 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp as You Dream: Imitating Functional Grasping from Generated Human Demonstrations
Apr 08, 2026Building generalist robots capable of performing functional grasping in everyday, open-world environments remains a significant challenge due to the vast diversity of objects and tasks. Existing methods are either constrained to narrow object/task sets or rely on prohibitively large-scale data collection to capture real-world variability. In this work, we present an alternative approach, GraspDreamer, a method that leverages human demonstrations synthesized by visual generative models (VGMs) (e.g., video generation models) to enable zero-shot functional grasping without labor-intensive data collection. The key idea is that VGMs pre-trained on internet-scale human data implicitly encode generalized priors about how humans interact with the physical world, which can be combined with embodiment-specific action optimization to enable functional grasping with minimal effort. Extensive experiments on the public benchmarks with different robot hands demonstrate the superior data efficiency and generalization performance of GraspDreamer compared to previous methods. Real-world evaluations further validate the effectiveness on real robots. Additionally, we showcase that GraspDreamer can (1) be naturally extended to downstream manipulation tasks, and (2) can generate data to support visuomotor policy learning.
Easy-IIL: Reducing Human Operational Burden in Interactive Imitation Learning via Assistant Experts
Mar 13, 2026Interactive Imitation Learning (IIL) typically relies on extensive human involvement for both offline demonstration and online interaction. Prior work primarily focuses on reducing human effort in passive monitoring rather than active operation. Interestingly, structured model-based imitation approaches achieve comparable performance with significantly fewer demonstrations than end-to-end imitation learning policies in the low-data regime. However, these methods are typically surpassed by end-to-end policies as the data increases. Leveraging this insight, we propose Easy-IIL, a framework that utilizes off-the-shelf model-based imitation methods as an assistant expert to replace active human operation for the majority of data collection. The human expert only provides a single demonstration to initialize the assistant expert and intervenes in critical states where the task is approaching failure. Furthermore, Easy-IIL can maintain IIL performance by preserving both offline and online data quality. Extensive simulation and real-world experiments demonstrate that Easy-IIL significantly reduces human operational burden while maintaining performance comparable to mainstream IIL baselines. User studies further confirm that Easy-IIL reduces subjective workload on the human expert. Project page: https://sites.google.com/view/easy-iil
Transient learning dynamics drive escape from sharp valleys in Stochastic Gradient Descent
Jan 16, 2026Stochastic gradient descent (SGD) is central to deep learning, yet the dynamical origin of its preference for flatter, more generalizable solutions remains unclear. Here, by analyzing SGD learning dynamics, we identify a nonequilibrium mechanism governing solution selection. Numerical experiments reveal a transient exploratory phase in which SGD trajectories repeatedly escape sharp valleys and transition toward flatter regions of the loss landscape. By using a tractable physical model, we show that the SGD noise reshapes the landscape into an effective potential that favors flat solutions. Crucially, we uncover a transient freezing mechanism: as training proceeds, growing energy barriers suppress inter-valley transitions and ultimately trap the dynamics within a single basin. Increasing the SGD noise strength delays this freezing, which enhances convergence to flatter minima. Together, these results provide a unified physical framework linking learning dynamics, loss-landscape geometry, and generalization, and suggest principles for the design of more effective optimization algorithms.
DeepInverse: A Python package for solving imaging inverse problems with deep learning
May 26, 2025DeepInverse is an open-source PyTorch-based library for solving imaging inverse problems. The library covers all crucial steps in image reconstruction from the efficient implementation of forward operators (e.g., optics, MRI, tomography), to the definition and resolution of variational problems and the design and training of advanced neural network architectures. In this paper, we describe the main functionality of the library and discuss the main design choices.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
Dexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
The R2D2 Deep Neural Network Series for Scalable Non-Cartesian Magnetic Resonance Imaging
Mar 13, 2025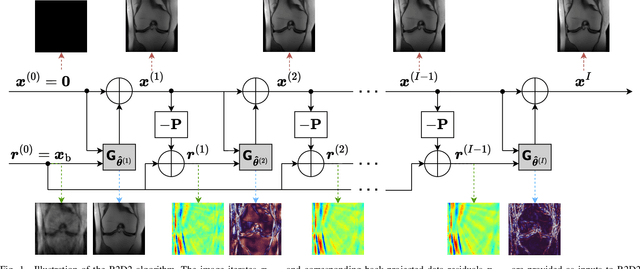
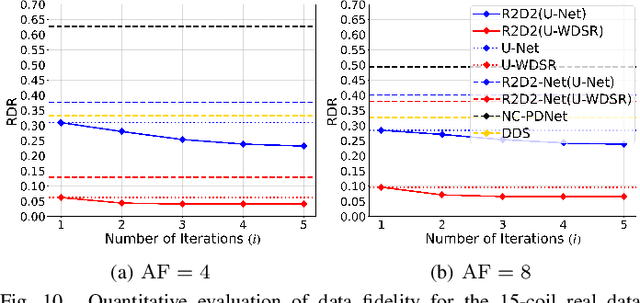
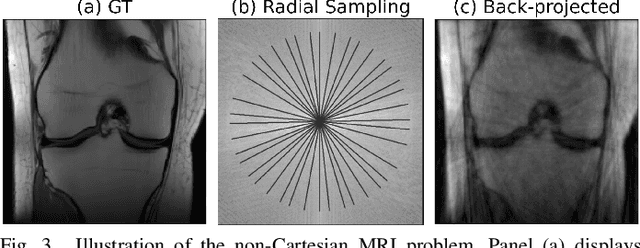
We introduce the R2D2 Deep Neural Network (DNN) series paradigm for fast and scalable image reconstruction from highly-accelerated non-Cartesian k-space acquisitions in Magnetic Resonance Imaging (MRI). While unrolled DNN architectures provide a robust image formation approach via data-consistency layers, embedding non-uniform fast Fourier transform operators in a DNN can become impractical to train at large scale, e.g in 2D MRI with a large number of coils, or for higher-dimensional imaging. Plug-and-play approaches that alternate a learned denoiser blind to the measurement setting with a data-consistency step are not affected by this limitation but their highly iterative nature implies slow reconstruction. To address this scalability challenge, we leverage the R2D2 paradigm that was recently introduced to enable ultra-fast reconstruction for large-scale Fourier imaging in radio astronomy. R2D2's reconstruction is formed as a series of residual images iteratively estimated as outputs of DNN modules taking the previous iteration's data residual as input. The method can be interpreted as a learned version of the Matching Pursuit algorithm. A series of R2D2 DNN modules were sequentially trained in a supervised manner on the fastMRI dataset and validated for 2D multi-coil MRI in simulation and on real data, targeting highly under-sampled radial k-space sampling. Results suggest that a series with only few DNNs achieves superior reconstruction quality over its unrolled incarnation R2D2-Net (whose training is also much less scalable), and over the state-of-the-art diffusion-based "Decomposed Diffusion Sampler" approach (also characterised by a slower reconstruction process).
FlowPlan: Zero-Shot Task Planning with LLM Flow Engineering for Robotic Instruction Following
Mar 04, 2025Robotic instruction following tasks require seamless integration of visual perception, task planning, target localization, and motion execution. However, existing task planning methods for instruction following are either data-driven or underperform in zero-shot scenarios due to difficulties in grounding lengthy instructions into actionable plans under operational constraints. To address this, we propose FlowPlan, a structured multi-stage LLM workflow that elevates zero-shot pipeline and bridges the performance gap between zero-shot and data-driven in-context learning methods. By decomposing the planning process into modular stages--task information retrieval, language-level reasoning, symbolic-level planning, and logical evaluation--FlowPlan generates logically coherent action sequences while adhering to operational constraints and further extracts contextual guidance for precise instance-level target localization. Benchmarked on the ALFRED and validated in real-world applications, our method achieves competitive performance relative to data-driven in-context learning methods and demonstrates adaptability across diverse environments. This work advances zero-shot task planning in robotic systems without reliance on labeled data. Project website: https://instruction-following-project.github.io/.
Towards a robust R2D2 paradigm for radio-interferometric imaging: revisiting DNN training and architecture
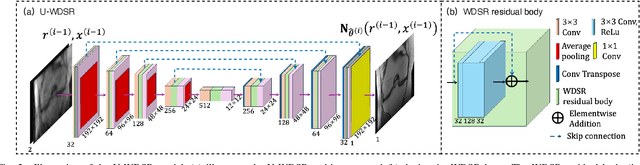
Mar 04, 2025The R2D2 Deep Neural Network (DNN) series was recently introduced for image formation in radio interferometry. It can be understood as a learned version of CLEAN, whose minor cycles are substituted with DNNs. We revisit R2D2 on the grounds of series convergence, training methodology, and DNN architecture, improving its robustness in terms of generalisability beyond training conditions, capability to deliver high data fidelity, and epistemic uncertainty. Firstly, while still focusing on telescope-specific training, we enhance the learning process by randomising Fourier sampling integration times, incorporating multi-scan multi-noise configurations, and varying imaging settings, including pixel resolution and visibility-weighting scheme. Secondly, we introduce a convergence criterion whereby the reconstruction process stops when the data residual is compatible with noise, rather than simply using all available DNNs. This not only increases the reconstruction efficiency by reducing its computational cost, but also refines training by pruning out the data/image pairs for which optimal data fidelity is reached before training the next DNN. Thirdly, we substitute R2D2's early U-Net DNN with a novel architecture (U-WDSR) combining U-Net and WDSR, which leverages wide activation, dense connections, weight normalisation, and low-rank convolution to improve feature reuse and reconstruction precision. As previously, R2D2 was trained for monochromatic intensity imaging with the Very Large Array (VLA) at fixed $512 \times 512$ image size. Simulations on a wide range of inverse problems and a case study on real data reveal that the new R2D2 model consistently outperforms its earlier version in image reconstruction quality, data fidelity, and epistemic uncertainty.
FUNCTO: Function-Centric One-Shot Imitation Learning for Tool Manipulation
Feb 17, 2025



Learning tool use from a single human demonstration video offers a highly intuitive and efficient approach to robot teaching. While humans can effortlessly generalize a demonstrated tool manipulation skill to diverse tools that support the same function (e.g., pouring with a mug versus a teapot), current one-shot imitation learning (OSIL) methods struggle to achieve this. A key challenge lies in establishing functional correspondences between demonstration and test tools, considering significant geometric variations among tools with the same function (i.e., intra-function variations). To address this challenge, we propose FUNCTO (Function-Centric OSIL for Tool Manipulation), an OSIL method that establishes function-centric correspondences with a 3D functional keypoint representation, enabling robots to generalize tool manipulation skills from a single human demonstration video to novel tools with the same function despite significant intra-function variations. With this formulation, we factorize FUNCTO into three stages: (1) functional keypoint extraction, (2) function-centric correspondence establishment, and (3) functional keypoint-based action planning. We evaluate FUNCTO against exiting modular OSIL methods and end-to-end behavioral cloning methods through real-robot experiments on diverse tool manipulation tasks. The results demonstrate the superiority of FUNCTO when generalizing to novel tools with intra-function geometric variations. More details are available at https://sites.google.com/view/functo.