 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniClone: Engineering a Robust, All-Rounder Whole-Body Humanoid Teleoperation System
Mar 15, 2026Whole-body humanoid teleoperation enables humans to remotely control humanoid robots, serving as both a real-time operational tool and a scalable engine for collecting demonstrations for autonomous learning. Despite recent advances, existing systems are validated using aggregate metrics that conflate distinct motion regimes, masking critical failure modes. This lack of diagnostic granularity, compounded by tightly coupled and labor-intensive system configurations, hinders robust real-world deployment. A key open challenge is building a teleoperation system that is simultaneously robust, versatile, and affordable for practical use. Here we present OmniClone, a whole-body humanoid teleoperation system that achieves high-fidelity, multi-skill control on a single consumer GPU with modest data requirements. Central to our approach is OmniBench, a diagnostic benchmark that evaluates policies across stratified motion categories and difficulty levels on unseen motions, exposing the narrow specialization of prior systems. Guided by these diagnostics, we identify an optimized training data recipe and integrate system-level improvements: subject-agnostic retargeting and robust communication, that collectively reduce Mean Per-Joint Position Error (MPJPE) by over 66% while requiring orders-of-magnitude fewer computational resources than comparable methods. Crucially, OmniClone is control-source-agnostic: a single unified policy supports real-time teleoperation, generated motion playback, and Vision-Language-Action (VLA) models, while generalizing across operators of vastly different body proportions. By uniting diagnostic evaluation with practical engineering, OmniClone provides an accessible foundation for scalable humanoid teleoperation and autonomous learning.
LessMimic: Long-Horizon Humanoid Interaction with Unified Distance Field Representations
Feb 25, 2026Humanoid robots that autonomously interact with physical environments over extended horizons represent a central goal of embodied intelligence. Existing approaches rely on reference motions or task-specific rewards, tightly coupling policies to particular object geometries and precluding multi-skill generalization within a single framework. A unified interaction representation enabling reference-free inference, geometric generalization, and long-horizon skill composition within one policy remains an open challenge. Here we show that Distance Field (DF) provides such a representation: LessMimic conditions a single whole-body policy on DF-derived geometric cues--surface distances, gradients, and velocity decompositions--removing the need for motion references, with interaction latents encoded via a Variational Auto-Encoder (VAE) and post-trained using Adversarial Interaction Priors (AIP) under Reinforcement Learning (RL). Through DAgger-style distillation that aligns DF latents with egocentric depth features, LessMimic further transfers seamlessly to vision-only deployment without motion capture (MoCap) infrastructure. A single LessMimic policy achieves 80--100% success across object scales from 0.4x to 1.6x on PickUp and SitStand where baselines degrade sharply, attains 62.1% success on 5 task instances trajectories, and remains viable up to 40 sequentially composed tasks. By grounding interaction in local geometry rather than demonstrations, LessMimic offers a scalable path toward humanoid robots that generalize, compose skills, and recover from failures in unstructured environments.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Dec 30, 2025A long-standing objective in humanoid robotics is the realization of versatile agents capable of following diverse multimodal instructions with human-level flexibility. Despite advances in humanoid control, bridging high-level multimodal perception with whole-body execution remains a significant bottleneck. Existing methods often struggle to translate heterogeneous instructions -- such as language, music, and trajectories -- into stable, real-time actions. Here we show that UniAct, a two-stage framework integrating a fine-tuned MLLM with a causal streaming pipeline, enables humanoid robots to execute multimodal instructions with sub-500 ms latency. By unifying inputs through a shared discrete codebook via FSQ, UniAct ensures cross-modal alignment while constraining motions to a physically grounded manifold. This approach yields a 19% improvement in the success rate of zero-shot tracking of imperfect reference motions. We validate UniAct on UniMoCap, our 20-hour humanoid motion benchmark, demonstrating robust generalization across diverse real-world scenarios. Our results mark a critical step toward responsive, general-purpose humanoid assistants capable of seamless interaction through unified perception and control.
CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
Jun 10, 2025Humanoid teleoperation plays a vital role in demonstrating and collecting data for complex humanoid-scene interactions. However, current teleoperation systems face critical limitations: they decouple upper- and lower-body control to maintain stability, restricting natural coordination, and operate open-loop without real-time position feedback, leading to accumulated drift. The fundamental challenge is achieving precise, coordinated whole-body teleoperation over extended durations while maintaining accurate global positioning. Here we show that an MoE-based teleoperation system, CLONE, with closed-loop error correction enables unprecedented whole-body teleoperation fidelity, maintaining minimal positional drift over long-range trajectories using only head and hand tracking from an MR headset. Unlike previous methods that either sacrifice coordination for stability or suffer from unbounded drift, CLONE learns diverse motion skills while preventing tracking error accumulation through real-time feedback, enabling complex coordinated movements such as ``picking up objects from the ground.'' These results establish a new milestone for whole-body humanoid teleoperation for long-horizon humanoid-scene interaction tasks.
