 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2V: Scaling Event-Based Vision through Efficient Video-to-Voxel Simulation
May 22, 2025Event-based cameras offer unique advantages such as high temporal resolution, high dynamic range, and low power consumption. However, the massive storage requirements and I/O burdens of existing synthetic data generation pipelines and the scarcity of real data prevent event-based training datasets from scaling up, limiting the development and generalization capabilities of event vision models. To address this challenge, we introduce Video-to-Voxel (V2V), an approach that directly converts conventional video frames into event-based voxel grid representations, bypassing the storage-intensive event stream generation entirely. V2V enables a 150 times reduction in storage requirements while supporting on-the-fly parameter randomization for enhanced model robustness. Leveraging this efficiency, we train several video reconstruction and optical flow estimation model architectures on 10,000 diverse videos totaling 52 hours--an order of magnitude larger than existing event datasets, yielding substantial improvements.
E2VIDiff: Perceptual Events-to-Video Reconstruction using Diffusion Priors
Jul 11, 2024Event cameras, mimicking the human retina, capture brightness changes with unparalleled temporal resolution and dynamic range. Integrating events into intensities poses a highly ill-posed challenge, marred by initial condition ambiguities. Traditional regression-based deep learning methods fall short in perceptual quality, offering deterministic and often unrealistic reconstructions. In this paper, we introduce diffusion models to events-to-video reconstruction, achieving colorful, realistic, and perceptually superior video generation from achromatic events. Powered by the image generation ability and knowledge of pretrained diffusion models, the proposed method can achieve a better trade-off between the perception and distortion of the reconstructed frame compared to previous solutions. Extensive experiments on benchmark datasets demonstrate that our approach can produce diverse, realistic frames with faithfulness to the given events.
Language-guided Image Reflection Separation
Feb 19, 2024This paper studies the problem of language-guided reflection separation, which aims at addressing the ill-posed reflection separation problem by introducing language descriptions to provide layer content. We propose a unified framework to solve this problem, which leverages the cross-attention mechanism with contrastive learning strategies to construct the correspondence between language descriptions and image layers. A gated network design and a randomized training strategy are employed to tackle the recognizable layer ambiguity. The effectiveness of the proposed method is validated by the significant performance advantage over existing reflection separation methods on both quantitative and qualitative comparisons.
NeuralMPS: Non-Lambertian Multispectral Photometric Stereo via Spectral Reflectance Decomposition
Nov 28, 2022Multispectral photometric stereo(MPS) aims at recovering the surface normal of a scene from a single-shot multispectral image captured under multispectral illuminations. Existing MPS methods adopt the Lambertian reflectance model to make the problem tractable, but it greatly limits their application to real-world surfaces. In this paper, we propose a deep neural network named NeuralMPS to solve the MPS problem under general non-Lambertian spectral reflectances. Specifically, we present a spectral reflectance decomposition(SRD) model to disentangle the spectral reflectance into geometric components and spectral components. With this decomposition, we show that the MPS problem for surfaces with a uniform material is equivalent to the conventional photometric stereo(CPS) with unknown light intensities. In this way, NeuralMPS reduces the difficulty of the non-Lambertian MPS problem by leveraging the well-studied non-Lambertian CPS methods. Experiments on both synthetic and real-world scenes demonstrate the effectiveness of our method.
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
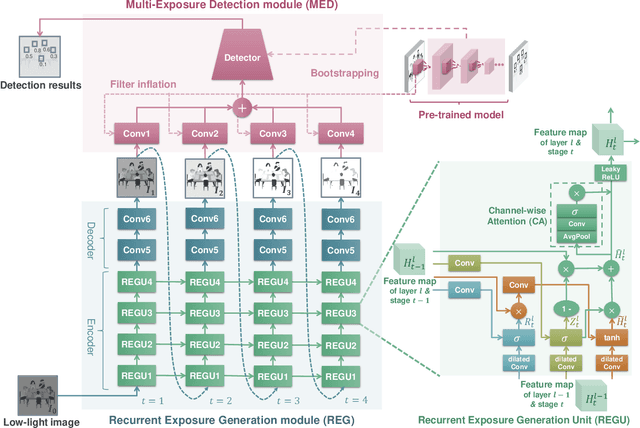


Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
Deep Bilateral Retinex for Low-Light Image Enhancement
Jul 04, 2020

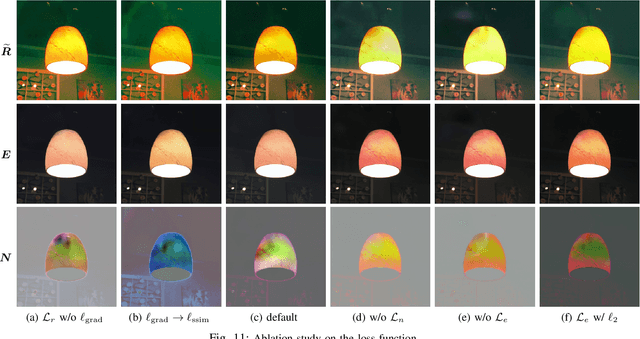

Low-light images, i.e. the images captured in low-light conditions, suffer from very poor visibility caused by low contrast, color distortion and significant measurement noise. Low-light image enhancement is about improving the visibility of low-light images. As the measurement noise in low-light images is usually significant yet complex with spatially-varying characteristic, how to handle the noise effectively is an important yet challenging problem in low-light image enhancement. Based on the Retinex decomposition of natural images, this paper proposes a deep learning method for low-light image enhancement with a particular focus on handling the measurement noise. The basic idea is to train a neural network to generate a set of pixel-wise operators for simultaneously predicting the noise and the illumination layer, where the operators are defined in the bilateral space. Such an integrated approach allows us to have an accurate prediction of the reflectance layer in the presence of significant spatially-varying measurement noise. Extensive experiments on several benchmark datasets have shown that the proposed method is very competitive to the state-of-the-art methods, and has significant advantage over others when processing images captured in extremely low lighting conditions.