 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2VIDiff: Perceptual Events-to-Video Reconstruction using Diffusion Priors
Jul 11, 2024Event cameras, mimicking the human retina, capture brightness changes with unparalleled temporal resolution and dynamic range. Integrating events into intensities poses a highly ill-posed challenge, marred by initial condition ambiguities. Traditional regression-based deep learning methods fall short in perceptual quality, offering deterministic and often unrealistic reconstructions. In this paper, we introduce diffusion models to events-to-video reconstruction, achieving colorful, realistic, and perceptually superior video generation from achromatic events. Powered by the image generation ability and knowledge of pretrained diffusion models, the proposed method can achieve a better trade-off between the perception and distortion of the reconstructed frame compared to previous solutions. Extensive experiments on benchmark datasets demonstrate that our approach can produce diverse, realistic frames with faithfulness to the given events.
Separated Contrastive Learning for Organ-at-Risk and Gross-Tumor-Volume Segmentation with Limited Annotation
Dec 06, 2021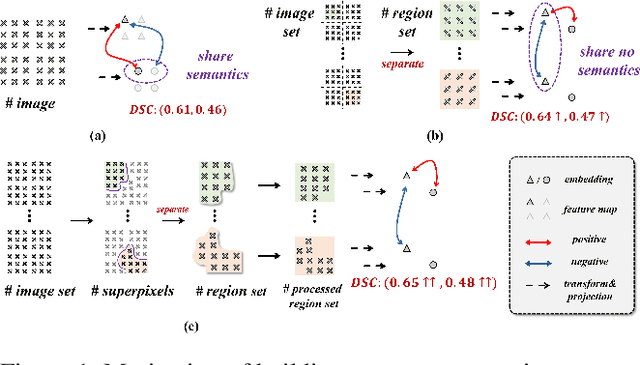

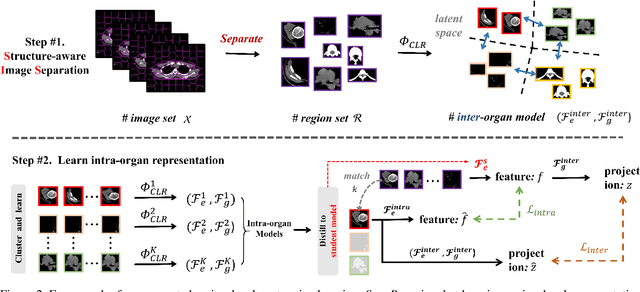
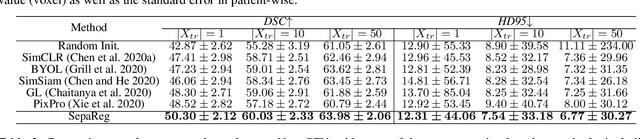
Automatic delineation of organ-at-risk (OAR) and gross-tumor-volume (GTV) is of great significance for radiotherapy planning. However, it is a challenging task to learn powerful representations for accurate delineation under limited pixel (voxel)-wise annotations. Contrastive learning at pixel-level can alleviate the dependency on annotations by learning dense representations from unlabeled data. Recent studies in this direction design various contrastive losses on the feature maps, to yield discriminative features for each pixel in the map. However, pixels in the same map inevitably share semantics to be closer than they actually are, which may affect the discrimination of pixels in the same map and lead to the unfair comparison to pixels in other maps. To address these issues, we propose a separated region-level contrastive learning scheme, namely SepaReg, the core of which is to separate each image into regions and encode each region separately. Specifically, SepaReg comprises two components: a structure-aware image separation (SIS) module and an intra- and inter-organ distillation (IID) module. The SIS is proposed to operate on the image set to rebuild a region set under the guidance of structural information. The inter-organ representation will be learned from this set via typical contrastive losses cross regions. On the other hand, the IID is proposed to tackle the quantity imbalance in the region set as tiny organs may produce fewer regions, by exploiting intra-organ representations. We conducted extensive experiments to evaluate the proposed model on a public dataset and two private datasets. The experimental results demonstrate the effectiveness of the proposed model, consistently achieving better performance than state-of-the-art approaches. Code is available at https://github.com/jcwang123/Separate_CL.