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill
Apr 05, 2025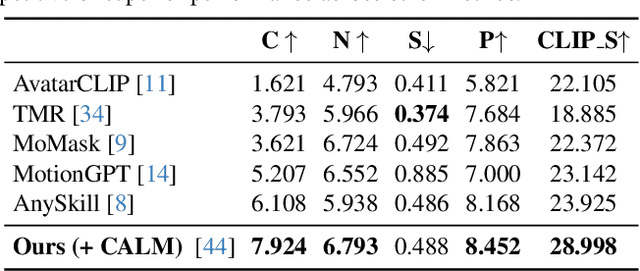
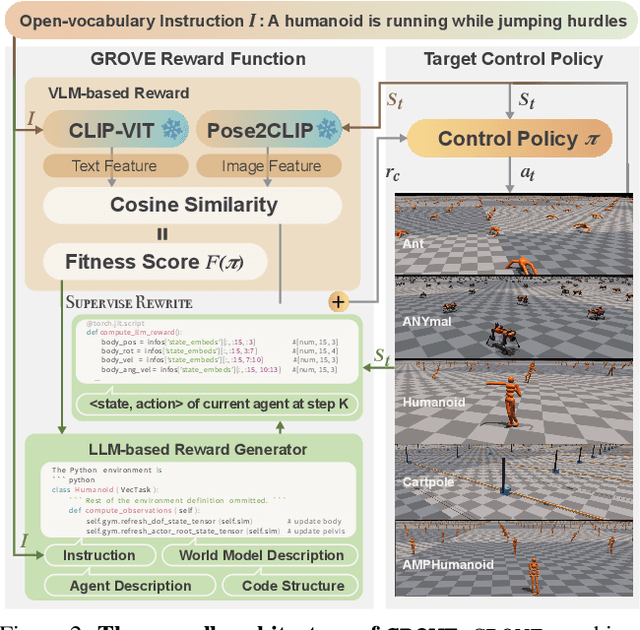
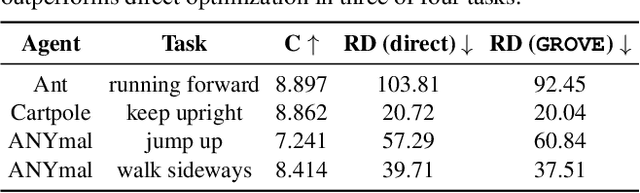

Learning open-vocabulary physical skills for simulated agents presents a significant challenge in artificial intelligence. Current reinforcement learning approaches face critical limitations: manually designed rewards lack scalability across diverse tasks, while demonstration-based methods struggle to generalize beyond their training distribution. We introduce GROVE, a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations. Our key insight is that Large Language Models(LLMs) and Vision Language Models(VLMs) provide complementary guidance -- LLMs generate precise physical constraints capturing task requirements, while VLMs evaluate motion semantics and naturalness. Through an iterative design process, VLM-based feedback continuously refines LLM-generated constraints, creating a self-improving reward system. To bridge the domain gap between simulation and natural images, we develop Pose2CLIP, a lightweight mapper that efficiently projects agent poses directly into semantic feature space without computationally expensive rendering. Extensive experiments across diverse embodiments and learning paradigms demonstrate GROVE's effectiveness, achieving 22.2% higher motion naturalness and 25.7% better task completion scores while training 8.4x faster than previous methods. These results establish a new foundation for scalable physical skill acquisition in simulated environments.
AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents
Mar 19, 2024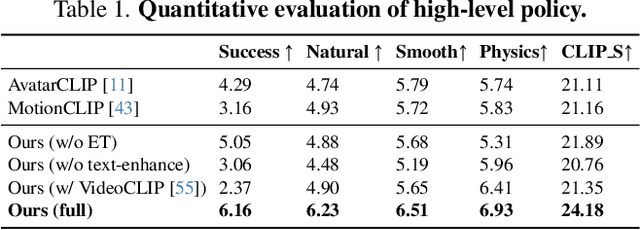
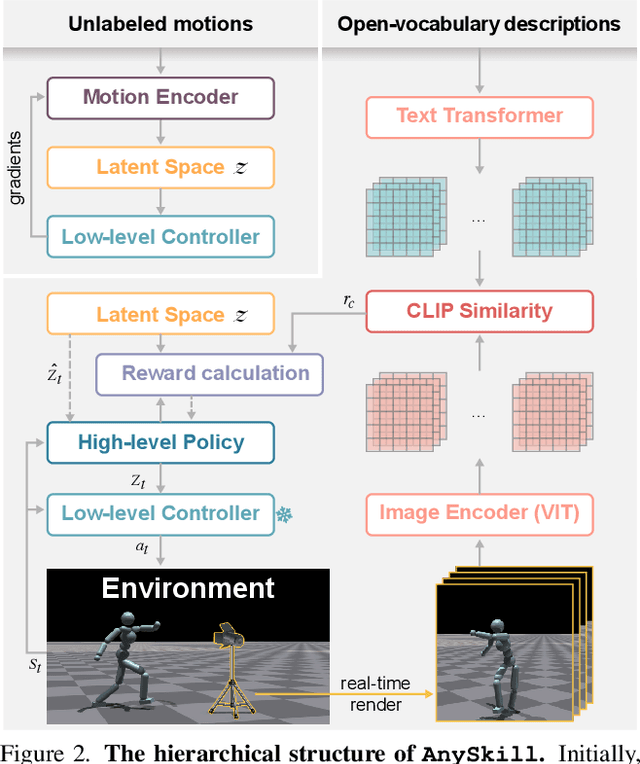


Traditional approaches in physics-based motion generation, centered around imitation learning and reward shaping, often struggle to adapt to new scenarios. To tackle this limitation, we propose AnySkill, a novel hierarchical method that learns physically plausible interactions following open-vocabulary instructions. Our approach begins by developing a set of atomic actions via a low-level controller trained via imitation learning. Upon receiving an open-vocabulary textual instruction, AnySkill employs a high-level policy that selects and integrates these atomic actions to maximize the CLIP similarity between the agent's rendered images and the text. An important feature of our method is the use of image-based rewards for the high-level policy, which allows the agent to learn interactions with objects without manual reward engineering. We demonstrate AnySkill's capability to generate realistic and natural motion sequences in response to unseen instructions of varying lengths, marking it the first method capable of open-vocabulary physical skill learning for interactive humanoid agents.
ProBio: A Protocol-guided Multimodal Dataset for Molecular Biology Lab
Nov 01, 2023The challenge of replicating research results has posed a significant impediment to the field of molecular biology. The advent of modern intelligent systems has led to notable progress in various domains. Consequently, we embarked on an investigation of intelligent monitoring systems as a means of tackling the issue of the reproducibility crisis. Specifically, we first curate a comprehensive multimodal dataset, named ProBio, as an initial step towards this objective. This dataset comprises fine-grained hierarchical annotations intended for the purpose of studying activity understanding in BioLab. Next, we devise two challenging benchmarks, transparent solution tracking and multimodal action recognition, to emphasize the unique characteristics and difficulties associated with activity understanding in BioLab settings. Finally, we provide a thorough experimental evaluation of contemporary video understanding models and highlight their limitations in this specialized domain to identify potential avenues for future research. We hope ProBio with associated benchmarks may garner increased focus on modern AI techniques in the realm of molecular biology.
CHAIRS: Towards Full-Body Articulated Human-Object Interaction
Dec 20, 2022Fine-grained capturing of 3D HOI boosts human activity understanding and facilitates downstream visual tasks, including action recognition, holistic scene reconstruction, and human motion synthesis. Despite its significance, existing works mostly assume that humans interact with rigid objects using only a few body parts, limiting their scope. In this paper, we address the challenging problem of f-AHOI, wherein the whole human bodies interact with articulated objects, whose parts are connected by movable joints. We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 81 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions. We show the value of CHAIRS with object pose estimation. By learning the geometrical relationships in HOI, we devise the very first model that leverage human pose estimation to tackle the estimation of articulated object poses and shapes during whole-body interactions. Given an image and an estimated human pose, our model first reconstructs the pose and shape of the object, then optimizes the reconstruction according to a learned interaction prior. Under both evaluation settings (e.g., with or without the knowledge of objects' geometries/structures), our model significantly outperforms baselines. We hope CHAIRS will promote the community towards finer-grained interaction understanding. We will make the data/code publicly available.