 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Predictive Control for Manipulation Planning and Trajectory Generation
Apr 07, 2025



Model Predictive Control (MPC) is a widely adopted control paradigm that leverages predictive models to estimate future system states and optimize control inputs accordingly. However, while MPC excels in planning and control, it lacks the capability for environmental perception, leading to failures in complex and unstructured scenarios. To address this limitation, we introduce Vision-Language Model Predictive Control (VLMPC), a robotic manipulation planning framework that integrates the perception power of vision-language models (VLMs) with MPC. VLMPC utilizes a conditional action sampling module that takes a goal image or language instruction as input and leverages VLM to generate candidate action sequences. These candidates are fed into a video prediction model that simulates future frames based on the actions. In addition, we propose an enhanced variant, Traj-VLMPC, which replaces video prediction with motion trajectory generation to reduce computational complexity while maintaining accuracy. Traj-VLMPC estimates motion dynamics conditioned on the candidate actions, offering a more efficient alternative for long-horizon tasks and real-time applications. Both VLMPC and Traj-VLMPC select the optimal action sequence using a VLM-based hierarchical cost function that captures both pixel-level and knowledge-level consistency between the current observation and the task input. We demonstrate that both approaches outperform existing state-of-the-art methods on public benchmarks and achieve excellent performance in various real-world robotic manipulation tasks. Code is available at https://github.com/PPjmchen/VLMPC.
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Apr 05, 2025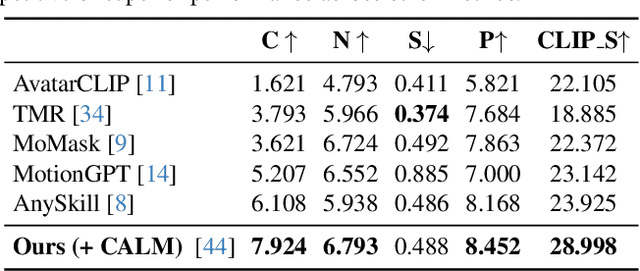
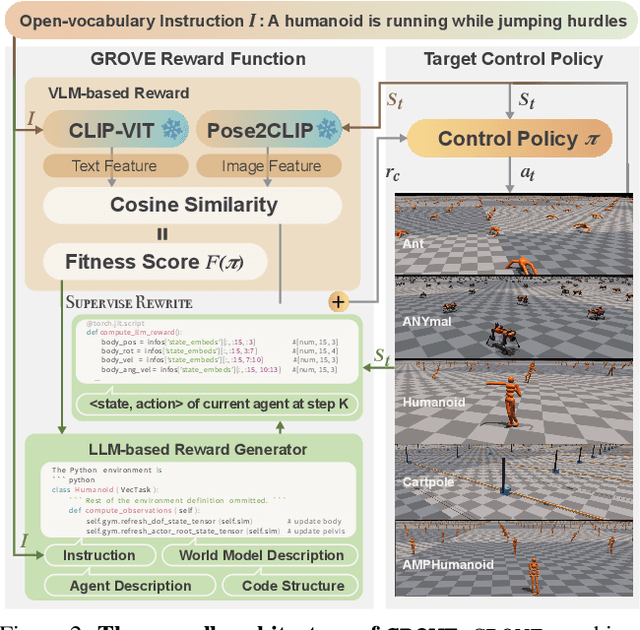
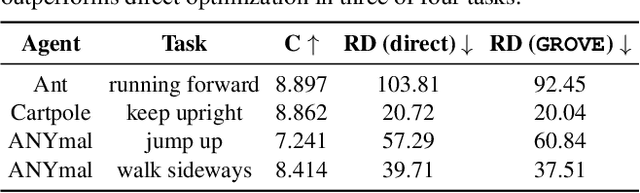

Learning open-vocabulary physical skills for simulated agents presents a significant challenge in artificial intelligence. Current reinforcement learning approaches face critical limitations: manually designed rewards lack scalability across diverse tasks, while demonstration-based methods struggle to generalize beyond their training distribution. We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations. Our key insight is that Large Language Models(LLMs) and Vision Language Models(VLMs) provide complementary guidance -- LLMs generate precise physical constraints capturing task requirements, while VLMs evaluate motion semantics and naturalness. Through an iterative design process, VLM-based feedback continuously refines LLM-generated constraints, creating a self-improving reward system. To bridge the domain gap between simulation and natural images, we develop Pose2CLIP, a lightweight mapper that efficiently projects agent poses directly into semantic feature space without computationally expensive rendering. Extensive experiments across diverse embodiments and learning paradigms demonstrate GROVE's effectiveness, achieving 22.2% higher motion naturalness and 25.7% better task completion scores while training 8.4x faster than previous methods. These results establish a new foundation for scalable physical skill acquisition in simulated environments.
Dexterous Manipulation through Imitation Learning: A Survey
Apr 04, 2025Dexterous manipulation, which refers to the ability of a robotic hand or multi-fingered end-effector to skillfully control, reorient, and manipulate objects through precise, coordinated finger movements and adaptive force modulation, enables complex interactions similar to human hand dexterity. With recent advances in robotics and machine learning, there is a growing demand for these systems to operate in complex and unstructured environments. Traditional model-based approaches struggle to generalize across tasks and object variations due to the high-dimensionality and complex contact dynamics of dexterous manipulation. Although model-free methods such as reinforcement learning (RL) show promise, they require extensive training, large-scale interaction data, and carefully designed rewards for stability and effectiveness. Imitation learning (IL) offers an alternative by allowing robots to acquire dexterous manipulation skills directly from expert demonstrations, capturing fine-grained coordination and contact dynamics while bypassing the need for explicit modeling and large-scale trial-and-error. This survey provides an overview of dexterous manipulation methods based on imitation learning (IL), details recent advances, and addresses key challenges in the field. Additionally, it explores potential research directions to enhance IL-driven dexterous manipulation. Our goal is to offer researchers and practitioners a comprehensive introduction to this rapidly evolving domain.
StyleLoco: Generative Adversarial Distillation for Natural Humanoid Robot Locomotion
Mar 19, 2025
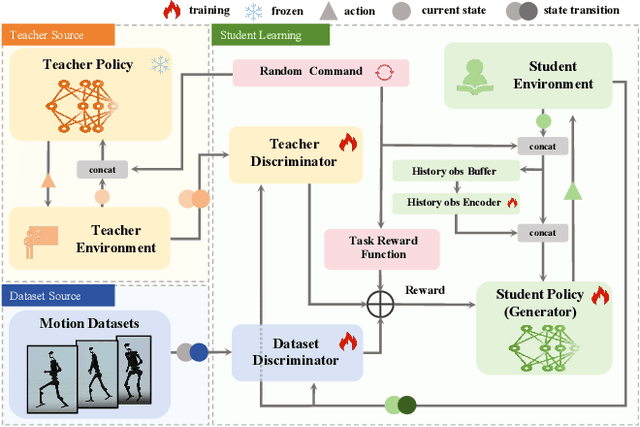


