 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
Feb 06, 2026Recent progress in robotic world models has leveraged video diffusion transformers to predict future observations conditioned on historical states and actions. While these models can simulate realistic visual outcomes, they often exhibit poor action-following precision, hindering their utility for downstream robotic learning. In this work, we introduce World-VLA-Loop, a closed-loop framework for the joint refinement of world models and Vision-Language-Action (VLA) policies. We propose a state-aware video world model that functions as a high-fidelity interactive simulator by jointly predicting future observations and reward signals. To enhance reliability, we introduce the SANS dataset, which incorporates near-success trajectories to improve action-outcome alignment within the world model. This framework enables a closed-loop for reinforcement learning (RL) post-training of VLA policies entirely within a virtual environment. Crucially, our approach facilitates a co-evolving cycle: failure rollouts generated by the VLA policy are iteratively fed back to refine the world model precision, which in turn enhances subsequent RL optimization. Evaluations across simulation and real-world tasks demonstrate that our framework significantly boosts VLA performance with minimal physical interaction, establishing a mutually beneficial relationship between world modeling and policy learning for general-purpose robotics. Project page: https://showlab.github.io/World-VLA-Loop/.
RSOD: Reliability-Guided Sonar Image Object Detection with Extremely Limited Labels
Jan 19, 2026Object detection in sonar images is a key technology in underwater detection systems. Compared to natural images, sonar images contain fewer texture details and are more susceptible to noise, making it difficult for non-experts to distinguish subtle differences between classes. This leads to their inability to provide precise annotation data for sonar images. Therefore, designing effective object detection methods for sonar images with extremely limited labels is particularly important. To address this, we propose a teacher-student framework called RSOD, which aims to fully learn the characteristics of sonar images and develop a pseudo-label strategy suitable for these images to mitigate the impact of limited labels. First, RSOD calculates a reliability score by assessing the consistency of the teacher's predictions across different views. To leverage this score, we introduce an object mixed pseudo-label method to tackle the shortage of labeled data in sonar images. Finally, we optimize the performance of the student by implementing a reliability-guided adaptive constraint. By taking full advantage of unlabeled data, the student can perform well even in situations with extremely limited labels. Notably, on the UATD dataset, our method, using only 5% of labeled data, achieves results that can compete against those of our baseline algorithm trained on 100% labeled data. We also collected a new dataset to provide more valuable data for research in the field of sonar.
H2R-Grounder: A Paired-Data-Free Paradigm for Translating Human Interaction Videos into Physically Grounded Robot Videos
Dec 10, 2025



Robots that learn manipulation skills from everyday human videos could acquire broad capabilities without tedious robot data collection. We propose a video-to-video translation framework that converts ordinary human-object interaction videos into motion-consistent robot manipulation videos with realistic, physically grounded interactions. Our approach does not require any paired human-robot videos for training only a set of unpaired robot videos, making the system easy to scale. We introduce a transferable representation that bridges the embodiment gap: by inpainting the robot arm in training videos to obtain a clean background and overlaying a simple visual cue (a marker and arrow indicating the gripper's position and orientation), we can condition a generative model to insert the robot arm back into the scene. At test time, we apply the same process to human videos (inpainting the person and overlaying human pose cues) and generate high-quality robot videos that mimic the human's actions. We fine-tune a SOTA video diffusion model (Wan 2.2) in an in-context learning manner to ensure temporal coherence and leveraging of its rich prior knowledge. Empirical results demonstrate that our approach achieves significantly more realistic and grounded robot motions compared to baselines, pointing to a promising direction for scaling up robot learning from unlabeled human videos. Project page: https://showlab.github.io/H2R-Grounder/
DiffSim: Taming Diffusion Models for Evaluating Visual Similarity
Dec 19, 2024



