 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelWizard: Towards Efficient High-Fidelity Video Generation at Ultra-Large Spatial Resolution
May 25, 2026High-resolution video generation faces a coupled bottleneck of optimization instability and prohibitive computational costs. The massive expansion of the token sequence not only biases optimization toward local textures at the expense of global coherence, leading to structural collapse, but also imposes prohibitive training costs and severe inference latency. To address this, we propose PixelWizard, a framework that hierarchically decouples global structure modeling from fine-grained detail synthesis. PixelWizard first establishes a compact spatiotemporal anchor to concentrate dense structural priors, which then guides fine-grained generation at high resolution. This mitigates the local optimization bias to ensure structural stability without compromising high-frequency details. Leveraging this structural stability, we introduce Noise-Span Aligned Shortcut Training to break the inference bottleneck. By explicitly modeling the step size, this mechanism allows the model to traverse the generation trajectory with large steps. Crucially, we incorporate Exponential Index-Biased Sampling and Adaptive Noise-Span Calibration to align optimization with the shifted noise schedules of high-resolution grids, ensuring robust few-step inference without incurring the heavy overhead of distillation. Extensive experiments demonstrate that PixelWizard achieves superior visual quality while accelerating the generative sampling of native 2K/4K videos by over 10x.
GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
May 20, 2026Open-ended image generation is no longer a simple prompt-to-image problem. High-quality generation often requires an agent to combine a model's internal generative ability with external resources. As requests become more diverse and demanding, we aim to develop a general image-generation agent that can self-evolve through trajectories and use tools more effectively across varied generation challenges. To this end, we propose GenEvolve, a self-evolving framework based on Tool-Orchestrated Visual Experience Distillation. In GenEvolve, each generation attempt is modeled as a tool-orchestrated trajectory, where the agent gathers evidence, selects references, invokes generation skills, and composes them into a prompt-reference program. Unlike existing agentic generation methods that mainly rely on image-level scalar rewards, GenEvolve compares multiple trajectories for the same request and abstracts best-worst differences into structured visual experience, provided only to a privileged teacher branch. Inspired by on-policy self-distillation, Visual Experience Distillation provides dense token-level supervision, helping the student internalize better search, knowledge activation, reference selection, and prompt construction. We further construct GenEvolve-Data and GenEvolve-Bench. Experiments on public benchmarks and GenEvolve-Bench show substantial gains over strong baselines, achieving state-of-the-art performance among current image-generation frameworks. Our website is as follows: https://ephemeral182.github.io/GenEvolve/
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
May 14, 2026We introduce SANA-WM, an efficient 2.6B-parameter open-source world model natively trained for one-minute generation, synthesizing high-fidelity, 720p, minute-scale videos with precise camera control. SANA-WM achieves visual quality comparable to large-scale industrial baselines such as LingBot-World and HY-WorldPlay, while significantly improving efficiency. Four core designs drive our architecture: (1) Hybrid Linear Attention combines frame-wise Gated DeltaNet (GDN) with softmax attention for memory-efficient long-context modeling. (2) Dual-Branch Camera Control ensures precise 6-DoF trajectory adherence. (3) Two-Stage Generation Pipeline applies a long-video refiner to stage-1 outputs, improving quality and consistency across sequences. (4) Robust Annotation Pipeline extracts accurate metric-scale 6-DoF camera poses from public videos to yield high-quality, spatiotemporally consistent action labels. Driven by these designs, SANA-WMdemonstrates remarkable efficiency across data, training compute, and inference hardware: it uses only $\sim$213K public video clips with metric-scale pose supervision, completes training in 15 days on 64 H100s, and generates each 60s clip on a single GPU; its distilled variant can be deployed on a single RTX 5090 with NVFP4 quantization to denoise a 60s 720p clip in 34s. On our one-minute world-model benchmark, SANA-WM demonstrates stronger action-following accuracy than prior open-source baselines and achieves comparable visual quality at $36\times$ higher throughput for scalable world modeling.
