 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoton: Speedup Volume Understanding with Efficient Multimodal Large Language Models
Mar 26, 2026Multimodal large language models are promising for clinical visual question answering tasks, but scaling to 3D imaging is hindered by high computational costs. Prior methods often rely on 2D slices or fixed-length token compression, disrupting volumetric continuity and obscuring subtle findings. We present Photon, a framework that represents 3D medical volumes with token sequences of variable length. Photon introduces instruction-conditioned token scheduling and surrogate gradient propagation to adaptively reduce tokens during both training and inference, which lowers computational cost while mitigating the attention dilution caused by redundant tokens. It incorporates a custom backpropagation rule with gradient restoration to enable differentiable optimization despite discrete token drop. To stabilize token compression and ensure reliable use of visual evidence, Photon further applies regularization objectives that mitigate language-only bias and improve reliability. Experiments on diverse medical visual question answering tasks show that Photon achieves state-of-the-art accuracy while reducing resource usage and accelerating both training and inference.
High-fidelity Multi-view Normal Integration with Scale-encoded Neural Surface Representation
Mar 20, 2026Previous multi-view normal integration methods typically sample a single ray per pixel, without considering the spatial area covered by each pixel, which varies with camera intrinsics and the camera-to-object distance. Consequently, when the target object is captured at different distances, the normals at corresponding pixels may differ across views. This multi-view surface normal inconsistency results in the blurring of high-frequency details in the reconstructed surface. To address this issue, we propose a scale-encoded neural surface representation that incorporates the pixel coverage area into the neural representation. By associating each 3D point with a spatial scale and calculating its normal from a hybrid grid-based encoding, our method effectively represents multi-scale surface normals captured at varying distances. Furthermore, to enable scale-aware surface reconstruction, we introduce a mesh extraction module that assigns an optimal local scale to each vertex based on the training observations. Experimental results demonstrate that our approach consistently yields high-fidelity surface reconstruction from normals observed at varying distances, outperforming existing multi-view normal integration methods.
VIGOR: VIdeo Geometry-Oriented Reward for Temporal Generative Alignment
Mar 17, 2026Video diffusion models lack explicit geometric supervision during training, leading to inconsistency artifacts such as object deformation, spatial drift, and depth violations in generated videos. To address this limitation, we propose a geometry-based reward model that leverages pretrained geometric foundation models to evaluate multi-view consistency through cross-frame reprojection error. Unlike previous geometric metrics that measure inconsistency in pixel space, where pixel intensity may introduce additional noise, our approach conducts error computation in a pointwise fashion, yielding a more physically grounded and robust error metric. Furthermore, we introduce a geometry-aware sampling strategy that filters out low-texture and non-semantic regions, focusing evaluation on geometrically meaningful areas with reliable correspondences to improve robustness. We apply this reward model to align video diffusion models through two complementary pathways: post-training of a bidirectional model via SFT or Reinforcement Learning and inference-time optimization of a Causal Video Model (e.g., Streaming video generator) via test-time scaling with our reward as a path verifier. Experimental results validate the effectiveness of our design, demonstrating that our geometry-based reward provides superior robustness compared to other variants. By enabling efficient inference-time scaling, our method offers a practical solution for enhancing open-source video models without requiring extensive computational resources for retraining.
Near-light Photometric Stereo with Symmetric Lights
Mar 17, 2026This paper describes a linear solution method for near-light photometric stereo by exploiting symmetric light source arrangements. Unlike conventional non-convex optimization approaches, by arranging multiple sets of symmetric nearby light source pairs, our method derives a closed-form solution for surface normal and depth without requiring initialization. In addition, our method works as long as the light sources are symmetrically distributed about an arbitrary point even when the entire spatial offset is uncalibrated. Experiments showcase the accuracy of shape recovery accuracy of our method, achieving comparable results to the state-of-the-art calibrated near-light photometric stereo method while significantly reducing requirements of careful depth initialization and light calibration.
PolGS++: Physically-Guided Polarimetric Gaussian Splatting for Fast Reflective Surface Reconstruction
Mar 11, 2026Accurate reconstruction of reflective surfaces remains a fundamental challenge in computer vision, with broad applications in real-time virtual reality and digital content creation. Although 3D Gaussian Splatting (3DGS) enables efficient novel-view rendering with explicit representations, its performance on reflective surfaces still lags behind implicit neural methods, especially in recovering fine geometry and surface normals. To address this gap, we propose PolGS++, a physically-guided polarimetric Gaussian Splatting framework for fast reflective surface reconstruction. Specifically, we integrate a polarized BRDF (pBRDF) model into 3DGS to explicitly decouple diffuse and specular components, providing physically grounded reflectance modeling and stronger geometric cues for reflective surface recovery. Furthermore, we introduce a depth-guided visibility mask acquisition mechanism that enables angle-of-polarization (AoP)-based tangent-space consistency constraints in Gaussian Splatting without costly ray-tracing intersections. This physically guided design improves reconstruction quality and efficiency, requiring only about 10 minutes of training. Extensive experiments on both synthetic and real-world datasets validate the effectiveness of our method.
EvalMVX: A Unified Benchmarking for Neural 3D Reconstruction under Diverse Multiview Setups
Mar 04, 2026Recent advancements in neural surface reconstruction have significantly enhanced 3D reconstruction. However, current real world datasets mainly focus on benchmarking multiview stereo (MVS) based on RGB inputs. Multiview photometric stereo (MVPS) and multiview shape from polarization (MVSfP), though indispensable on high-fidelity surface reconstruction and sparse inputs, have not been quantitatively assessed together with MVS. To determine the working range of different MVX (MVS, MVSfP, and MVPS) techniques, we propose EvalMVX, a real-world dataset containing $25$ objects, each captured with a polarized camera under $20$ varying views and $17$ light conditions including OLAT and natural illumination, leading to $8,500$ images. Each object includes aligned ground-truth 3D mesh, facilitating quantitative benchmarking of MVX methods simultaneously. Based on our EvalMVX, we evaluate $13$ MVX methods published in recent years, record the best-performing methods, and identify open problems under diverse geometric details and reflectance types. We hope EvalMVX and the benchmarking results can inspire future research on multiview 3D reconstruction.
