 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCR: Quantifying Data Contamination in LLMs Evaluation
Jul 15, 2025The rapid advancement of large language models (LLMs) has heightened concerns about benchmark data contamination (BDC), where models inadvertently memorize evaluation data, inflating performance metrics and undermining genuine generalization assessment. This paper introduces the Data Contamination Risk (DCR) framework, a lightweight, interpretable pipeline designed to detect and quantify BDC across four granular levels: semantic, informational, data, and label. By synthesizing contamination scores via a fuzzy inference system, DCR produces a unified DCR Factor that adjusts raw accuracy to reflect contamination-aware performance. Validated on 9 LLMs (0.5B-72B) across sentiment analysis, fake news detection, and arithmetic reasoning tasks, the DCR framework reliably diagnoses contamination severity and with accuracy adjusted using the DCR Factor to within 4% average error across the three benchmarks compared to the uncontaminated baseline. Emphasizing computational efficiency and transparency, DCR provides a practical tool for integrating contamination assessment into routine evaluations, fostering fairer comparisons and enhancing the credibility of LLM benchmarking practices.
Structured Dialogue System for Mental Health: An LLM Chatbot Leveraging the PM+ Guidelines
Nov 16, 2024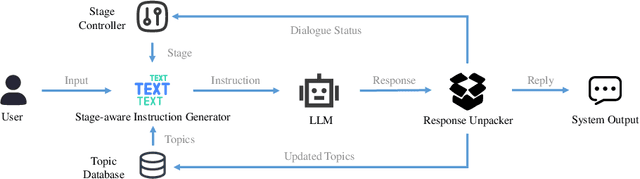



The Structured Dialogue System, referred to as SuDoSys, is an innovative Large Language Model (LLM)-based chatbot designed to provide psychological counseling. SuDoSys leverages the World Health Organization (WHO)'s Problem Management Plus (PM+) guidelines to deliver stage-aware multi-turn dialogues. Existing methods for employing an LLM in multi-turn psychological counseling typically involve direct fine-tuning using generated dialogues, often neglecting the dynamic stage shifts of counseling sessions. Unlike previous approaches, SuDoSys considers the different stages of counseling and stores essential information throughout the counseling process, ensuring coherent and directed conversations. The system employs an LLM, a stage-aware instruction generator, a response unpacker, a topic database, and a stage controller to maintain dialogue flow. In addition, we propose a novel technique that simulates counseling clients to interact with the evaluated system and evaluate its performance automatically. When assessed using both objective and subjective evaluations, SuDoSys demonstrates its effectiveness in generating logically coherent responses. The system's code and program scripts for evaluation are open-sourced.
