 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaORE: Reasoning-Guided Progressive Open Relation Extraction Empowered by Large Reasoning Models
Jun 25, 2026Open Relation Extraction (OpenRE) requires a model to extract unseen relations between head and tail entities from unstructured text for real-world applications. The core challenge of OpenRE lies in achieving reliable generalization to unseen relation types. Current OpenRE approaches either employ clustering techniques, which cannot generate relation labels and suffer from poor generalization, or rely on direct relation label generation via Large Language Models (LLMs), which lack sufficient discriminative capacity to distinguish easily confused relations. To address these limitations, we propose Reasoning-guided progressive OpenRE (ReaORE), a framework for performing relation extraction through coarse-to-fine relation reasoning. Specifically, ReaORE consists of two key stages: (i) relation filtering, which reasons over multiple aspects to understand relations and instances, yielding an initial relation set, and further supplements and filters relations via embedding-based similarity to ensure the target relation is included; (ii) relation prediction, which aims to predict the target relations from the above set via fine-grained comparative reasoning to better distinguish easily confused relations. Extensive experiments on two widely used OpenRE datasets demonstrate that ReaORE outperforms existing baselines.
PanoWorld: Towards Spatial Supersensing in 360$^\circ$ Panorama World
May 13, 2026Multimodal large laboratory models (MLLMs) still struggle with spatial understanding under the dominant perspective-image paradigm, which inherits the narrow field of view of human-like perception. For navigation, robotic search, and 3D scene understanding, 360-degree panoramic sensing offers a form of supersensing by capturing the entire surrounding environment at once. However, existing MLLM pipelines typically decompose panoramas into multiple perspective views, leaving the spherical structure of equirectangular projection (ERP) largely implicit. In this paper, we study pano-native understanding, which requires an MLLM to reason over an ERP panorama as a continuous, observer-centered space. To this end, we first define the key abilities for pano-native understanding, including semantic anchoring, spherical localization, reference-frame transformation, and depth-aware 3D spatial reasoning. We then build a large-scale metadata construction pipeline that converts mixed-source ERP panoramas into geometry-aware, language-grounded, and depth-aware supervision, and instantiate these signals as capability-aligned instruction tuning data. On the model side, we introduce PanoWorld with Spherical Spatial Cross-Attention, which injects spherical geometry into the visual stream. We further construct PanoSpace-Bench, a diagnostic benchmark for evaluating ERP-native spatial reasoning. Experiments show that PanoWorld substantially outperforms both proprietary and open-source baselines on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen benchmarks. These results demonstrate that robust panoramic reasoning requires dedicated pano-native supervision and geometry-aware model adaptation. All source code and proposed data will be publicly released.
OmniRoam: World Wandering via Long-Horizon Panoramic Video Generation
Mar 31, 2026Modeling scenes using video generation models has garnered growing research interest in recent years. However, most existing approaches rely on perspective video models that synthesize only limited observations of a scene, leading to issues of completeness and global consistency. We propose OmniRoam, a controllable panoramic video generation framework that exploits the rich per-frame scene coverage and inherent long-term spatial and temporal consistency of panoramic representation, enabling long-horizon scene wandering. Our framework begins with a preview stage, where a trajectory-controlled video generation model creates a quick overview of the scene from a given input image or video. Then, in the refine stage, this video is temporally extended and spatially upsampled to produce long-range, high-resolution videos, thus enabling high-fidelity world wandering. To train our model, we introduce two panoramic video datasets that incorporate both synthetic and real-world captured videos. Experiments show that our framework consistently outperforms state-of-the-art methods in terms of visual quality, controllability, and long-term scene consistency, both qualitatively and quantitatively. We further showcase several extensions of this framework, including real-time video generation and 3D reconstruction. Code is available at https://github.com/yuhengliu02/OmniRoam.
