance on instance segmentation in very low light (4~\% AP higher than state-of-the-art competitors), meanwhile opening new opportunities for future research.