 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Mar 26, 2026Concept erasure serves as a vital safety mechanism for removing unwanted concepts from text-to-image (T2I) models. While extensively studied in U-Net and dual-stream architectures (e.g., Flux), this task remains under-explored in the recent emerging paradigm of single-stream diffusion transformers (e.g., Z-Image). In this new paradigm, text and image tokens are processed as a single unified sequence via shared parameters. Consequently, directly applying prior erasure methods typically leads to generation collapse. To bridge this gap, we introduce Z-Erase, the first concept erasure method tailored for single-stream T2I models. To guarantee stable image generation, Z-Erase first proposes a Stream Disentangled Concept Erasure Framework that decouples updates and enables existing methods on single-stream models. Subsequently, within this framework, we introduce Lagrangian-Guided Adaptive Erasure Modulation, a constrained algorithm that further balances the sensitive erasure-preservation trade-off. Moreover, we provide a rigorous convergence analysis proving that Z-Erase can converge to a Pareto stationary point. Experiments demonstrate that Z-Erase successfully overcomes the generation collapse issue, achieving state-of-the-art performance across a wide range of tasks.
InstanceAnimator: Multi-Instance Sketch Video Colorization
Mar 26, 2026We propose InstanceAnimator, a novel Diffusion Transformer framework for multi-instance sketch video colorization. Existing methods suffer from three core limitations: inflexible user control due to heavy reliance on single reference frames, poor instance controllability leading to misalignment in multi-character scenarios, and degraded detail fidelity in fine-grained regions. To address these challenges, we introduce three corresponding innovations. First, a Canvas Guidance Condition eliminates workflow fragmentation by allowing free placement of reference elements and background, enabling unprecedented user flexibility. Second, an Instance Matching Mechanism resolves misalignment by integrating instance features with the sketches, ensuring precise control over multiple characters. Third, an Adaptive Decoupled Control Module enhances detail fidelity by injecting semantic features from characters, backgrounds, and text conditions into the diffusion process. Extensive experiments demonstrate that InstanceAnimator achieves superior multi-instance colorization with enhanced user control, high visual quality, and strong instance consistency.
Erased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Oct 01, 2025Recent advances in text-to-image (T2I) diffusion models have enabled impressive generative capabilities, but they also raise significant safety concerns due to the potential to produce harmful or undesirable content. While concept erasure has been explored as a mitigation strategy, most existing approaches and corresponding attack evaluations are tailored to Stable Diffusion (SD) and exhibit limited effectiveness when transferred to next-generation rectified flow transformers such as Flux. In this work, we present ReFlux, the first concept attack method specifically designed to assess the robustness of concept erasure in the latest rectified flow-based T2I framework. Our approach is motivated by the observation that existing concept erasure techniques, when applied to Flux, fundamentally rely on a phenomenon known as attention localization. Building on this insight, we propose a simple yet effective attack strategy that specifically targets this property. At its core, a reverse-attention optimization strategy is introduced to effectively reactivate suppressed signals while stabilizing attention. This is further reinforced by a velocity-guided dynamic that enhances the robustness of concept reactivation by steering the flow matching process, and a consistency-preserving objective that maintains the global layout and preserves unrelated content. Extensive experiments consistently demonstrate the effectiveness and efficiency of the proposed attack method, establishing a reliable benchmark for evaluating the robustness of concept erasure strategies in rectified flow transformers.
Knowing or Guessing? Robust Medical Visual Question Answering via Joint Consistency and Contrastive Learning
Aug 26, 2025In high-stakes medical applications, consistent answering across diverse question phrasings is essential for reliable diagnosis. However, we reveal that current Medical Vision-Language Models (Med-VLMs) exhibit concerning fragility in Medical Visual Question Answering, as their answers fluctuate significantly when faced with semantically equivalent rephrasings of medical questions. We attribute this to two limitations: (1) insufficient alignment of medical concepts, leading to divergent reasoning patterns, and (2) hidden biases in training data that prioritize syntactic shortcuts over semantic understanding. To address these challenges, we construct RoMed, a dataset built upon original VQA datasets containing 144k questions with variations spanning word-level, sentence-level, and semantic-level perturbations. When evaluating state-of-the-art (SOTA) models like LLaVA-Med on RoMed, we observe alarming performance drops (e.g., a 40\% decline in Recall) compared to original VQA benchmarks, exposing critical robustness gaps. To bridge this gap, we propose Consistency and Contrastive Learning (CCL), which integrates two key components: (1) knowledge-anchored consistency learning, aligning Med-VLMs with medical knowledge rather than shallow feature patterns, and (2) bias-aware contrastive learning, mitigating data-specific priors through discriminative representation refinement. CCL achieves SOTA performance on three popular VQA benchmarks and notably improves answer consistency by 50\% on the challenging RoMed test set, demonstrating significantly enhanced robustness. Code will be released.