Evolutionary Biparty Multiobjective UAV Path Planning: Problems and Empirical Comparisons
Mar 23, 2026Unmanned aerial vehicles (UAVs) have been widely used in urban missions, and proper planning of UAV paths can improve mission efficiency while reducing the risk of potential third-party impact. Existing work has considered all efficiency and safety objectives for a single decision-maker (DM) and regarded this as a multiobjective optimization problem (MOP). However, there is usually not a single DM but two DMs, i.e., an efficiency DM and a safety DM, and the DMs are only concerned with their respective objectives. The final decision is made based on the solutions of both DMs. In this paper, for the first time, biparty multiobjective UAV path planning (BPMO-UAVPP) problems involving both efficiency and safety departments are modeled. The existing multiobjective immune algorithm with nondominated neighbor-based selection (NNIA), the hybrid evolutionary framework for the multiobjective immune algorithm (HEIA), and the adaptive immune-inspired multiobjective algorithm (AIMA) are modified for solving the BPMO-UAVPP problem, and then biparty multiobjective optimization algorithms, including the BPNNIA, BPHEIA, and BPAIMA, are proposed and comprehensively compared with traditional multiobjective evolutionary algorithms and typical multiparty multiobjective evolutionary algorithms (i.e., OptMPNDS and OptMPNDS2). The experimental results show that BPAIMA performs better than ordinary multiobjective evolutionary algorithms such as NSGA-II and multiparty multiobjective evolutionary algorithms such as OptMPNDS, OptMPNDS2, BPNNIA and BPHEIA.
* \c{opyright} 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Toward a Multi-View Brain Network Foundation Model: Cross-View Consistency Learning Across Arbitrary Atlases
Mar 20, 2026Brain network analysis provides an interpretable framework for characterizing brain organization and has been widely used for neurological disorder identification. Recent advances in self-supervised learning have motivated the development of brain network foundation models. However, existing approaches are often limited by atlas dependency, insufficient exploitation of multiple network views, and weak incorporation of anatomical priors. In this work, we propose MV-BrainFM, a multi-view brain network foundation model designed to learn generalizable and scalable representations from brain networks constructed with arbitrary atlases. MV-BrainFM explicitly incorporates anatomical distance information into Transformer-based modeling to guide inter-regional interactions, and introduces an unsupervised cross-view consistency learning strategy to align representations from multiple atlases of the same subject in a shared latent space. By jointly enforcing within-view robustness and cross-view alignment during pretraining, the model effectively captures complementary information across heterogeneous network views while remaining atlas-aware. In addition, MV-BrainFM adopts a unified multi-view pretraining paradigm that enables simultaneous learning from multiple datasets and atlases, significantly improving computational efficiency compared to conventional sequential training strategies. The proposed framework also demonstrates strong scalability, consistently benefiting from increasing data diversity while maintaining stable performance across unseen atlas configurations. Extensive experiments on more than 20K subjects from 17 fMRI datasets show that MV-BrainFM consistently outperforms 14 existing brain network foundation models and task-specific baselines under both single-atlas and multi-atlas settings.
PhysGraph: Physically-Grounded Graph-Transformer Policies for Bimanual Dexterous Hand-Tool-Object Manipulation
Mar 02, 2026Bimanual dexterous manipulation for tool use remains a formidable challenge in robotics due to the high-dimensional state space and complicated contact dynamics. Existing methods naively represent the entire system state as a single configuration vector, disregarding the rich structural and topological information inherent to articulated hands. We present PhysGraph, a physically-grounded graph transformer policy designed explicitly for challenging bimanual hand-tool-object manipulation. Unlike prior works, we represent the bimanual system as a kinematic graph and introduce per-link tokenization to preserve fine-grained local state information. We propose a physically-grounded bias generator that injects structural priors directly into the attention mechanism, including kinematic spatial distance, dynamic contact states, geometric proximity, and anatomical properties. This allows the policy to explicitly reason about physical interactions rather than learning them implicitly from sparse rewards. Extensive experiments show that PhysGraph significantly outperforms baseline - ManipTrans in manipulation precision and task success rates while using only 51% of the parameters of ManipTrans. Furthermore, the inherent topological flexibility of our architecture shows qualitative zero-shot transfer to unseen tool/object geometries, and is sufficiently general to be trained on three robotic hands (Shadow, Allegro, Inspire).