Near-Light Color Photometric Stereo for mono-Chromaticity non-lambertian surface
Jan 19, 2026Color photometric stereo enables single-shot surface reconstruction, extending conventional photometric stereo that requires multiple images of a static scene under varying illumination to dynamic scenarios. However, most existing approaches assume ideal distant lighting and Lambertian reflectance, leaving more practical near-light conditions and non-Lambertian surfaces underexplored. To overcome this limitation, we propose a framework that leverages neural implicit representations for depth and BRDF modeling under the assumption of mono-chromaticity (uniform chromaticity and homogeneous material), which alleviates the inherent ill-posedness of color photometric stereo and allows for detailed surface recovery from just one image. Furthermore, we design a compact optical tactile sensor to validate our approach. Experiments on both synthetic and real-world datasets demonstrate that our method achieves accurate and robust surface reconstruction.
Measurement-Constrained Sampling for Text-Prompted Blind Face Restoration
Nov 18, 2025



Blind face restoration (BFR) may correspond to multiple plausible high-quality (HQ) reconstructions under extremely low-quality (LQ) inputs. However, existing methods typically produce deterministic results, struggling to capture this one-to-many nature. In this paper, we propose a Measurement-Constrained Sampling (MCS) approach that enables diverse LQ face reconstructions conditioned on different textual prompts. Specifically, we formulate BFR as a measurement-constrained generative task by constructing an inverse problem through controlled degradations of coarse restorations, which allows posterior-guided sampling within text-to-image diffusion. Measurement constraints include both Forward Measurement, which ensures results align with input structures, and Reverse Measurement, which produces projection spaces, ensuring that the solution can align with various prompts. Experiments show that our MCS can generate prompt-aligned results and outperforms existing BFR methods. Codes will be released after acceptance.
Seeing Through the Rain: Resolving High-Frequency Conflicts in Deraining and Super-Resolution via Diffusion Guidance
Nov 16, 2025Clean images are crucial for visual tasks such as small object detection, especially at high resolutions. However, real-world images are often degraded by adverse weather, and weather restoration methods may sacrifice high-frequency details critical for analyzing small objects. A natural solution is to apply super-resolution (SR) after weather removal to recover both clarity and fine structures. However, simply cascading restoration and SR struggle to bridge their inherent conflict: removal aims to remove high-frequency weather-induced noise, while SR aims to hallucinate high-frequency textures from existing details, leading to inconsistent restoration contents. In this paper, we take deraining as a case study and propose DHGM, a Diffusion-based High-frequency Guided Model for generating clean and high-resolution images. DHGM integrates pre-trained diffusion priors with high-pass filters to simultaneously remove rain artifacts and enhance structural details. Extensive experiments demonstrate that DHGM achieves superior performance over existing methods, with lower costs.
SpecGen: Neural Spectral BRDF Generation via Spectral-Spatial Tri-plane Aggregation
Aug 24, 2025
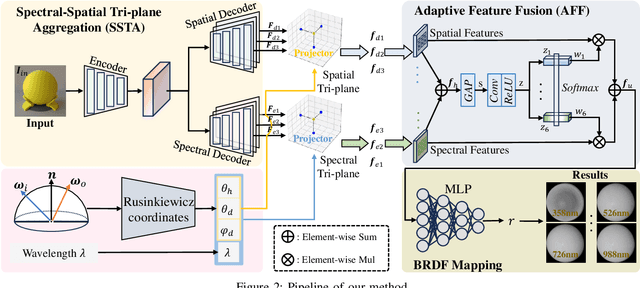
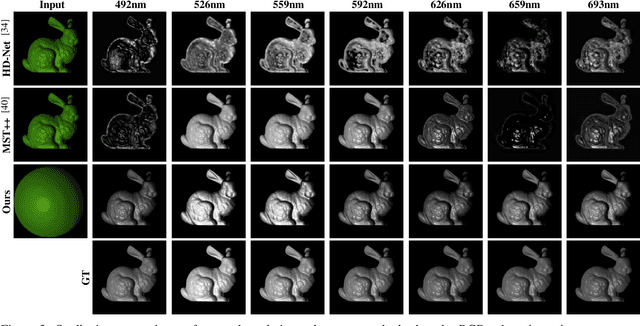

Synthesizing spectral images across different wavelengths is essential for photorealistic rendering. Unlike conventional spectral uplifting methods that convert RGB images into spectral ones, we introduce SpecGen, a novel method that generates spectral bidirectional reflectance distribution functions (BRDFs) from a single RGB image of a sphere. This enables spectral image rendering under arbitrary illuminations and shapes covered by the corresponding material. A key challenge in spectral BRDF generation is the scarcity of measured spectral BRDF data. To address this, we propose the Spectral-Spatial Tri-plane Aggregation (SSTA) network, which models reflectance responses across wavelengths and incident-outgoing directions, allowing the training strategy to leverage abundant RGB BRDF data to enhance spectral BRDF generation. Experiments show that our method accurately reconstructs spectral BRDFs from limited spectral data and surpasses state-of-the-art methods in hyperspectral image reconstruction, achieving an improvement of 8 dB in PSNR. Codes and data will be released upon acceptance.