 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Light Color Photometric Stereo for mono-Chromaticity non-lambertian surface
Jan 19, 2026Color photometric stereo enables single-shot surface reconstruction, extending conventional photometric stereo that requires multiple images of a static scene under varying illumination to dynamic scenarios. However, most existing approaches assume ideal distant lighting and Lambertian reflectance, leaving more practical near-light conditions and non-Lambertian surfaces underexplored. To overcome this limitation, we propose a framework that leverages neural implicit representations for depth and BRDF modeling under the assumption of mono-chromaticity (uniform chromaticity and homogeneous material), which alleviates the inherent ill-posedness of color photometric stereo and allows for detailed surface recovery from just one image. Furthermore, we design a compact optical tactile sensor to validate our approach. Experiments on both synthetic and real-world datasets demonstrate that our method achieves accurate and robust surface reconstruction.
Towards Deeper Emotional Reflection: Crafting Affective Image Filters with Generative Priors
Dec 19, 2025

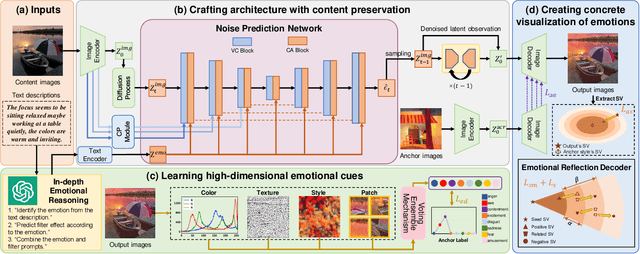

Social media platforms enable users to express emotions by posting text with accompanying images. In this paper, we propose the Affective Image Filter (AIF) task, which aims to reflect visually-abstract emotions from text into visually-concrete images, thereby creating emotionally compelling results. We first introduce the AIF dataset and the formulation of the AIF models. Then, we present AIF-B as an initial attempt based on a multi-modal transformer architecture. After that, we propose AIF-D as an extension of AIF-B towards deeper emotional reflection, effectively leveraging generative priors from pre-trained large-scale diffusion models. Quantitative and qualitative experiments demonstrate that AIF models achieve superior performance for both content consistency and emotional fidelity compared to state-of-the-art methods. Extensive user study experiments demonstrate that AIF models are significantly more effective at evoking specific emotions. Based on the presented results, we comprehensively discuss the value and potential of AIF models.
STAGE: Storyboard-Anchored Generation for Cinematic Multi-shot Narrative
Dec 13, 2025



While recent advancements in generative models have achieved remarkable visual fidelity in video synthesis, creating coherent multi-shot narratives remains a significant challenge. To address this, keyframe-based approaches have emerged as a promising alternative to computationally intensive end-to-end methods, offering the advantages of fine-grained control and greater efficiency. However, these methods often fail to maintain cross-shot consistency and capture cinematic language. In this paper, we introduce STAGE, a SToryboard-Anchored GEneration workflow to reformulate the keyframe-based multi-shot video generation task. Instead of using sparse keyframes, we propose STEP2 to predict a structural storyboard composed of start-end frame pairs for each shot. We introduce the multi-shot memory pack to ensure long-range entity consistency, the dual-encoding strategy for intra-shot coherence, and the two-stage training scheme to learn cinematic inter-shot transition. We also contribute the large-scale ConStoryBoard dataset, including high-quality movie clips with fine-grained annotations for story progression, cinematic attributes, and human preferences. Extensive experiments demonstrate that STAGE achieves superior performance in structured narrative control and cross-shot coherence.
Reconstruction as a Bridge for Event-Based Visual Question Answering
Dec 12, 2025Integrating event cameras with Multimodal Large Language Models (MLLMs) promises general scene understanding in challenging visual conditions, yet requires navigating a trade-off between preserving the unique advantages of event data and ensuring compatibility with frame-based models. We address this challenge by using reconstruction as a bridge, proposing a straightforward Frame-based Reconstruction and Tokenization (FRT) method and designing an efficient Adaptive Reconstruction and Tokenization (ART) method that leverages event sparsity. For robust evaluation, we introduce EvQA, the first objective, real-world benchmark for event-based MLLMs, comprising 1,000 event-Q&A pairs from 22 public datasets. Our experiments demonstrate that our methods achieve state-of-the-art performance on EvQA, highlighting the significant potential of MLLMs in event-based vision.
Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Dec 11, 2025