Two-Scale Spatial Deployment for Cost-Effective Wireless Networks via Cooperative IRSs and Movable Antennas
Jan 14, 2026This paper proposes a two-scale spatial deployment strategy to ensure reliable coverage for multiple target areas, integrating macroscopic intelligent reflecting surfaces (IRSs) and fine-grained movable antennas (MAs). Specifically, IRSs are selectively deployed from candidate sites to shape the propagation geometry, while MAs are locally repositioned among discretized locations to exploit small-scale channel variations. The objective is to minimize the total deployment cost of MAs and IRSs by jointly optimizing the IRS site selection, MA positions, transmit precoding, and IRS phase shifts, subject to the signal-to-noise ratio (SNR) requirements for all target areas. This leads to a challenging mixed-integer non-convex optimization problem that is intractable to solve directly. To address this, we first formulate an auxiliary problem to verify the feasibility. A penalty-based double-loop algorithm integrating alternating optimization and successive convex approximation (SCA) is developed to solve this feasibility issue, which is subsequently adapted to obtain a suboptimal solution for the original cost minimization problem. Finally, based on the obtained solution, we formulate an element refinement problem to further reduce the deployment cost, which is solved by a penalty-based SCA algorithm. Simulation results demonstrate that the proposed designs consistently outperform benchmarks relying on independent area planning or full IRS deployment in terms of cost-efficiency. Moreover, for cost minimization, MA architectures are preferable in large placement apertures, whereas fully populated FPA architectures excel in compact ones; for worst-case SNR maximization, MA architectures exhibit a lower cost threshold for feasibility, while FPA architectures can attain peak SNR at a lower total cost.
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Dec 18, 2025
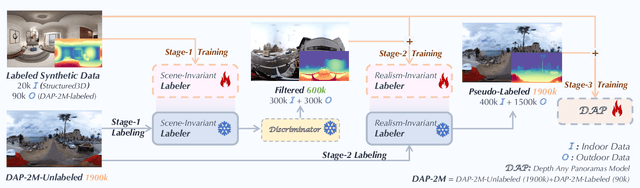

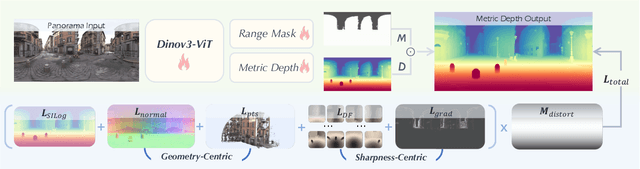
In this work, we present a panoramic metric depth foundation model that generalizes across diverse scene distances. We explore a data-in-the-loop paradigm from the view of both data construction and framework design. We collect a large-scale dataset by combining public datasets, high-quality synthetic data from our UE5 simulator and text-to-image models, and real panoramic images from the web. To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline to generate reliable ground truth for unlabeled images. For the model, we adopt DINOv3-Large as the backbone for its strong pre-trained generalization, and introduce a plug-and-play range mask head, sharpness-centric optimization, and geometry-centric optimization to improve robustness to varying distances and enforce geometric consistency across views. Experiments on multiple benchmarks (e.g., Stanford2D3D, Matterport3D, and Deep360) demonstrate strong performance and zero-shot generalization, with particularly robust and stable metric predictions in diverse real-world scenes. The project page can be found at: \href{https://insta360-research-team.github.io/DAP_website/} {https://insta360-research-team.github.io/DAP\_website/}
SMRC: Aligning Large Language Models with Student Reasoning for Mathematical Error Correction
Nov 18, 2025Large language models (LLMs) often make reasoning errors when solving mathematical problems, and how to automatically detect and correct these errors has become an important research direction. However, existing approaches \textit{mainly focus on self-correction within the model}, which falls short of the ``teacher-style`` correction required in educational settings, \textit{i.e.}, systematically guiding and revising a student's problem-solving process. To address this gap, we propose \texttt{SMRC} (\textit{\underline{S}tudent \underline{M}athematical \underline{R}easoning \underline{C}orrection}), a novel method that aligns LLMs with student reasoning. Specifically, \texttt{SMRC} formulates student reasoning as a multi-step sequential decision problem and introduces Monte Carlo Tree Search (MCTS) to explore optimal correction paths. To reduce the cost of the annotating process-level rewards, we leverage breadth-first search (BFS) guided by LLMs and final-answer evaluation to generate reward signals, which are then distributed across intermediate reasoning steps via a back-propagation mechanism, enabling fine-grained process supervision. Additionally, we construct a benchmark for high school mathematics, MSEB (Multi-Solution Error Benchmark), consisting of 158 instances that include problem statements, student solutions, and correct reasoning steps. We further propose a dual evaluation protocol centered on \textbf{solution accuracy} and \textbf{correct-step retention}, offering a comprehensive measure of educational applicability. Experiments demonstrate that \texttt{SMRC} significantly outperforms existing methods on two public datasets (ProcessBench and MR-GSM8K) and our MSEB in terms of effectiveness and overall performance. The code and data are available at https://github.com/Mind-Lab-ECNU/SMRC.
Enhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.