Humanoid robots are anticipated to acquire a wide range of locomotion capabilities while ensuring natural movement across varying speeds and terrains. Existing methods encounter a fundamental dilemma in learning humanoid locomotion: reinforcement learning with handcrafted rewards can achieve agile locomotion but produces unnatural gaits, while Generative Adversarial Imitation Learning (GAIL) with motion capture data yields natural movements but suffers from unstable training processes and restricted agility. Integrating these approaches proves challenging due to the inherent heterogeneity between expert policies and human motion datasets. To address this, we introduce StyleLoco, a novel two-stage framework that bridges this gap through a Generative Adversarial Distillation (GAD) process. Our framework begins by training a teacher policy using reinforcement learning to achieve agile and dynamic locomotion. It then employs a multi-discriminator architecture, where distinct discriminators concurrently extract skills from both the teacher policy and motion capture data. This approach effectively combines the agility of reinforcement learning with the natural fluidity of human-like movements while mitigating the instability issues commonly associated with adversarial training. Through extensive simulation and real-world experiments, we demonstrate that StyleLoco enables humanoid robots to perform diverse locomotion tasks with the precision of expertly trained policies and the natural aesthetics of human motion, successfully transferring styles across different movement types while maintaining stable locomotion across a broad spectrum of command inputs.
HIF: Height Interval Filtering for Efficient Dynamic Points Removal
Mar 10, 20253D point cloud mapping plays a essential role in localization and autonomous navigation. However, dynamic objects often leave residual traces during the map construction process, which undermine the performance of subsequent tasks. Therefore, dynamic object removal has become a critical challenge in point cloud based map construction within dynamic scenarios. Existing approaches, however, often incur significant computational overhead, making it difficult to meet the real-time processing requirements. To address this issue, we introduce the Height Interval Filtering (HIF) method. This approach constructs pillar-based height interval representations to probabilistically model the vertical dimension, with interval probabilities updated through Bayesian inference. It ensures real-time performance while achieving high accuracy and improving robustness in complex environments. Additionally, we propose a low-height preservation strategy that enhances the detection of unknown spaces, reducing misclassification in areas blocked by obstacles (occluded regions). Experiments on public datasets demonstrate that HIF delivers a 7.7 times improvement in time efficiency with comparable accuracy to existing SOTA methods. The code will be publicly available.
Integrating Controllable Motion Skills from Demonstrations
Aug 06, 2024



The expanding applications of legged robots require their mastery of versatile motion skills. Correspondingly, researchers must address the challenge of integrating multiple diverse motion skills into controllers. While existing reinforcement learning (RL)-based approaches have achieved notable success in multi-skill integration for legged robots, these methods often require intricate reward engineering or are restricted to integrating a predefined set of motion skills constrained by specific task objectives, resulting in limited flexibility. In this work, we introduce a flexible multi-skill integration framework named Controllable Skills Integration (CSI). CSI enables the integration of a diverse set of motion skills with varying styles into a single policy without the need for complex reward tuning. Furthermore, in a hierarchical control manner, the trained low-level policy can be coupled with a high-level Natural Language Inference (NLI) module to enable preliminary language-directed skill control. Our experiments demonstrate that CSI can flexibly integrate a diverse array of motion skills more comprehensively and facilitate the transitions between different skills. Additionally, CSI exhibits good scalability as the number of motion skills to be integrated increases significantly.
VLMPC: Vision-Language Model Predictive Control for Robotic Manipulation
Jul 13, 2024Although Model Predictive Control (MPC) can effectively predict the future states of a system and thus is widely used in robotic manipulation tasks, it does not have the capability of environmental perception, leading to the failure in some complex scenarios. To address this issue, we introduce Vision-Language Model Predictive Control (VLMPC), a robotic manipulation framework which takes advantage of the powerful perception capability of vision language model (VLM) and integrates it with MPC. Specifically, we propose a conditional action sampling module which takes as input a goal image or a language instruction and leverages VLM to sample a set of candidate action sequences. Then, a lightweight action-conditioned video prediction model is designed to generate a set of future frames conditioned on the candidate action sequences. VLMPC produces the optimal action sequence with the assistance of VLM through a hierarchical cost function that formulates both pixel-level and knowledge-level consistence between the current observation and the goal image. We demonstrate that VLMPC outperforms the state-of-the-art methods on public benchmarks. More importantly, our method showcases excellent performance in various real-world tasks of robotic manipulation. Code is available at~\url{https://github.com/PPjmchen/VLMPC}.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.