Recent advancements in video generation highlight that realistic audio-visual synchronization is crucial for engaging content creation. However, existing video editing methods largely overlook audio-visual synchronization and lack the fine-grained spatial and temporal controllability required for precise instance-level edits. In this paper, we propose AVI-Edit, a framework for audio-sync video instance editing. We propose a granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions. We further design a self-feedback audio agent to curate high-quality audio guidance, providing fine-grained temporal control. To facilitate this task, we additionally construct a large-scale dataset with instance-centric correspondence and comprehensive annotations. Extensive experiments demonstrate that AVI-Edit outperforms state-of-the-art methods in visual quality, condition following, and audio-visual synchronization. Project page: https://hjzheng.net/projects/AVI-Edit/.
BokehDiff: Neural Lens Blur with One-Step Diffusion
Jul 24, 2025We introduce BokehDiff, a novel lens blur rendering method that achieves physically accurate and visually appealing outcomes, with the help of generative diffusion prior. Previous methods are bounded by the accuracy of depth estimation, generating artifacts in depth discontinuities. Our method employs a physics-inspired self-attention module that aligns with the image formation process, incorporating depth-dependent circle of confusion constraint and self-occlusion effects. We adapt the diffusion model to the one-step inference scheme without introducing additional noise, and achieve results of high quality and fidelity. To address the lack of scalable paired data, we propose to synthesize photorealistic foregrounds with transparency with diffusion models, balancing authenticity and scene diversity.
PolarAnything: Diffusion-based Polarimetric Image Synthesis
Jul 24, 2025Polarization images facilitate image enhancement and 3D reconstruction tasks, but the limited accessibility of polarization cameras hinders their broader application. This gap drives the need for synthesizing photorealistic polarization images. The existing polarization simulator Mitsuba relies on a parametric polarization image formation model and requires extensive 3D assets covering shape and PBR materials, preventing it from generating large-scale photorealistic images. To address this problem, we propose PolarAnything, capable of synthesizing polarization images from a single RGB input with both photorealism and physical accuracy, eliminating the dependency on 3D asset collections. Drawing inspiration from the zero-shot performance of pretrained diffusion models, we introduce a diffusion-based generative framework with an effective representation strategy that preserves the fidelity of polarization properties. Experiments show that our model generates high-quality polarization images and supports downstream tasks like shape from polarization.
Dark-EvGS: Event Camera as an Eye for Radiance Field in the Dark
Jul 16, 2025



In low-light environments, conventional cameras often struggle to capture clear multi-view images of objects due to dynamic range limitations and motion blur caused by long exposure. Event cameras, with their high-dynamic range and high-speed properties, have the potential to mitigate these issues. Additionally, 3D Gaussian Splatting (GS) enables radiance field reconstruction, facilitating bright frame synthesis from multiple viewpoints in low-light conditions. However, naively using an event-assisted 3D GS approach still faced challenges because, in low light, events are noisy, frames lack quality, and the color tone may be inconsistent. To address these issues, we propose Dark-EvGS, the first event-assisted 3D GS framework that enables the reconstruction of bright frames from arbitrary viewpoints along the camera trajectory. Triplet-level supervision is proposed to gain holistic knowledge, granular details, and sharp scene rendering. The color tone matching block is proposed to guarantee the color consistency of the rendered frames. Furthermore, we introduce the first real-captured dataset for the event-guided bright frame synthesis task via 3D GS-based radiance field reconstruction. Experiments demonstrate that our method achieves better results than existing methods, conquering radiance field reconstruction under challenging low-light conditions. The code and sample data are included in the supplementary material.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025
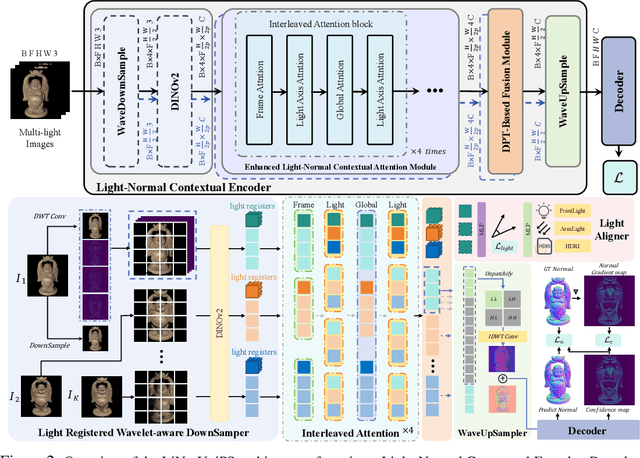
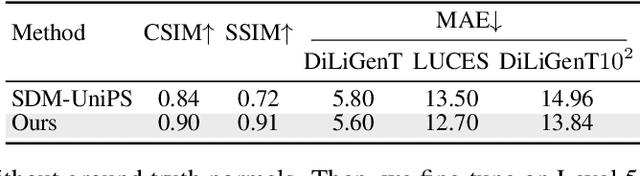

Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
Audio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.