Diffusion models have fundamentally transformed the field of generative models, making the assessment of similarity between customized model outputs and reference inputs critically important. However, traditional perceptual similarity metrics operate primarily at the pixel and patch levels, comparing low-level colors and textures but failing to capture mid-level similarities and differences in image layout, object pose, and semantic content. Contrastive learning-based CLIP and self-supervised learning-based DINO are often used to measure semantic similarity, but they highly compress image features, inadequately assessing appearance details. This paper is the first to discover that pretrained diffusion models can be utilized for measuring visual similarity and introduces the DiffSim method, addressing the limitations of traditional metrics in capturing perceptual consistency in custom generation tasks. By aligning features in the attention layers of the denoising U-Net, DiffSim evaluates both appearance and style similarity, showing superior alignment with human visual preferences. Additionally, we introduce the Sref and IP benchmarks to evaluate visual similarity at the level of style and instance, respectively. Comprehensive evaluations across multiple benchmarks demonstrate that DiffSim achieves state-of-the-art performance, providing a robust tool for measuring visual coherence in generative models.
Anti-Reference: Universal and Immediate Defense Against Reference-Based Generation
Dec 08, 2024Diffusion models have revolutionized generative modeling with their exceptional ability to produce high-fidelity images. However, misuse of such potent tools can lead to the creation of fake news or disturbing content targeting individuals, resulting in significant social harm. In this paper, we introduce Anti-Reference, a novel method that protects images from the threats posed by reference-based generation techniques by adding imperceptible adversarial noise to the images. We propose a unified loss function that enables joint attacks on fine-tuning-based customization methods, non-fine-tuning customization methods, and human-centric driving methods. Based on this loss, we train a Adversarial Noise Encoder to predict the noise or directly optimize the noise using the PGD method. Our method shows certain transfer attack capabilities, effectively challenging both gray-box models and some commercial APIs. Extensive experiments validate the performance of Anti-Reference, establishing a new benchmark in image security.
An End-To-End Stuttering Detection Method Based On Conformer And BILSTM
Nov 14, 2024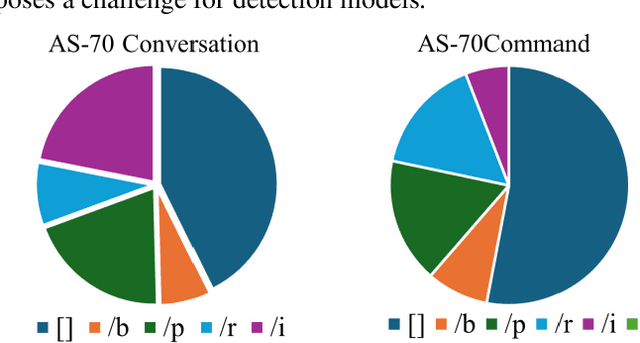

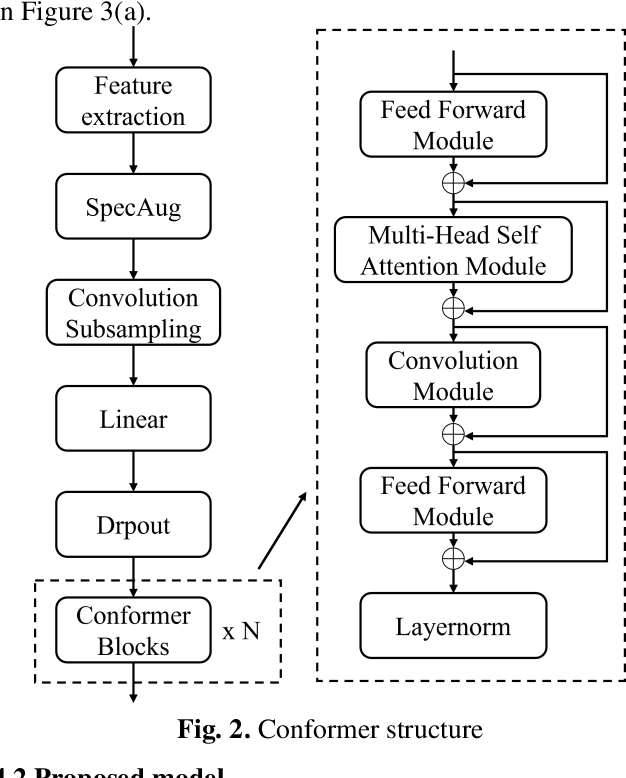

Stuttering is a neurodevelopmental speech disorder characterized by common speech symptoms such as pauses, exclamations, repetition, and prolongation. Speech-language pathologists typically assess the type and severity of stuttering by observing these symptoms. Many effective end-to-end methods exist for stuttering detection, but a commonly overlooked challenge is the uncertain relationship between tasks involved in this process. Using a suitable multi-task strategy could improve stuttering detection performance. This paper presents a novel stuttering event detection model designed to help speech-language pathologists assess both the type and severity of stuttering. First, the Conformer model extracts acoustic features from stuttered speech, followed by a Long Short-Term Memory (LSTM) network to capture contextual information. Finally, we explore multi-task learning for stuttering and propose an effective multi-task strategy. Experimental results show that our model outperforms current state-of-the-art methods for stuttering detection. In the SLT 2024 Stuttering Speech Challenge based on the AS-70 dataset [1], our model improved the mean F1 score by 24.8% compared to the baseline method and achieved first place. On this basis, we conducted relevant extensive experiments on LSTM and multi-task learning strategies respectively. The results show that our proposed method improved the mean F1 score by 39.8% compared to the baseline method.
Automatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network
May 07, 2024



Automatic assessment of dysarthria remains a highly challenging task due to high variability in acoustic signals and the limited data. Currently, research on the automatic assessment of dysarthria primarily focuses on two approaches: one that utilizes expert features combined with machine learning, and the other that employs data-driven deep learning methods to extract representations. Research has demonstrated that expert features are effective in representing pathological characteristics, while deep learning methods excel at uncovering latent features. Therefore, integrating the advantages of expert features and deep learning to construct a neural network architecture based on expert knowledge may be beneficial for interpretability and assessment performance. In this context, the present paper proposes a vowel graph attention network based on audio-visual information, which effectively integrates the strengths of expert knowledges and deep learning. Firstly, various features were combined as inputs, including knowledge based acoustical features and deep learning based pre-trained representations. Secondly, the graph network structure based on vowel space theory was designed, allowing for a deep exploration of spatial correlations among vowels. Finally, visual information was incorporated into the model to further enhance its robustness and generalizability. The method exhibited superior performance in regression experiments targeting Frenchay scores compared to existing approaches.
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Apr 29, 2024



MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
An Audio-textual Diffusion Model For Converting Speech Signals Into Ultrasound Tongue Imaging Data
Mar 12, 2024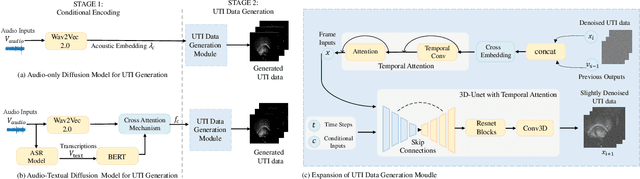
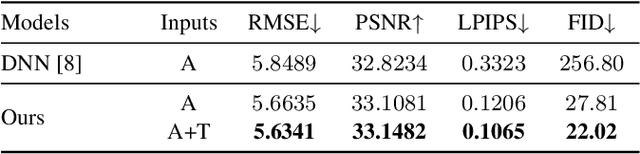

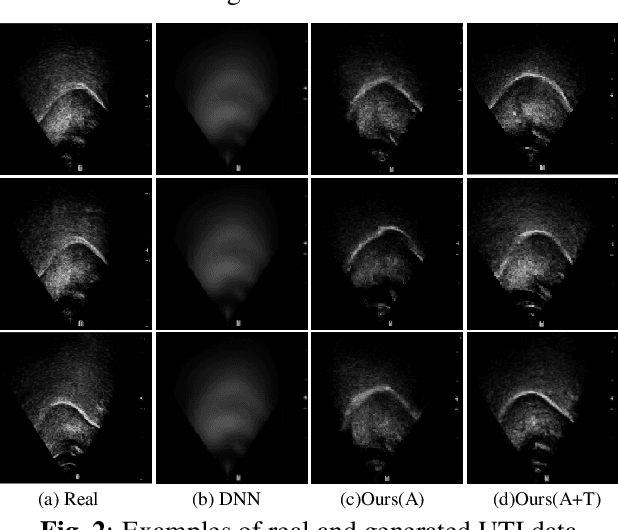
Acoustic-to-articulatory inversion (AAI) is to convert audio into articulator movements, such as ultrasound tongue imaging (UTI) data. An issue of existing AAI methods is only using the personalized acoustic information to derive the general patterns of tongue motions, and thus the quality of generated UTI data is limited. To address this issue, this paper proposes an audio-textual diffusion model for the UTI data generation task. In this model, the inherent acoustic characteristics of individuals related to the tongue motion details are encoded by using wav2vec 2.0, while the ASR transcriptions related to the universality of tongue motions are encoded by using BERT. UTI data are then generated by using a diffusion module. Experimental results showed that the proposed diffusion model could generate high-quality UTI data with clear tongue contour that is crucial for the linguistic analysis and clinical assessment. The project can be found on the website\footnote{https://yangyudong2020.github.io/wav2uti/
Effective Open Intent Classification with K-center Contrastive Learning and Adjustable Decision Boundary
Apr 20, 2023



Open intent classification, which aims to correctly classify the known intents into their corresponding classes while identifying the new unknown (open) intents, is an essential but challenging task in dialogue systems. In this paper, we introduce novel K-center contrastive learning and adjustable decision boundary learning (CLAB) to improve the effectiveness of open intent classification. First, we pre-train a feature encoder on the labeled training instances, which transfers knowledge from known intents to unknown intents. Specifically, we devise a K-center contrastive learning algorithm to learn discriminative and balanced intent features, improving the generalization of the model for recognizing open intents. Second, we devise an adjustable decision boundary learning method with expanding and shrinking (ADBES) to determine the suitable decision conditions. Concretely, we learn a decision boundary for each known intent class, which consists of a decision center and the radius of the decision boundary. We then expand the radius of the decision boundary to accommodate more in-class instances if the out-of-class instances are far from the decision boundary; otherwise, we shrink the radius of the decision boundary. Extensive experiments on three benchmark datasets clearly demonstrate the effectiveness of our method for open intent classification. For reproducibility, we submit the code at: https://github.com/lxk00/CLAP