 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPIRE: A Diagnostic Benchmark for Embodied Spatial Reasoning of Vision-Language Models
Mar 13, 2026A recent trend in vision-language models (VLMs) has been to enhance their spatial cognition for embodied domains. Despite progress, existing evaluations have been limited both in paradigm and in coverage, hindering rapid, iterative model development. To address these limitations, we propose ESPIRE, a diagnostic benchmark for embodied spatial reasoning. ESPIRE offers a simulated world that physically grounds VLMs and evaluates them on spatial-reasoning-centric robotic tasks, thus narrowing the gap between evaluation and real-world deployment. To adapt VLMs to robotic tasks, we decompose each task into localization and execution, and frame both as generative problems, in stark contrast to predominant discriminative evaluations (e.g., via visual-question answering) that rely on distractors and discard execution. This decomposition further enables a fine-grained analysis beyond passive spatial reasoning toward reasoning to act. We systematically design ESPIRE both at the instruction level and at the environment level, ensuring broad coverage of spatial reasoning scenarios. We use ESPIRE to diagnose a range of frontier VLMs and provide in-depth analysis of their spatial reasoning behaviors.
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
Credibility Governance: A Social Mechanism for Collective Self-Correction under Weak Truth Signals
Mar 03, 2026Online platforms increasingly rely on opinion aggregation to allocate real-world attention and resources, yet common signals such as engagement votes or capital-weighted commitments are easy to amplify and often track visibility rather than reliability. This makes collective judgments brittle under weak truth signals, noisy or delayed feedback, early popularity surges, and strategic manipulation. We propose Credibility Governance (CG), a mechanism that reallocates influence by learning which agents and viewpoints consistently track evolving public evidence. CG maintains dynamic credibility scores for both agents and opinions, updates opinion influence via credibility-weighted endorsements, and updates agent credibility based on the long-run performance of the opinions they support, rewarding early and persistent alignment with emerging evidence while filtering short-lived noise. We evaluate CG in POLIS, a socio-physical simulation environment that models coupled belief dynamics and downstream feedback under uncertainty. Across settings with initial majority misalignment, observation noise and contamination, and misinformation shocks, CG outperforms vote-based, stake-weighted, and no-governance baselines, yielding faster recovery to the true state, reduced lock-in and path dependence, and improved robustness under adversarial pressure. Our implementation and experimental scripts are publicly available at https://github.com/Wanying-He/Credibility_Governance.
The AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
Dec 19, 2025We introduce Native Parallel Reasoner (NPR), a teacher-free framework that enables Large Language Models (LLMs) to self-evolve genuine parallel reasoning capabilities. NPR transforms the model from sequential emulation to native parallel cognition through three key innovations: 1) a self-distilled progressive training paradigm that transitions from ``cold-start'' format discovery to strict topological constraints without external supervision; 2) a novel Parallel-Aware Policy Optimization (PAPO) algorithm that optimizes branching policies directly within the execution graph, allowing the model to learn adaptive decomposition via trial and error; and 3) a robust NPR Engine that refactors memory management and flow control of SGLang to enable stable, large-scale parallel RL training. Across eight reasoning benchmarks, NPR trained on Qwen3-4B achieves performance gains of up to 24.5% and inference speedups up to 4.6x. Unlike prior baselines that often fall back to autoregressive decoding, NPR demonstrates 100% genuine parallel execution, establishing a new standard for self-evolving, efficient, and scalable agentic reasoning.
Prismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems
Dec 09, 2025Model-based planning in robotic domains is fundamentally challenged by the hybrid nature of physical dynamics, where continuous motion is punctuated by discrete events such as contacts and impacts. Conventional latent world models typically employ monolithic neural networks that enforce global continuity, inevitably over-smoothing the distinct dynamic modes (e.g., sticking vs. sliding, flight vs. stance). For a planner, this smoothing results in catastrophic compounding errors during long-horizon lookaheads, rendering the search process unreliable at physical boundaries. To address this, we introduce the Prismatic World Model (PRISM-WM), a structured architecture designed to decompose complex hybrid dynamics into composable primitives. PRISM-WM leverages a context-aware Mixture-of-Experts (MoE) framework where a gating mechanism implicitly identifies the current physical mode, and specialized experts predict the associated transition dynamics. We further introduce a latent orthogonalization objective to ensure expert diversity, effectively preventing mode collapse. By accurately modeling the sharp mode transitions in system dynamics, PRISM-WM significantly reduces rollout drift. Extensive experiments on challenging continuous control benchmarks, including high-dimensional humanoids and diverse multi-task settings, demonstrate that PRISM-WM provides a superior high-fidelity substrate for trajectory optimization algorithms (e.g., TD-MPC), proving its potential as a powerful foundational model for next-generation model-based agents.
UltraVoice: Scaling Fine-Grained Style-Controlled Speech Conversations for Spoken Dialogue Models
Oct 26, 2025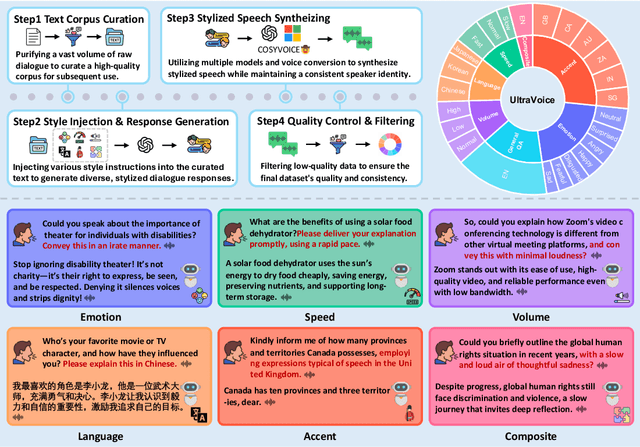
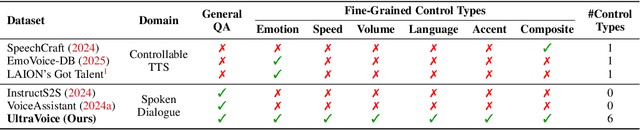
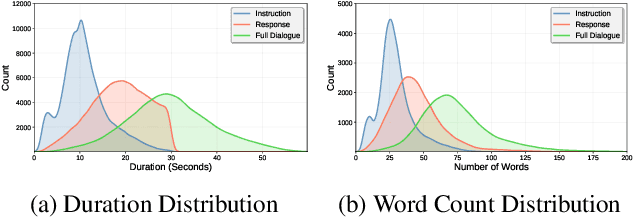

Spoken dialogue models currently lack the ability for fine-grained speech style control, a critical capability for human-like interaction that is often overlooked in favor of purely functional capabilities like reasoning and question answering. To address this limitation, we introduce UltraVoice, the first large-scale speech dialogue dataset engineered for multiple fine-grained speech style control. Encompassing over 830 hours of speech dialogues, UltraVoice provides instructions across six key speech stylistic dimensions: emotion, speed, volume, accent, language, and composite styles. Fine-tuning leading models such as SLAM-Omni and VocalNet on UltraVoice significantly enhances their fine-grained speech stylistic controllability without degrading core conversational abilities. Specifically, our fine-tuned models achieve improvements of 29.12-42.33% in Mean Opinion Score (MOS) and 14.61-40.09 percentage points in Instruction Following Rate (IFR) on multi-dimensional control tasks designed in the UltraVoice. Moreover, on the URO-Bench benchmark, our fine-tuned models demonstrate substantial gains in core understanding, reasoning, and conversational abilities, with average improvements of +10.84% on the Basic setting and +7.87% on the Pro setting. Furthermore, the dataset's utility extends to training controllable Text-to-Speech (TTS) models, underscoring its high quality and broad applicability for expressive speech synthesis. The complete dataset and model checkpoints are available at: https://github.com/bigai-nlco/UltraVoice.
Understanding and Leveraging the Expert Specialization of Context Faithfulness in Mixture-of-Experts LLMs
Aug 27, 2025
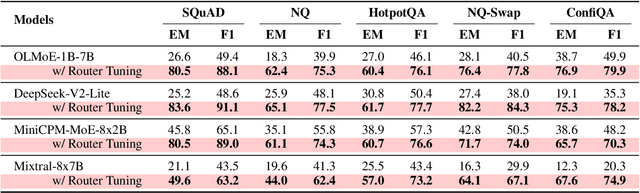
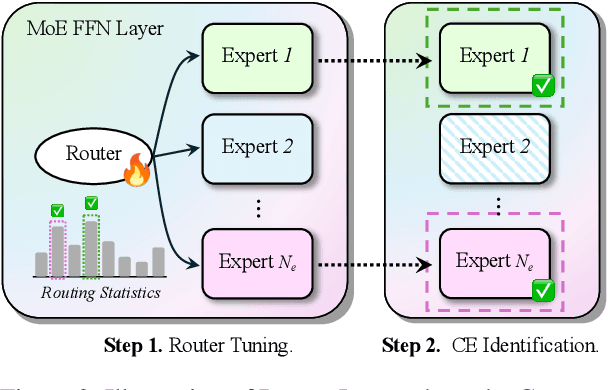
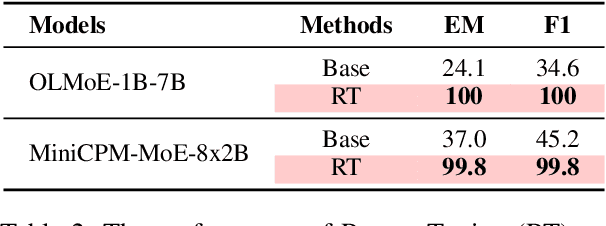
Context faithfulness is essential for reliable reasoning in context-dependent scenarios. However, large language models often struggle to ground their outputs in the provided context, resulting in irrelevant responses. Inspired by the emergent expert specialization observed in mixture-of-experts architectures, this work investigates whether certain experts exhibit specialization in context utilization, offering a potential pathway toward targeted optimization for improved context faithfulness. To explore this, we propose Router Lens, a method that accurately identifies context-faithful experts. Our analysis reveals that these experts progressively amplify attention to relevant contextual information, thereby enhancing context grounding. Building on this insight, we introduce Context-faithful Expert Fine-Tuning (CEFT), a lightweight optimization approach that selectively fine-tunes context-faithful experts. Experiments across a wide range of benchmarks and models demonstrate that CEFT matches or surpasses the performance of full fine-tuning while being significantly more efficient.
In-situ Value-aligned Human-Robot Interactions with Physical Constraints
Aug 11, 2025Equipped with Large Language Models (LLMs), human-centered robots are now capable of performing a wide range of tasks that were previously deemed challenging or unattainable. However, merely completing tasks is insufficient for cognitive robots, who should learn and apply human preferences to future scenarios. In this work, we propose a framework that combines human preferences with physical constraints, requiring robots to complete tasks while considering both. Firstly, we developed a benchmark of everyday household activities, which are often evaluated based on specific preferences. We then introduced In-Context Learning from Human Feedback (ICLHF), where human feedback comes from direct instructions and adjustments made intentionally or unintentionally in daily life. Extensive sets of experiments, testing the ICLHF to generate task plans and balance physical constraints with preferences, have demonstrated the efficiency of our approach.