 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
Feb 06, 2026Recent progress in robotic world models has leveraged video diffusion transformers to predict future observations conditioned on historical states and actions. While these models can simulate realistic visual outcomes, they often exhibit poor action-following precision, hindering their utility for downstream robotic learning. In this work, we introduce World-VLA-Loop, a closed-loop framework for the joint refinement of world models and Vision-Language-Action (VLA) policies. We propose a state-aware video world model that functions as a high-fidelity interactive simulator by jointly predicting future observations and reward signals. To enhance reliability, we introduce the SANS dataset, which incorporates near-success trajectories to improve action-outcome alignment within the world model. This framework enables a closed-loop for reinforcement learning (RL) post-training of VLA policies entirely within a virtual environment. Crucially, our approach facilitates a co-evolving cycle: failure rollouts generated by the VLA policy are iteratively fed back to refine the world model precision, which in turn enhances subsequent RL optimization. Evaluations across simulation and real-world tasks demonstrate that our framework significantly boosts VLA performance with minimal physical interaction, establishing a mutually beneficial relationship between world modeling and policy learning for general-purpose robotics. Project page: https://showlab.github.io/World-VLA-Loop/.
H2R-Grounder: A Paired-Data-Free Paradigm for Translating Human Interaction Videos into Physically Grounded Robot Videos
Dec 10, 2025



Robots that learn manipulation skills from everyday human videos could acquire broad capabilities without tedious robot data collection. We propose a video-to-video translation framework that converts ordinary human-object interaction videos into motion-consistent robot manipulation videos with realistic, physically grounded interactions. Our approach does not require any paired human-robot videos for training only a set of unpaired robot videos, making the system easy to scale. We introduce a transferable representation that bridges the embodiment gap: by inpainting the robot arm in training videos to obtain a clean background and overlaying a simple visual cue (a marker and arrow indicating the gripper's position and orientation), we can condition a generative model to insert the robot arm back into the scene. At test time, we apply the same process to human videos (inpainting the person and overlaying human pose cues) and generate high-quality robot videos that mimic the human's actions. We fine-tune a SOTA video diffusion model (Wan 2.2) in an in-context learning manner to ensure temporal coherence and leveraging of its rich prior knowledge. Empirical results demonstrate that our approach achieves significantly more realistic and grounded robot motions compared to baselines, pointing to a promising direction for scaling up robot learning from unlabeled human videos. Project page: https://showlab.github.io/H2R-Grounder/
OptMark: Robust Multi-bit Diffusion Watermarking via Inference Time Optimization
Aug 29, 2025



Watermarking diffusion-generated images is crucial for copyright protection and user tracking. However, current diffusion watermarking methods face significant limitations: zero-bit watermarking systems lack the capacity for large-scale user tracking, while multi-bit methods are highly sensitive to certain image transformations or generative attacks, resulting in a lack of comprehensive robustness. In this paper, we propose OptMark, an optimization-based approach that embeds a robust multi-bit watermark into the intermediate latents of the diffusion denoising process. OptMark strategically inserts a structural watermark early to resist generative attacks and a detail watermark late to withstand image transformations, with tailored regularization terms to preserve image quality and ensure imperceptibility. To address the challenge of memory consumption growing linearly with the number of denoising steps during optimization, OptMark incorporates adjoint gradient methods, reducing memory usage from O(N) to O(1). Experimental results demonstrate that OptMark achieves invisible multi-bit watermarking while ensuring robust resilience against valuemetric transformations, geometric transformations, editing, and regeneration attacks.
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents
Jun 05, 2025

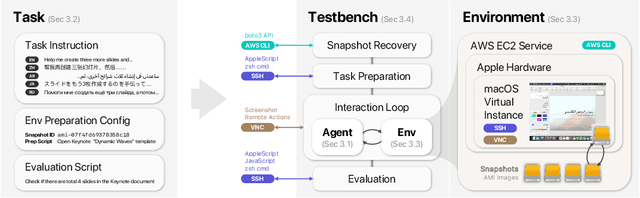

Graphical User Interface (GUI) agents show promising capabilities for automating computer-use tasks and facilitating accessibility, but existing interactive benchmarks are mostly English-only, covering web-use or Windows, Linux, and Android environments, but not macOS. macOS is a major OS with distinctive GUI patterns and exclusive applications. To bridge the gaps, we present macOSWorld, the first comprehensive benchmark for evaluating GUI agents on macOS. macOSWorld features 202 multilingual interactive tasks across 30 applications (28 macOS-exclusive), with task instructions and OS interfaces offered in 5 languages (English, Chinese, Arabic, Japanese, and Russian). As GUI agents are shown to be vulnerable to deception attacks, macOSWorld also includes a dedicated safety benchmarking subset. Our evaluation on six GUI agents reveals a dramatic gap: proprietary computer-use agents lead at above 30% success rate, while open-source lightweight research models lag at below 2%, highlighting the need for macOS domain adaptation. Multilingual benchmarks also expose common weaknesses, especially in Arabic, with a 27.5% average degradation compared to English. Results from safety benchmarking also highlight that deception attacks are more general and demand immediate attention. macOSWorld is available at https://github.com/showlab/macosworld.
Cyc3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Apr 21, 2025


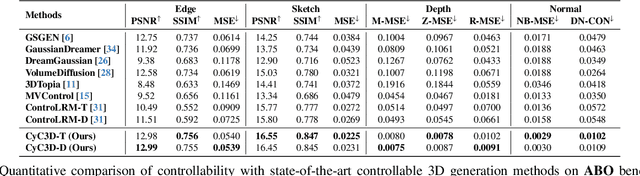
Despite the remarkable progress of 3D generation, achieving controllability, i.e., ensuring consistency between generated 3D content and input conditions like edge and depth, remains a significant challenge. Existing methods often struggle to maintain accurate alignment, leading to noticeable discrepancies. To address this issue, we propose \name{}, a new framework that enhances controllable 3D generation by explicitly encouraging cyclic consistency between the second-order 3D content, generated based on extracted signals from the first-order generation, and its original input controls. Specifically, we employ an efficient feed-forward backbone that can generate a 3D object from an input condition and a text prompt. Given an initial viewpoint and a control signal, a novel view is rendered from the generated 3D content, from which the extracted condition is used to regenerate the 3D content. This re-generated output is then rendered back to the initial viewpoint, followed by another round of control signal extraction, forming a cyclic process with two consistency constraints. \emph{View consistency} ensures coherence between the two generated 3D objects, measured by semantic similarity to accommodate generative diversity. \emph{Condition consistency} aligns the final extracted signal with the original input control, preserving structural or geometric details throughout the process. Extensive experiments on popular benchmarks demonstrate that \name{} significantly improves controllability, especially for fine-grained details, outperforming existing methods across various conditions (e.g., +14.17\% PSNR for edge, +6.26\% PSNR for sketch).
Impossible Videos
Mar 18, 2025Synthetic videos nowadays is widely used to complement data scarcity and diversity of real-world videos. Current synthetic datasets primarily replicate real-world scenarios, leaving impossible, counterfactual and anti-reality video concepts underexplored. This work aims to answer two questions: 1) Can today's video generation models effectively follow prompts to create impossible video content? 2) Are today's video understanding models good enough for understanding impossible videos? To this end, we introduce IPV-Bench, a novel benchmark designed to evaluate and foster progress in video understanding and generation. IPV-Bench is underpinned by a comprehensive taxonomy, encompassing 4 domains, 14 categories. It features diverse scenes that defy physical, biological, geographical, or social laws. Based on the taxonomy, a prompt suite is constructed to evaluate video generation models, challenging their prompt following and creativity capabilities. In addition, a video benchmark is curated to assess Video-LLMs on their ability of understanding impossible videos, which particularly requires reasoning on temporal dynamics and world knowledge. Comprehensive evaluations reveal limitations and insights for future directions of video models, paving the way for next-generation video models.
In-Context Defense in Computer Agents: An Empirical Study
Mar 12, 2025Computer agents powered by vision-language models (VLMs) have significantly advanced human-computer interaction, enabling users to perform complex tasks through natural language instructions. However, these agents are vulnerable to context deception attacks, an emerging threat where adversaries embed misleading content into the agent's operational environment, such as a pop-up window containing deceptive instructions. Existing defenses, such as instructing agents to ignore deceptive elements, have proven largely ineffective. As the first systematic study on protecting computer agents, we introduce textbf{in-context defense}, leveraging in-context learning and chain-of-thought (CoT) reasoning to counter such attacks. Our approach involves augmenting the agent's context with a small set of carefully curated exemplars containing both malicious environments and corresponding defensive responses. These exemplars guide the agent to first perform explicit defensive reasoning before action planning, reducing susceptibility to deceptive attacks. Experiments demonstrate the effectiveness of our method, reducing attack success rates by 91.2% on pop-up window attacks, 74.6% on average on environment injection attacks, while achieving 100% successful defenses against distracting advertisements. Our findings highlight that (1) defensive reasoning must precede action planning for optimal performance, and (2) a minimal number of exemplars (fewer than three) is sufficient to induce an agent's defensive behavior.
LongViTU: Instruction Tuning for Long-Form Video Understanding
Jan 09, 2025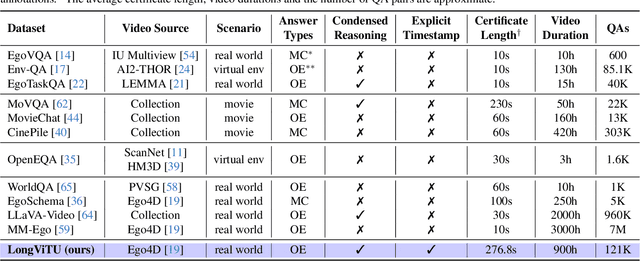
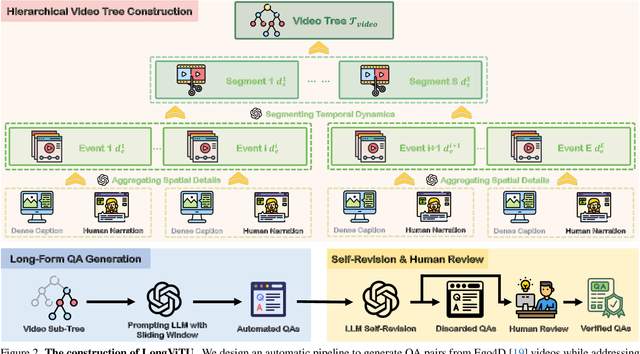
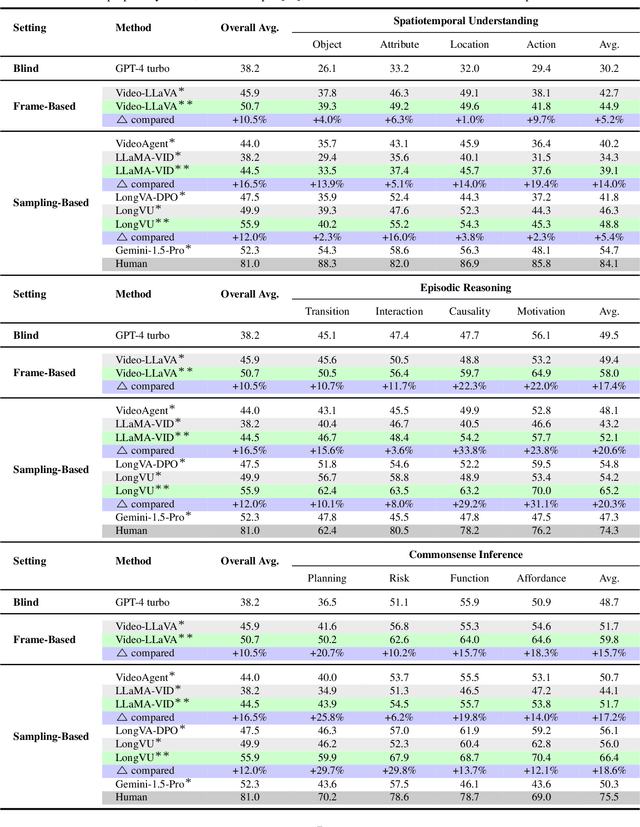
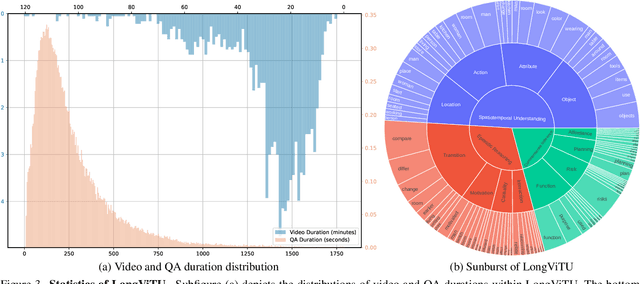
This paper introduce LongViTU, a large-scale (~121k QA pairs, ~900h videos), automatically generated dataset for long-form video understanding. We developed a systematic approach that organizes videos into a hierarchical tree structure and incorporates self-revision mechanisms to ensure high-quality QA pairs. Each QA pair in LongViTU features: 1) long-term context (average certificate length of 4.6 minutes); 2) rich knowledge and condensed reasoning (commonsense, causality, planning, etc.); and 3) explicit timestamp labels for relevant events. LongViTU also serves as a benchmark for instruction following in long-form and streaming video understanding. We evaluate the open-source state-of-the-art long video understanding model, LongVU, and the commercial model, Gemini-1.5-Pro, on our benchmark. They achieve GPT-4 scores of 49.9 and 52.3, respectively, underscoring the substantial challenge posed by our benchmark. Further supervised fine-tuning (SFT) on LongVU led to performance improvements of 12.0% on our benchmark, 2.2% on the in-distribution (ID) benchmark EgoSchema, 1.0%, 2.2% and 1.2% on the out-of-distribution (OOD) benchmarks VideoMME (Long), WorldQA and OpenEQA, respectively. These outcomes demonstrate LongViTU's high data quality and robust OOD generalizability.
UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI
Dec 30, 2024



We introduce UnrealZoo, a rich collection of photo-realistic 3D virtual worlds built on Unreal Engine, designed to reflect the complexity and variability of the open worlds. Additionally, we offer a variety of playable entities for embodied AI agents. Based on UnrealCV, we provide a suite of easy-to-use Python APIs and tools for various potential applications, such as data collection, environment augmentation, distributed training, and benchmarking. We optimize the rendering and communication efficiency of UnrealCV to support advanced applications, such as multi-agent interaction. Our experiments benchmark agents in various complex scenes, focusing on visual navigation and tracking, which are fundamental capabilities for embodied visual intelligence. The results yield valuable insights into the advantages of diverse training environments for reinforcement learning (RL) agents and the challenges faced by current embodied vision agents, including those based on RL and large vision-language models (VLMs), in open worlds. These challenges involve latency in closed-loop control in dynamic scenes and reasoning about 3D spatial structures in unstructured terrain.
IDProtector: An Adversarial Noise Encoder to Protect Against ID-Preserving Image Generation
Dec 16, 2024



Recently, zero-shot methods like InstantID have revolutionized identity-preserving generation. Unlike multi-image finetuning approaches such as DreamBooth, these zero-shot methods leverage powerful facial encoders to extract identity information from a single portrait photo, enabling efficient identity-preserving generation through a single inference pass. However, this convenience introduces new threats to the facial identity protection. This paper aims to safeguard portrait photos from unauthorized encoder-based customization. We introduce IDProtector, an adversarial noise encoder that applies imperceptible adversarial noise to portrait photos in a single forward pass. Our approach offers universal protection for portraits against multiple state-of-the-art encoder-based methods, including InstantID, IP-Adapter, and PhotoMaker, while ensuring robustness to common image transformations such as JPEG compression, resizing, and affine transformations. Experiments across diverse portrait datasets and generative models reveal that IDProtector generalizes effectively to unseen data and even closed-source proprietary models.