HieroAction: Hierarchically Guided VLM for Fine-Grained Action Analysis
Aug 23, 2025Evaluating human actions with clear and detailed feedback is important in areas such as sports, healthcare, and robotics, where decisions rely not only on final outcomes but also on interpretable reasoning. However, most existing methods provide only a final score without explanation or detailed analysis, limiting their practical applicability. To address this, we introduce HieroAction, a vision-language model that delivers accurate and structured assessments of human actions. HieroAction builds on two key ideas: (1) Stepwise Action Reasoning, a tailored chain of thought process designed specifically for action assessment, which guides the model to evaluate actions step by step, from overall recognition through sub action analysis to final scoring, thus enhancing interpretability and structured understanding; and (2) Hierarchical Policy Learning, a reinforcement learning strategy that enables the model to learn fine grained sub action dynamics and align them with high level action quality, thereby improving scoring precision. The reasoning pathway structures the evaluation process, while policy learning refines each stage through reward based optimization. Their integration ensures accurate and interpretable assessments, as demonstrated by superior performance across multiple benchmark datasets. Code will be released upon acceptance.
Mem4D: Decoupling Static and Dynamic Memory for Dynamic Scene Reconstruction
Aug 12, 2025Reconstructing dense geometry for dynamic scenes from a monocular video is a critical yet challenging task. Recent memory-based methods enable efficient online reconstruction, but they fundamentally suffer from a Memory Demand Dilemma: The memory representation faces an inherent conflict between the long-term stability required for static structures and the rapid, high-fidelity detail retention needed for dynamic motion. This conflict forces existing methods into a compromise, leading to either geometric drift in static structures or blurred, inaccurate reconstructions of dynamic objects. To address this dilemma, we propose Mem4D, a novel framework that decouples the modeling of static geometry and dynamic motion. Guided by this insight, we design a dual-memory architecture: 1) The Transient Dynamics Memory (TDM) focuses on capturing high-frequency motion details from recent frames, enabling accurate and fine-grained modeling of dynamic content; 2) The Persistent Structure Memory (PSM) compresses and preserves long-term spatial information, ensuring global consistency and drift-free reconstruction for static elements. By alternating queries to these specialized memories, Mem4D simultaneously maintains static geometry with global consistency and reconstructs dynamic elements with high fidelity. Experiments on challenging benchmarks demonstrate that our method achieves state-of-the-art or competitive performance while maintaining high efficiency. Codes will be publicly available.
Undress to Redress: A Training-Free Framework for Virtual Try-On
Aug 11, 2025Virtual try-on (VTON) is a crucial task for enhancing user experience in online shopping by generating realistic garment previews on personal photos. Although existing methods have achieved impressive results, they struggle with long-sleeve-to-short-sleeve conversions-a common and practical scenario-often producing unrealistic outputs when exposed skin is underrepresented in the original image. We argue that this challenge arises from the ''majority'' completion rule in current VTON models, which leads to inaccurate skin restoration in such cases. To address this, we propose UR-VTON (Undress-Redress Virtual Try-ON), a novel, training-free framework that can be seamlessly integrated with any existing VTON method. UR-VTON introduces an ''undress-to-redress'' mechanism: it first reveals the user's torso by virtually ''undressing,'' then applies the target short-sleeve garment, effectively decomposing the conversion into two more manageable steps. Additionally, we incorporate Dynamic Classifier-Free Guidance scheduling to balance diversity and image quality during DDPM sampling, and employ Structural Refiner to enhance detail fidelity using high-frequency cues. Finally, we present LS-TON, a new benchmark for long-sleeve-to-short-sleeve try-on. Extensive experiments demonstrate that UR-VTON outperforms state-of-the-art methods in both detail preservation and image quality. Code will be released upon acceptance.
Adapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025



Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025
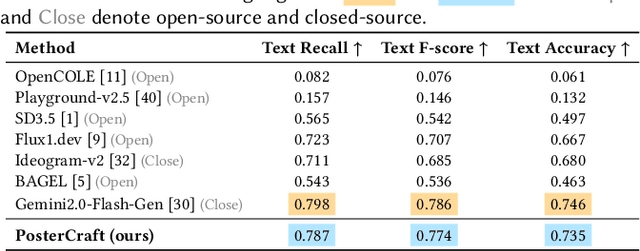
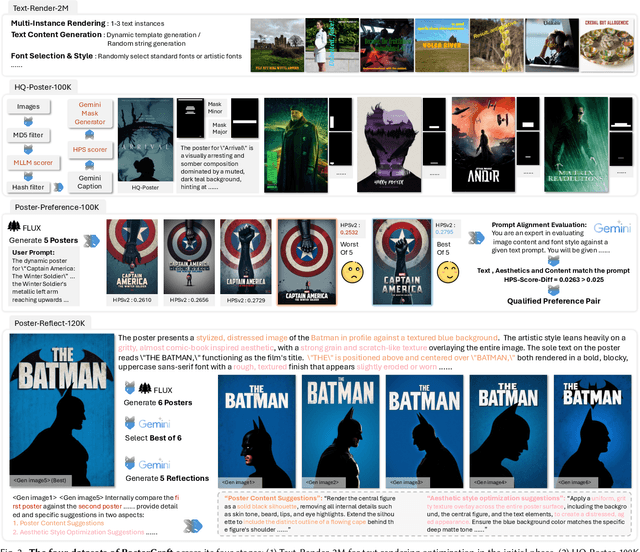
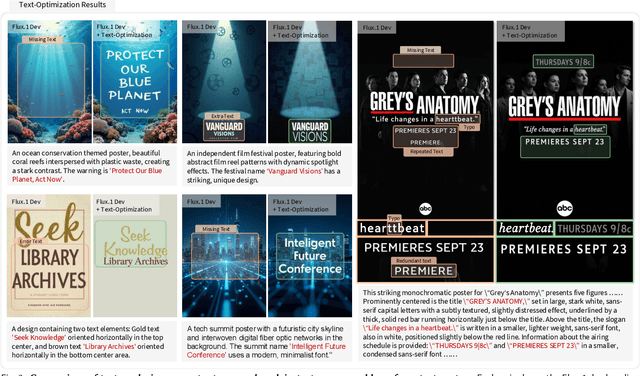
Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft
MMGT: Motion Mask Guided Two-Stage Network for Co-Speech Gesture Video Generation
May 29, 2025Co-Speech Gesture Video Generation aims to generate vivid speech videos from audio-driven still images, which is challenging due to the diversity of different parts of the body in terms of amplitude of motion, audio relevance, and detailed features. Relying solely on audio as the control signal often fails to capture large gesture movements in video, leading to more pronounced artifacts and distortions. Existing approaches typically address this issue by introducing additional a priori information, but this can limit the practical application of the task. Specifically, we propose a Motion Mask-Guided Two-Stage Network (MMGT) that uses audio, as well as motion masks and motion features generated from the audio signal to jointly drive the generation of synchronized speech gesture videos. In the first stage, the Spatial Mask-Guided Audio Pose Generation (SMGA) Network generates high-quality pose videos and motion masks from audio, effectively capturing large movements in key regions such as the face and gestures. In the second stage, we integrate the Motion Masked Hierarchical Audio Attention (MM-HAA) into the Stabilized Diffusion Video Generation model, overcoming limitations in fine-grained motion generation and region-specific detail control found in traditional methods. This guarantees high-quality, detailed upper-body video generation with accurate texture and motion details. Evaluations show improved video quality, lip-sync, and gesture. The model and code are available at https://github.com/SIA-IDE/MMGT.