 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackVLA++: Unleashing Reasoning and Memory Capabilities in VLA Models for Embodied Visual Tracking
Oct 08, 2025Embodied Visual Tracking (EVT) is a fundamental ability that underpins practical applications, such as companion robots, guidance robots and service assistants, where continuously following moving targets is essential. Recent advances have enabled language-guided tracking in complex and unstructured scenes. However, existing approaches lack explicit spatial reasoning and effective temporal memory, causing failures under severe occlusions or in the presence of similar-looking distractors. To address these challenges, we present TrackVLA++, a novel Vision-Language-Action (VLA) model that enhances embodied visual tracking with two key modules, a spatial reasoning mechanism and a Target Identification Memory (TIM). The reasoning module introduces a Chain-of-Thought paradigm, termed Polar-CoT, which infers the target's relative position and encodes it as a compact polar-coordinate token for action prediction. Guided by these spatial priors, the TIM employs a gated update strategy to preserve long-horizon target memory, ensuring spatiotemporal consistency and mitigating target loss during extended occlusions. Extensive experiments show that TrackVLA++ achieves state-of-the-art performance on public benchmarks across both egocentric and multi-camera settings. On the challenging EVT-Bench DT split, TrackVLA++ surpasses the previous leading approach by 5.1 and 12, respectively. Furthermore, TrackVLA++ exhibits strong zero-shot generalization, enabling robust real-world tracking in dynamic and occluded scenarios.
TrackVLA: Embodied Visual Tracking in the Wild
May 29, 2025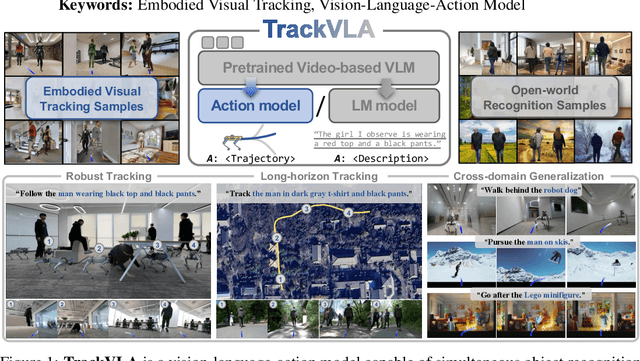

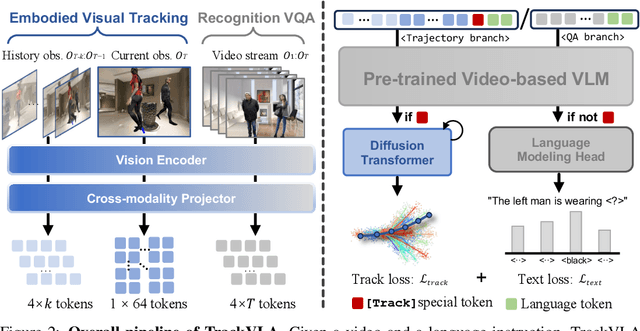
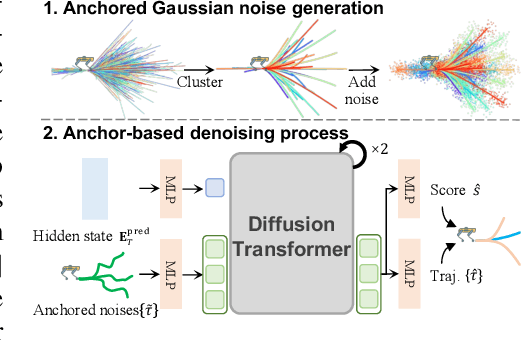
Embodied visual tracking is a fundamental skill in Embodied AI, enabling an agent to follow a specific target in dynamic environments using only egocentric vision. This task is inherently challenging as it requires both accurate target recognition and effective trajectory planning under conditions of severe occlusion and high scene dynamics. Existing approaches typically address this challenge through a modular separation of recognition and planning. In this work, we propose TrackVLA, a Vision-Language-Action (VLA) model that learns the synergy between object recognition and trajectory planning. Leveraging a shared LLM backbone, we employ a language modeling head for recognition and an anchor-based diffusion model for trajectory planning. To train TrackVLA, we construct an Embodied Visual Tracking Benchmark (EVT-Bench) and collect diverse difficulty levels of recognition samples, resulting in a dataset of 1.7 million samples. Through extensive experiments in both synthetic and real-world environments, TrackVLA demonstrates SOTA performance and strong generalizability. It significantly outperforms existing methods on public benchmarks in a zero-shot manner while remaining robust to high dynamics and occlusion in real-world scenarios at 10 FPS inference speed. Our project page is: https://pku-epic.github.io/TrackVLA-web.
VLM Can Be a Good Assistant: Enhancing Embodied Visual Tracking with Self-Improving Vision-Language Models
May 28, 2025We introduce a novel self-improving framework that enhances Embodied Visual Tracking (EVT) with Vision-Language Models (VLMs) to address the limitations of current active visual tracking systems in recovering from tracking failure. Our approach combines the off-the-shelf active tracking methods with VLMs' reasoning capabilities, deploying a fast visual policy for normal tracking and activating VLM reasoning only upon failure detection. The framework features a memory-augmented self-reflection mechanism that enables the VLM to progressively improve by learning from past experiences, effectively addressing VLMs' limitations in 3D spatial reasoning. Experimental results demonstrate significant performance improvements, with our framework boosting success rates by $72\%$ with state-of-the-art RL-based approaches and $220\%$ with PID-based methods in challenging environments. This work represents the first integration of VLM-based reasoning to assist EVT agents in proactive failure recovery, offering substantial advances for real-world robotic applications that require continuous target monitoring in dynamic, unstructured environments. Project website: https://sites.google.com/view/evt-recovery-assistant.
From Strangers to Assistants: Fast Desire Alignment for Embodied Agent-User Adaptation
May 28, 2025While embodied agents have made significant progress in performing complex physical tasks, real-world applications demand more than pure task execution. The agents must collaborate with unfamiliar agents and human users, whose goals are often vague and implicit. In such settings, interpreting ambiguous instructions and uncovering underlying desires is essential for effective assistance. Therefore, fast and accurate desire alignment becomes a critical capability for embodied agents. In this work, we first develop a home assistance simulation environment HA-Desire that integrates an LLM-driven human user agent exhibiting realistic value-driven goal selection and communication. The ego agent must interact with this proxy user to infer and adapt to the user's latent desires. To achieve this, we present a novel framework FAMER for fast desire alignment, which introduces a desire-based mental reasoning mechanism to identify user intent and filter desire-irrelevant actions. We further design a reflection-based communication module that reduces redundant inquiries, and incorporate goal-relevant information extraction with memory persistence to improve information reuse and reduce unnecessary exploration. Extensive experiments demonstrate that our framework significantly enhances both task execution and communication efficiency, enabling embodied agents to quickly adapt to user-specific desires in complex embodied environments.
Hierarchical Instruction-aware Embodied Visual Tracking
May 27, 2025User-Centric Embodied Visual Tracking (UC-EVT) presents a novel challenge for reinforcement learning-based models due to the substantial gap between high-level user instructions and low-level agent actions. While recent advancements in language models (e.g., LLMs, VLMs, VLAs) have improved instruction comprehension, these models face critical limitations in either inference speed (LLMs, VLMs) or generalizability (VLAs) for UC-EVT tasks. To address these challenges, we propose \textbf{Hierarchical Instruction-aware Embodied Visual Tracking (HIEVT)} agent, which bridges instruction comprehension and action generation using \textit{spatial goals} as intermediaries. HIEVT first introduces \textit{LLM-based Semantic-Spatial Goal Aligner} to translate diverse human instructions into spatial goals that directly annotate the desired spatial position. Then the \textit{RL-based Adaptive Goal-Aligned Policy}, a general offline policy, enables the tracker to position the target as specified by the spatial goal. To benchmark UC-EVT tasks, we collect over ten million trajectories for training and evaluate across one seen environment and nine unseen challenging environments. Extensive experiments and real-world deployments demonstrate the robustness and generalizability of HIEVT across diverse environments, varying target dynamics, and complex instruction combinations. The complete project is available at https://sites.google.com/view/hievt.
CoMet: Metaphor-Driven Covert Communication for Multi-Agent Language Games
May 23, 2025Metaphors are a crucial way for humans to express complex or subtle ideas by comparing one concept to another, often from a different domain. However, many large language models (LLMs) struggle to interpret and apply metaphors in multi-agent language games, hindering their ability to engage in covert communication and semantic evasion, which are crucial for strategic communication. To address this challenge, we introduce CoMet, a framework that enables LLM-based agents to engage in metaphor processing. CoMet combines a hypothesis-based metaphor reasoner with a metaphor generator that improves through self-reflection and knowledge integration. This enhances the agents' ability to interpret and apply metaphors, improving the strategic and nuanced quality of their interactions. We evaluate CoMet on two multi-agent language games - Undercover and Adversarial Taboo - which emphasize Covert Communication and Semantic Evasion. Experimental results demonstrate that CoMet significantly enhances the agents' ability to communicate strategically using metaphors.
Probe by Gaming: A Game-based Benchmark for Assessing Conceptual Knowledge in LLMs
May 23, 2025Concepts represent generalized abstractions that enable humans to categorize and reason efficiently, yet it is unclear to what extent Large Language Models (LLMs) comprehend these semantic relationships. Existing benchmarks typically focus on factual recall and isolated tasks, failing to evaluate the ability of LLMs to understand conceptual boundaries. To address this gap, we introduce CK-Arena, a multi-agent interaction game built upon the Undercover game, designed to evaluate the capacity of LLMs to reason with concepts in interactive settings. CK-Arena challenges models to describe, differentiate, and infer conceptual boundaries based on partial information, encouraging models to explore commonalities and distinctions between closely related concepts. By simulating real-world interaction, CK-Arena provides a scalable and realistic benchmark for assessing conceptual reasoning in dynamic environments. Experimental results show that LLMs' understanding of conceptual knowledge varies significantly across different categories and is not strictly aligned with parameter size or general model capabilities. The data and code are available at the project homepage: https://ck-arena.site.
Clinical Inspired MRI Lesion Segmentation
Feb 22, 2025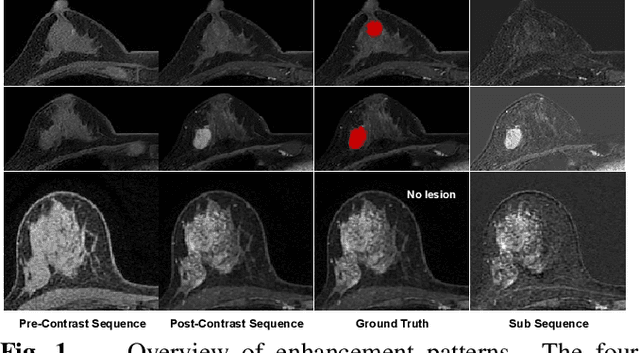
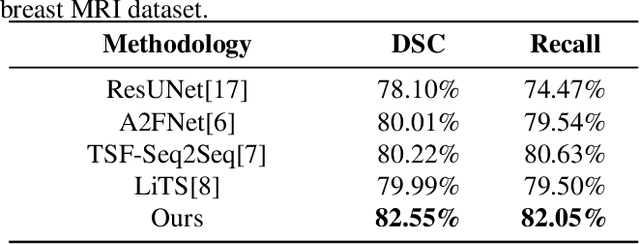
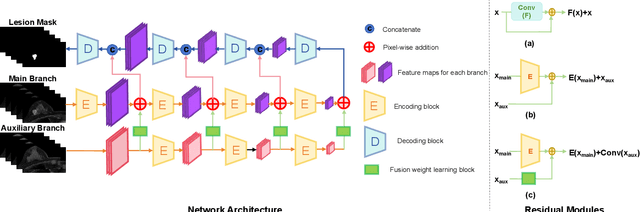
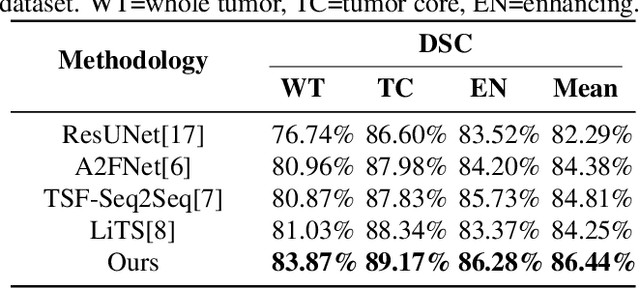
Magnetic resonance imaging (MRI) is a potent diagnostic tool for detecting pathological tissues in various diseases. Different MRI sequences have different contrast mechanisms and sensitivities for different types of lesions, which pose challenges to accurate and consistent lesion segmentation. In clinical practice, radiologists commonly use the sub-sequence feature, i.e. the difference between post contrast-enhanced T1-weighted (post) and pre-contrast-enhanced (pre) sequences, to locate lesions. Inspired by this, we propose a residual fusion method to learn subsequence representation for MRI lesion segmentation. Specifically, we iteratively and adaptively fuse features from pre- and post-contrast sequences at multiple resolutions, using dynamic weights to achieve optimal fusion and address diverse lesion enhancement patterns. Our method achieves state-of-the-art performances on BraTS2023 dataset for brain tumor segmentation and our in-house breast MRI dataset for breast lesion segmentation. Our method is clinically inspired and has the potential to facilitate lesion segmentation in various applications.
Causal Graph Guided Steering of LLM Values via Prompts and Sparse Autoencoders
Dec 31, 2024As large language models (LLMs) become increasingly integrated into critical applications, aligning their behavior with human values presents significant challenges. Current methods, such as Reinforcement Learning from Human Feedback (RLHF), often focus on a limited set of values and can be resource-intensive. Furthermore, the correlation between values has been largely overlooked and remains underutilized. Our framework addresses this limitation by mining a causal graph that elucidates the implicit relationships among various values within the LLMs. Leveraging the causal graph, we implement two lightweight mechanisms for value steering: prompt template steering and Sparse Autoencoder feature steering, and analyze the effects of altering one value dimension on others. Extensive experiments conducted on Gemma-2B-IT and Llama3-8B-IT demonstrate the effectiveness and controllability of our steering methods.
UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI
Dec 30, 2024



We introduce UnrealZoo, a rich collection of photo-realistic 3D virtual worlds built on Unreal Engine, designed to reflect the complexity and variability of the open worlds. Additionally, we offer a variety of playable entities for embodied AI agents. Based on UnrealCV, we provide a suite of easy-to-use Python APIs and tools for various potential applications, such as data collection, environment augmentation, distributed training, and benchmarking. We optimize the rendering and communication efficiency of UnrealCV to support advanced applications, such as multi-agent interaction. Our experiments benchmark agents in various complex scenes, focusing on visual navigation and tracking, which are fundamental capabilities for embodied visual intelligence. The results yield valuable insights into the advantages of diverse training environments for reinforcement learning (RL) agents and the challenges faced by current embodied vision agents, including those based on RL and large vision-language models (VLMs), in open worlds. These challenges involve latency in closed-loop control in dynamic scenes and reasoning about 3D spatial structures in unstructured terrain.