An End-To-End Stuttering Detection Method Based On Conformer And BILSTM
Nov 14, 2024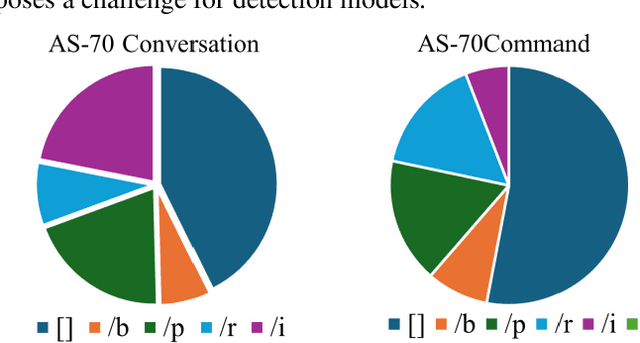

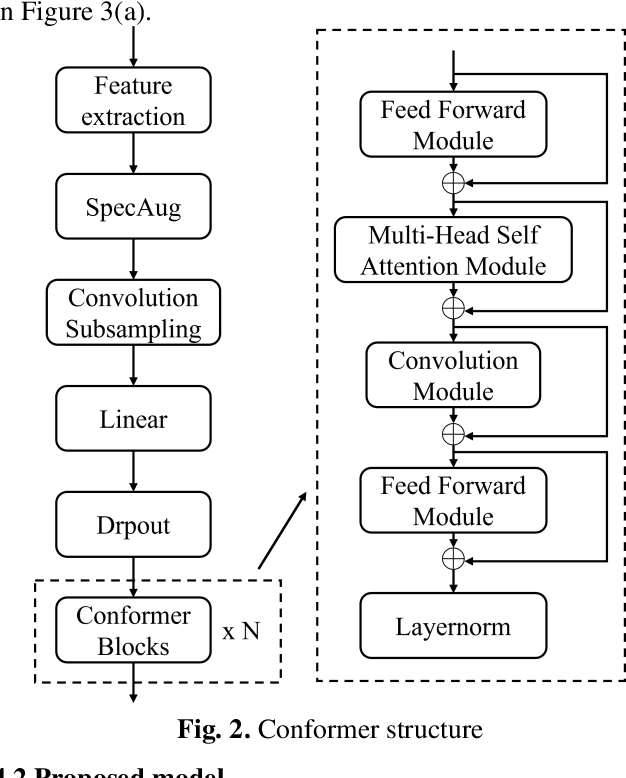

Stuttering is a neurodevelopmental speech disorder characterized by common speech symptoms such as pauses, exclamations, repetition, and prolongation. Speech-language pathologists typically assess the type and severity of stuttering by observing these symptoms. Many effective end-to-end methods exist for stuttering detection, but a commonly overlooked challenge is the uncertain relationship between tasks involved in this process. Using a suitable multi-task strategy could improve stuttering detection performance. This paper presents a novel stuttering event detection model designed to help speech-language pathologists assess both the type and severity of stuttering. First, the Conformer model extracts acoustic features from stuttered speech, followed by a Long Short-Term Memory (LSTM) network to capture contextual information. Finally, we explore multi-task learning for stuttering and propose an effective multi-task strategy. Experimental results show that our model outperforms current state-of-the-art methods for stuttering detection. In the SLT 2024 Stuttering Speech Challenge based on the AS-70 dataset [1], our model improved the mean F1 score by 24.8% compared to the baseline method and achieved first place. On this basis, we conducted relevant extensive experiments on LSTM and multi-task learning strategies respectively. The results show that our proposed method improved the mean F1 score by 39.8% compared to the baseline method.
Perceiver-Prompt: Flexible Speaker Adaptation in Whisper for Chinese Disordered Speech Recognition
Jun 14, 2024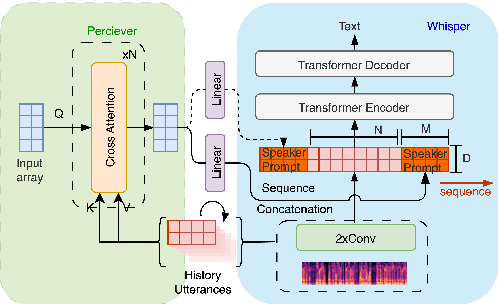
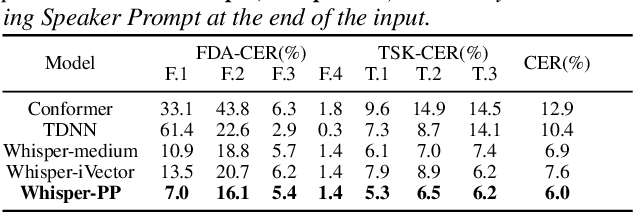
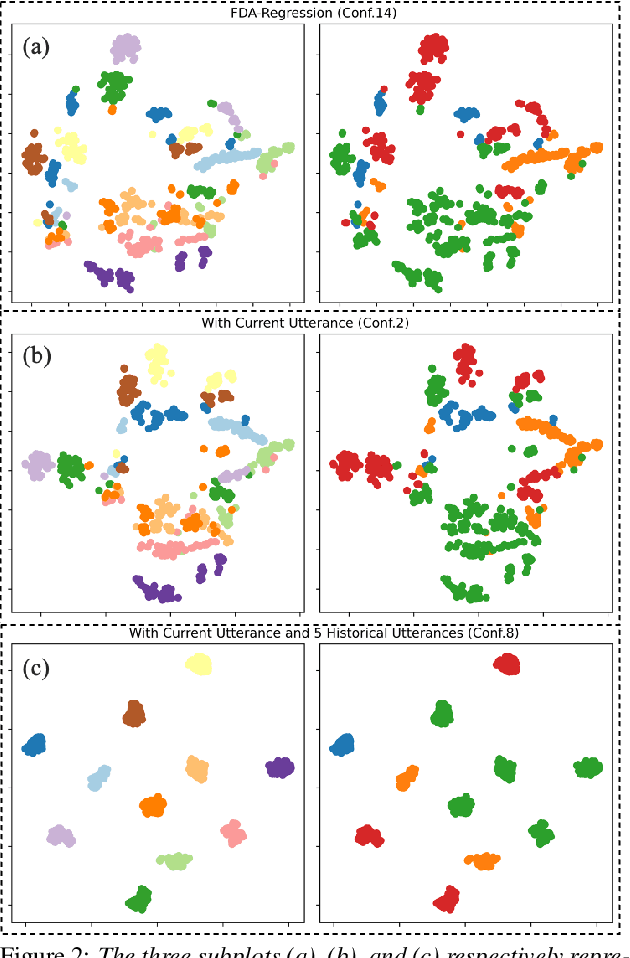
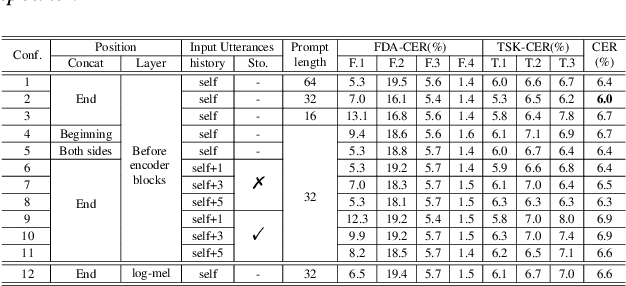