Masked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
PosterOmni: Generalized Artistic Poster Creation via Task Distillation and Unified Reward Feedback
Feb 12, 2026Image-to-poster generation is a high-demand task requiring not only local adjustments but also high-level design understanding. Models must generate text, layout, style, and visual elements while preserving semantic fidelity and aesthetic coherence. The process spans two regimes: local editing, where ID-driven generation, rescaling, filling, and extending must preserve concrete visual entities; and global creation, where layout- and style-driven tasks rely on understanding abstract design concepts. These intertwined demands make image-to-poster a multi-dimensional process coupling entity-preserving editing with concept-driven creation under image-prompt control. To address these challenges, we propose PosterOmni, a generalized artistic poster creation framework that unlocks the potential of a base edit model for multi-task image-to-poster generation. PosterOmni integrates the two regimes, namely local editing and global creation, within a single system through an efficient data-distillation-reward pipeline: (i) constructing multi-scenario image-to-poster datasets covering six task types across entity-based and concept-based creation; (ii) distilling knowledge between local and global experts for supervised fine-tuning; and (iii) applying unified PosterOmni Reward Feedback to jointly align visual entity-preserving and aesthetic preference across all tasks. Additionally, we establish PosterOmni-Bench, a unified benchmark for evaluating both local editing and global creation. Extensive experiments show that PosterOmni significantly enhances reference adherence, global composition quality, and aesthetic harmony, outperforming all open-source baselines and even surpassing several proprietary systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
LucidFlux: Caption-Free Universal Image Restoration via a Large-Scale Diffusion Transformer
Sep 26, 2025



Universal image restoration (UIR) aims to recover images degraded by unknown mixtures while preserving semantics -- conditions under which discriminative restorers and UNet-based diffusion priors often oversmooth, hallucinate, or drift. We present LucidFlux, a caption-free UIR framework that adapts a large diffusion transformer (Flux.1) without image captions. LucidFlux introduces a lightweight dual-branch conditioner that injects signals from the degraded input and a lightly restored proxy to respectively anchor geometry and suppress artifacts. Then, a timestep- and layer-adaptive modulation schedule is designed to route these cues across the backbone's hierarchy, in order to yield coarse-to-fine and context-aware updates that protect the global structure while recovering texture. After that, to avoid the latency and instability of text prompts or MLLM captions, we enforce caption-free semantic alignment via SigLIP features extracted from the proxy. A scalable curation pipeline further filters large-scale data for structure-rich supervision. Across synthetic and in-the-wild benchmarks, LucidFlux consistently outperforms strong open-source and commercial baselines, and ablation studies verify the necessity of each component. LucidFlux shows that, for large DiTs, when, where, and what to condition on -- rather than adding parameters or relying on text prompts -- is the governing lever for robust and caption-free universal image restoration in the wild.
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
Jul 03, 2025The challenge of long video understanding lies in its high computational complexity and prohibitive memory cost, since the memory and computation required by transformer-based LLMs scale quadratically with input sequence length. We propose AuroraLong to address this challenge by replacing the LLM component in MLLMs with a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states. To further increase throughput and efficiency, we combine visual token merge with linear RNN models by reordering the visual tokens by their sizes in ascending order. Despite having only 2B parameters and being trained exclusively on public data, AuroraLong achieves performance comparable to Transformer-based models of similar size trained on private datasets across multiple video benchmarks. This demonstrates the potential of efficient, linear RNNs to democratize long video understanding by lowering its computational entry barrier. To our best knowledge, we are the first to use a linear RNN based LLM backbone in a LLaVA-like model for open-ended video understanding.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025
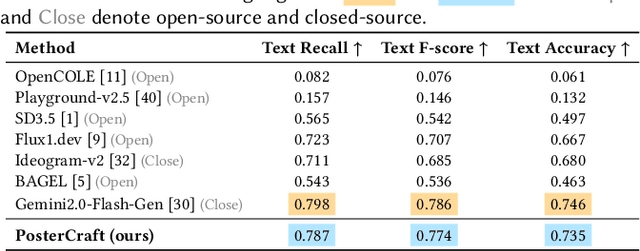
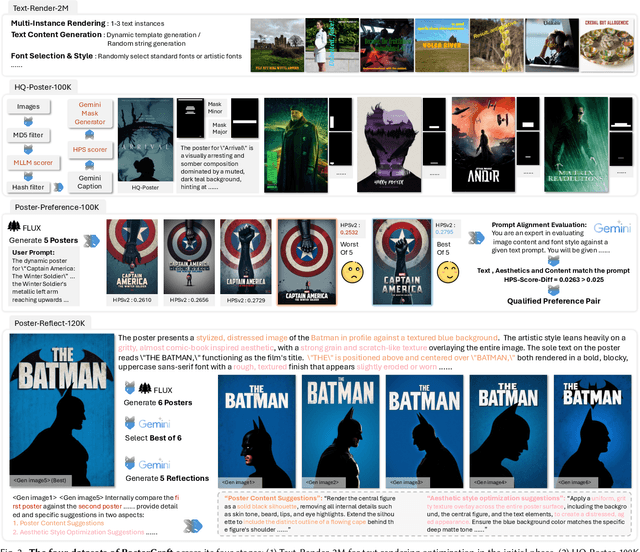
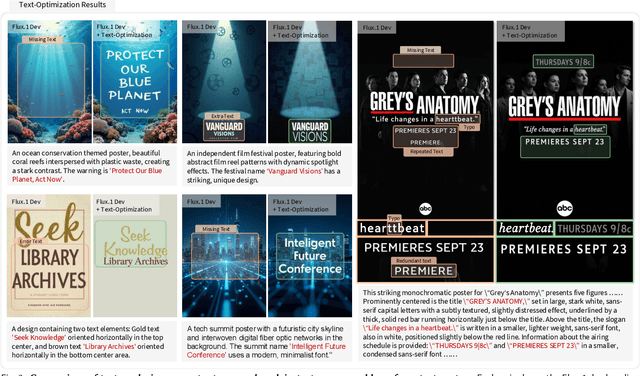
Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft