 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Q-Mix: Selecting the Right Action for LLM Multi-Agent Systems through Reinforcement Learning
Apr 01, 2026Large Language Models (LLMs) have shown remarkable performance in completing various tasks. However, solving complex problems often requires the coordination of multiple agents, raising a fundamental question: how to effectively select and interconnect these agents. In this paper, we propose \textbf{Agent Q-Mix}, a reinforcement learning framework that reformulates topology selection as a cooperative Multi-Agent Reinforcement Learning (MARL) problem. Our method learns decentralized communication decisions using QMIX value factorization, where each agent selects from a set of communication actions that jointly induce a round-wise communication graph. At its core, Agent Q-Mix combines a topology-aware GNN encoder, GRU memory, and per-agent Q-heads under a Centralized Training with Decentralized Execution (CTDE) paradigm. The framework optimizes a reward function that balances task accuracy with token cost. Across seven core benchmarks in coding, reasoning, and mathematics, Agent Q-Mix achieves the highest average accuracy compared to existing methods while demonstrating superior token efficiency and robustness against agent failure. Notably, on the challenging Humanity's Last Exam (HLE) using Gemini-3.1-Flash-Lite as a backbone, Agent Q-Mix achieves 20.8\% accuracy, outperforming Microsoft Agent Framework (19.2\%) and LangGraph (19.2\%), followed by AutoGen and Lobster by OpenClaw. These results underscore the effectiveness of learned, decentralized topology optimization in pushing the boundaries of multi-agent reasoning.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Discrete Markov Bridge
May 26, 2025Discrete diffusion has recently emerged as a promising paradigm in discrete data modeling. However, existing methods typically rely on a fixed rate transition matrix during training, which not only limits the expressiveness of latent representations, a fundamental strength of variational methods, but also constrains the overall design space. To address these limitations, we propose Discrete Markov Bridge, a novel framework specifically designed for discrete representation learning. Our approach is built upon two key components: Matrix Learning and Score Learning. We conduct a rigorous theoretical analysis, establishing formal performance guarantees for Matrix Learning and proving the convergence of the overall framework. Furthermore, we analyze the space complexity of our method, addressing practical constraints identified in prior studies. Extensive empirical evaluations validate the effectiveness of the proposed Discrete Markov Bridge, which achieves an Evidence Lower Bound (ELBO) of 1.38 on the Text8 dataset, outperforming established baselines. Moreover, the proposed model demonstrates competitive performance on the CIFAR-10 dataset, achieving results comparable to those obtained by image-specific generation approaches.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space
May 19, 2025Reasoning ability, a core component of human intelligence, continues to pose a significant challenge for Large Language Models (LLMs) in the pursuit of AGI. Although model performance has improved under the training scaling law, significant challenges remain, particularly with respect to training algorithms, such as catastrophic forgetting, and the limited availability of novel training data. As an alternative, test-time scaling enhances reasoning performance by increasing test-time computation without parameter updating. Unlike prior methods in this paradigm focused on token space, we propose leveraging latent space for more effective reasoning and better adherence to the test-time scaling law. We introduce LatentSeek, a novel framework that enhances LLM reasoning through Test-Time Instance-level Adaptation (TTIA) within the model's latent space. Specifically, LatentSeek leverages policy gradient to iteratively update latent representations, guided by self-generated reward signals. LatentSeek is evaluated on a range of reasoning benchmarks, including GSM8K, MATH-500, and AIME2024, across multiple LLM architectures. Results show that LatentSeek consistently outperforms strong baselines, such as Chain-of-Thought prompting and fine-tuning-based methods. Furthermore, our analysis demonstrates that LatentSeek is highly efficient, typically converging within a few iterations for problems of average complexity, while also benefiting from additional iterations, thereby highlighting the potential of test-time scaling in the latent space. These findings position LatentSeek as a lightweight, scalable, and effective solution for enhancing the reasoning capabilities of LLMs.
Causal Graph Guided Steering of LLM Values via Prompts and Sparse Autoencoders
Dec 31, 2024As large language models (LLMs) become increasingly integrated into critical applications, aligning their behavior with human values presents significant challenges. Current methods, such as Reinforcement Learning from Human Feedback (RLHF), often focus on a limited set of values and can be resource-intensive. Furthermore, the correlation between values has been largely overlooked and remains underutilized. Our framework addresses this limitation by mining a causal graph that elucidates the implicit relationships among various values within the LLMs. Leveraging the causal graph, we implement two lightweight mechanisms for value steering: prompt template steering and Sparse Autoencoder feature steering, and analyze the effects of altering one value dimension on others. Extensive experiments conducted on Gemma-2B-IT and Llama3-8B-IT demonstrate the effectiveness and controllability of our steering methods.
How to Synthesize Text Data without Model Collapse?
Dec 19, 2024

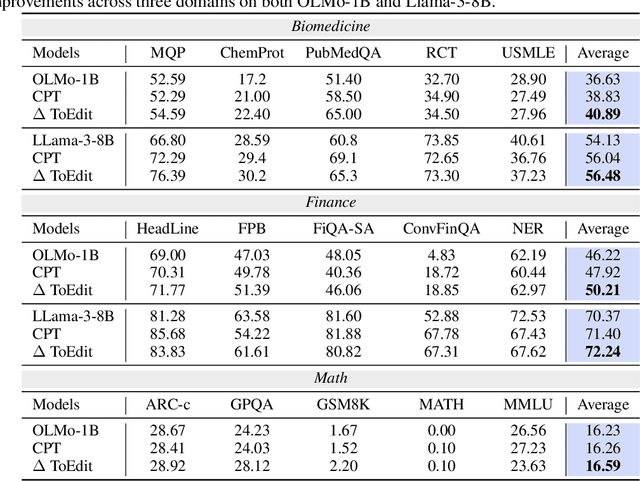
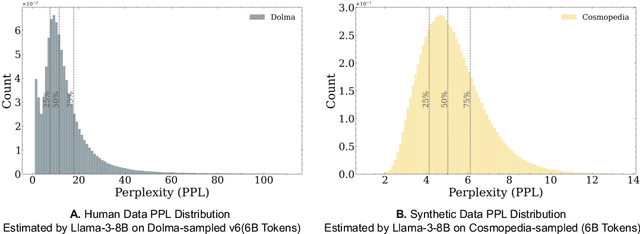
Model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem. Future GPT-$\{n\}$ models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse? We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance. We further conduct statistical analysis on synthetic data to uncover distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data. As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound. We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.
DiPlomat: A Dialogue Dataset for Situated Pragmatic Reasoning
Jun 19, 2023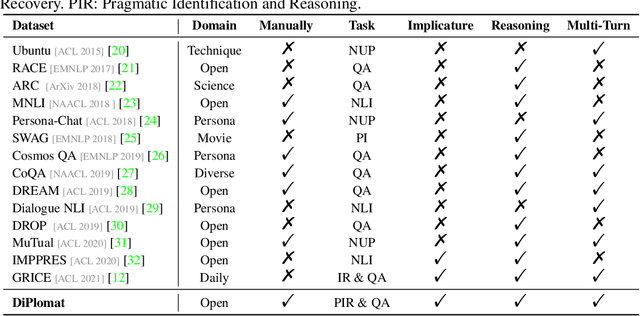



Pragmatic reasoning plays a pivotal role in deciphering implicit meanings that frequently arise in real-life conversations and is essential for the development of communicative social agents. In this paper, we introduce a novel challenge, DiPlomat, aiming at benchmarking machines' capabilities on pragmatic reasoning and situated conversational understanding. Compared with previous works that treat different figurative expressions (e.g. metaphor, sarcasm) as individual tasks, DiPlomat provides a cohesive framework towards general pragmatic understanding. Our dataset is created through the utilization of Amazon Mechanical Turk ( AMT ), resulting in a total of 4, 177 multi-turn dialogues. In conjunction with the dataset, we propose two tasks, Pragmatic Identification and Reasoning (PIR) and Conversational Question Answering (CQA). Experimental results with state-of-the-art (SOTA) neural architectures reveal several significant findings: 1) large language models ( LLMs) exhibit poor performance in tackling this subjective domain; 2) comprehensive comprehension of context emerges as a critical factor for establishing benign human-machine interactions; 3) current models defect in the application of pragmatic reasoning. As a result, we call on more attention to improve the ability of context understanding, reasoning, and implied meaning modeling.