Disordered speech recognition profound implications for improving the quality of life for individuals afflicted with, for example, dysarthria. Dysarthric speech recognition encounters challenges including limited data, substantial dissimilarities between dysarthric and non-dysarthric speakers, and significant speaker variations stemming from the disorder. This paper introduces Perceiver-Prompt, a method for speaker adaptation that utilizes P-Tuning on the Whisper large-scale model. We first fine-tune Whisper using LoRA and then integrate a trainable Perceiver to generate fixed-length speaker prompts from variable-length inputs, to improve model recognition of Chinese dysarthric speech. Experimental results from our Chinese dysarthric speech dataset demonstrate consistent improvements in recognition performance with Perceiver-Prompt. Relative reduction up to 13.04% in CER is obtained over the fine-tuned Whisper.
Automatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network
May 07, 2024



Automatic assessment of dysarthria remains a highly challenging task due to high variability in acoustic signals and the limited data. Currently, research on the automatic assessment of dysarthria primarily focuses on two approaches: one that utilizes expert features combined with machine learning, and the other that employs data-driven deep learning methods to extract representations. Research has demonstrated that expert features are effective in representing pathological characteristics, while deep learning methods excel at uncovering latent features. Therefore, integrating the advantages of expert features and deep learning to construct a neural network architecture based on expert knowledge may be beneficial for interpretability and assessment performance. In this context, the present paper proposes a vowel graph attention network based on audio-visual information, which effectively integrates the strengths of expert knowledges and deep learning. Firstly, various features were combined as inputs, including knowledge based acoustical features and deep learning based pre-trained representations. Secondly, the graph network structure based on vowel space theory was designed, allowing for a deep exploration of spatial correlations among vowels. Finally, visual information was incorporated into the model to further enhance its robustness and generalizability. The method exhibited superior performance in regression experiments targeting Frenchay scores compared to existing approaches.
An Audio-textual Diffusion Model For Converting Speech Signals Into Ultrasound Tongue Imaging Data
Mar 12, 2024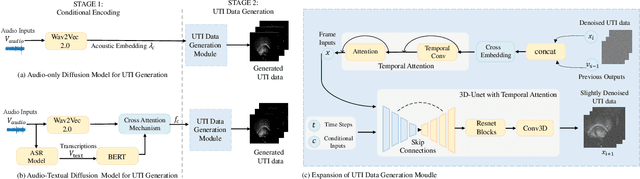
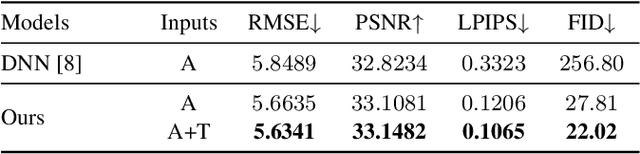

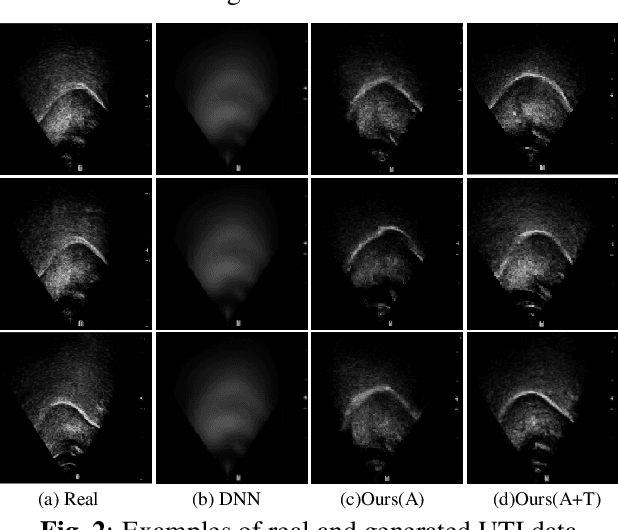
Acoustic-to-articulatory inversion (AAI) is to convert audio into articulator movements, such as ultrasound tongue imaging (UTI) data. An issue of existing AAI methods is only using the personalized acoustic information to derive the general patterns of tongue motions, and thus the quality of generated UTI data is limited. To address this issue, this paper proposes an audio-textual diffusion model for the UTI data generation task. In this model, the inherent acoustic characteristics of individuals related to the tongue motion details are encoded by using wav2vec 2.0, while the ASR transcriptions related to the universality of tongue motions are encoded by using BERT. UTI data are then generated by using a diffusion module. Experimental results showed that the proposed diffusion model could generate high-quality UTI data with clear tongue contour that is crucial for the linguistic analysis and clinical assessment. The project can be found on the website\footnote{https://yangyudong2020.github.io/wav2uti/
Enhanced Memory Network: The novel network structure for Symbolic Music Generation
Oct 07, 2021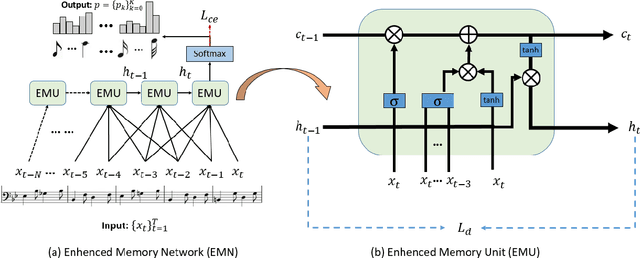
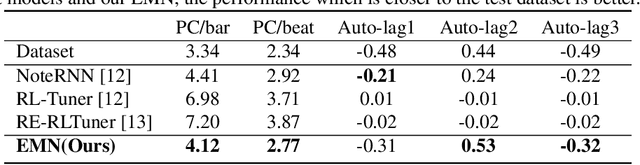
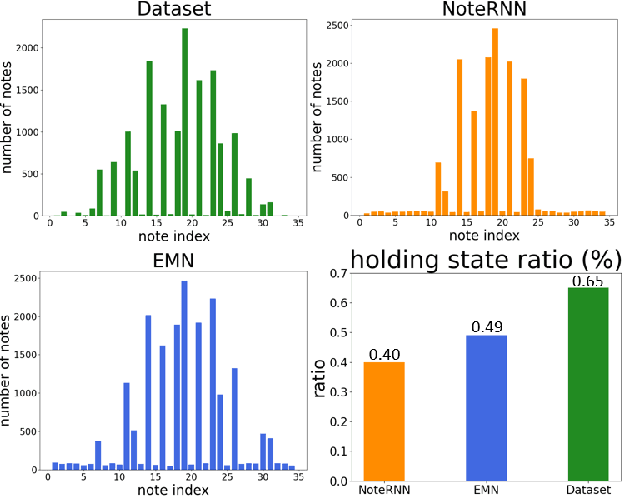
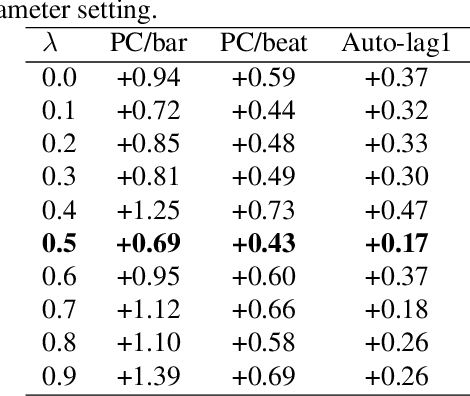
Symbolic melodies generation is one of the essential tasks for automatic music generation. Recently, models based on neural networks have had a significant influence on generating symbolic melodies. However, the musical context structure is complicated to capture through deep neural networks. Although long short-term memory (LSTM) is attempted to solve this problem through learning order dependence in the musical sequence, it is not capable of capturing musical context with only one note as input for each time step of LSTM. In this paper, we propose a novel Enhanced Memory Network (EMN) with several recurrent units, named Enhanced Memory Unit (EMU), to explicitly modify the internal architecture of LSTM for containing music beat information and reinforces the memory of the latest musical beat through aggregating beat inside the memory gate. In addition, to increase the diversity of generated musical notes, cosine distance among adjacent time steps of hidden states is considered as part of loss functions to avoid a high similarity score that harms the diversity of generated notes. Objective and subjective evaluation results show that the proposed method achieves state-of-the-art performance. Code and music demo are available at https://github.com/qrqrqrqr/EMU
Unsupervised Cross-Lingual Speech Emotion Recognition Using Pseudo Multilabel
Aug 19, 2021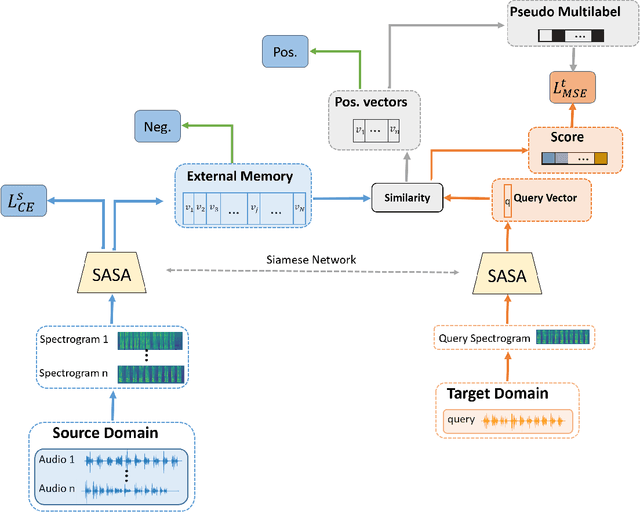
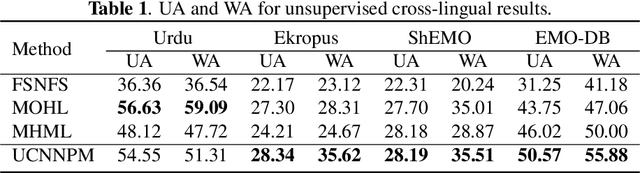

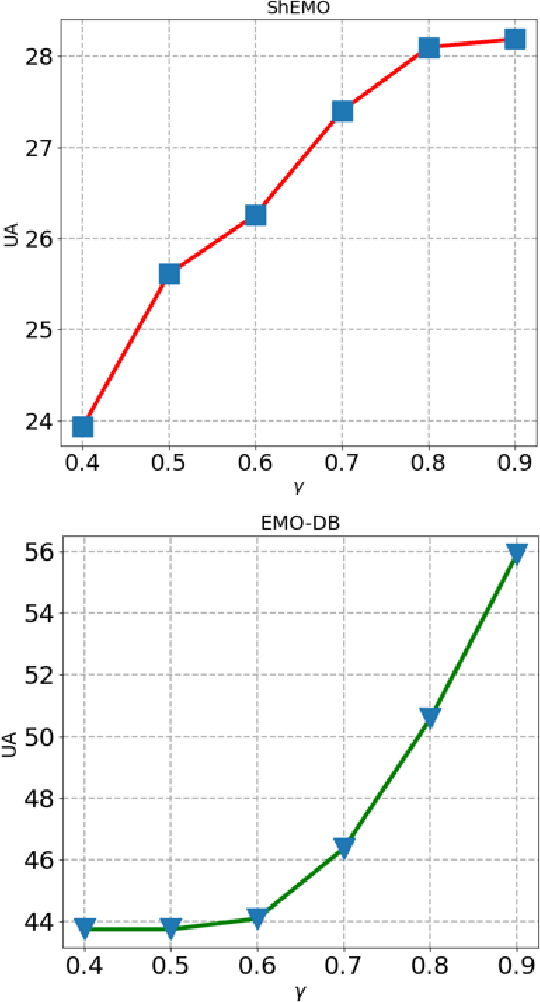
Speech Emotion Recognition (SER) in a single language has achieved remarkable results through deep learning approaches in the last decade. However, cross-lingual SER remains a challenge in real-world applications due to a great difference between the source and target domain distributions. To address this issue, we propose an Unsupervised Cross-Lingual Neural Network with Pseudo Multilabel (UCNNPM) that is trained to learn the emotion similarities between source domain features inside an external memory adjusted to identify emotion in cross-lingual databases. UCNNPM introduces a novel approach that leverages external memory to store source domain features and generates pseudo multilabel for each target domain data by computing the similarities between the external memory and the target domain features. We evaluate our approach on multiple different languages of speech emotion databases. Experimental results show our proposed approach significantly improves the weighted accuracy (WA) across multiple low-resource languages on Urdu, Skropus, ShEMO, and EMO-DB corpus.
Two Streams and Two Resolution Spectrograms Model for End-to-end Automatic Speech Recognition
Aug 18, 2021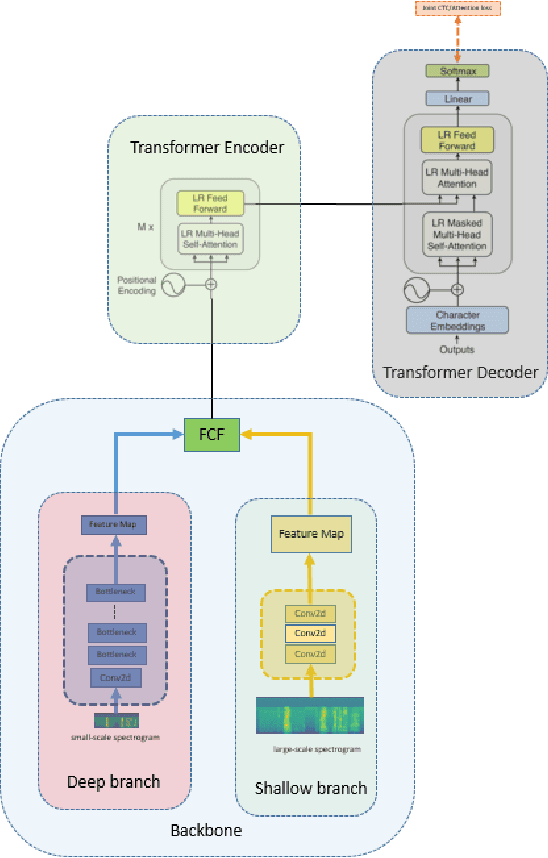
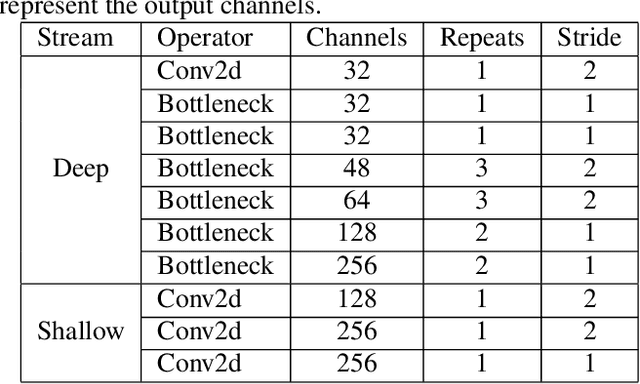

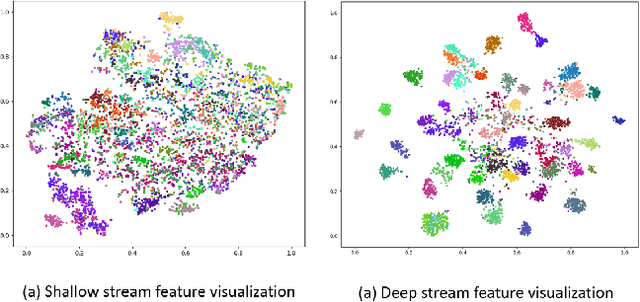
Transformer has shown tremendous progress in Automatic Speech Recognition (ASR), outperforming recurrent neural network-based approaches. Transformer architecture is good at parallelizing data to accelerate as well as capturing content-based global interaction. However, most studies with Transfomer have been utilized only shallow features extracted from the backbone without taking advantage of the deep feature that possesses invariant property. In this paper, we propose a novel framework with two streams that consist of different resolution spectrograms for each steam aiming to capture both shallow and deep features. The feature extraction module consists of a deep network for small resolution spectrogram and a shallow network for large resolution spectrogram. The backbone obtains not only detailed acoustic information for speech-text alignment but also sentence invariant features such as speaker information. Both features are fused with our proposed fusion method and then input into the Transformer encoder-decoder. With our method, the proposed framework shows competitive performance on Mandarin corpus. It outperforms various current state-of-the-art results on the HKUST Mandarian telephone ASR benchmark with a CER of 21.08. To the best of our knowledge, this is the first investigation of incorporating deep features to the backbone.
FDN: Finite Difference Network with Hierachical Convolutional Features for Text-independent Speaker verification
Aug 18, 2021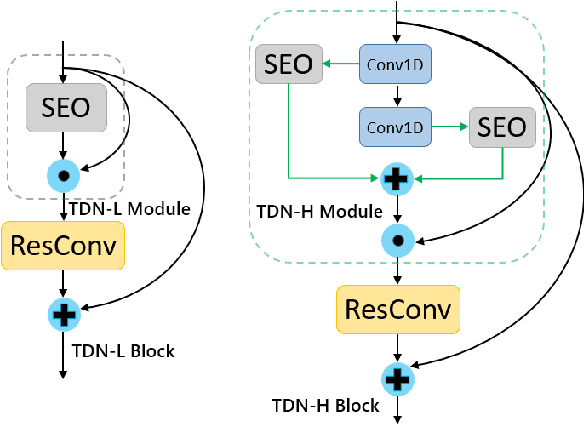
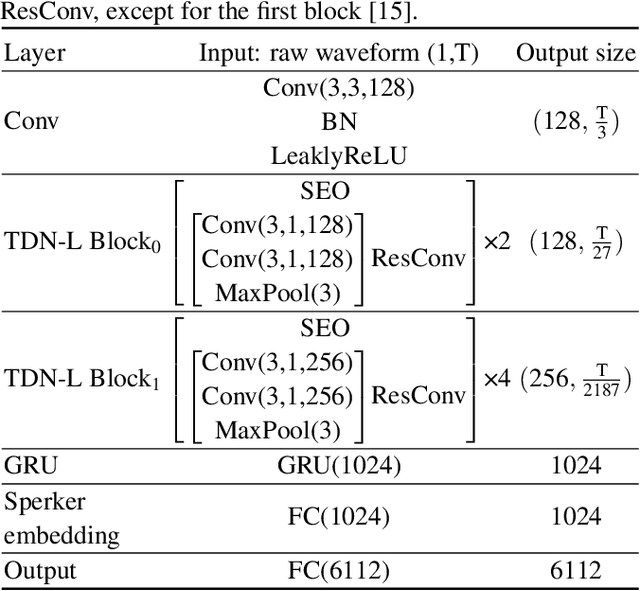
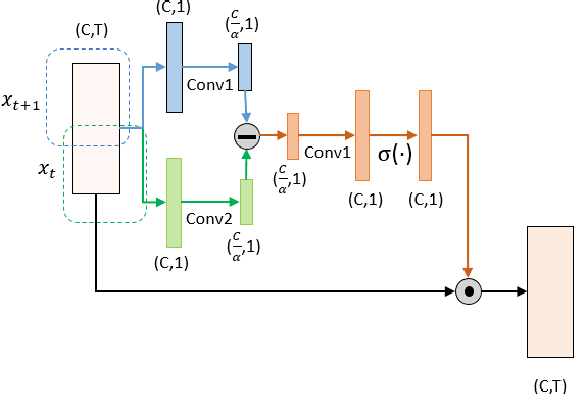
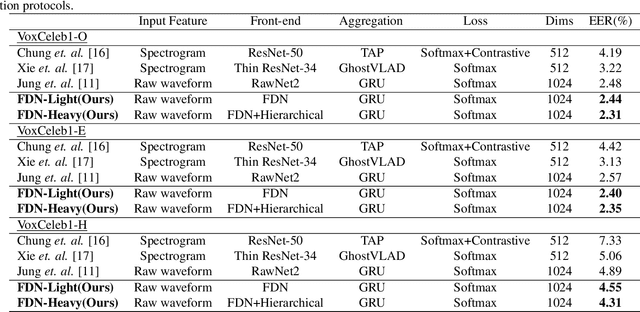
Recently, directly utilize raw waveforms as input is widely explored for the speaker verification system. For example, RawNet [1] and RawNet2 [2] extract feature embeddings from raw waveforms, which largely reduce the front-end computation and achieve state-of-the-art performance. However, they do not consider the speech speed influence which is different from person to person. In this paper, we propose a novel finite-difference network to obtain speaker embeddings. It incorporates speaker speech speed by computing the finite difference between adjacent time speech pieces. Furthermore, we design a hierarchical layer to capture multiscale speech speed features to improve the system accuracy. The speaker embeddings is then input into the GRU to aggregate utterance-level features before the softmax loss. Experiment results on official VoxCeleb1 test data and expanded evaluation on VoxCeleb1-E and VoxCeleb-H protocols show our method outperforms existing state-of-the-art systems. To facilitate further research, code is available at https://github.com/happyjin/FDN