 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDN: Finite Difference Network with Hierachical Convolutional Features for Text-independent Speaker verification
Paper and Code
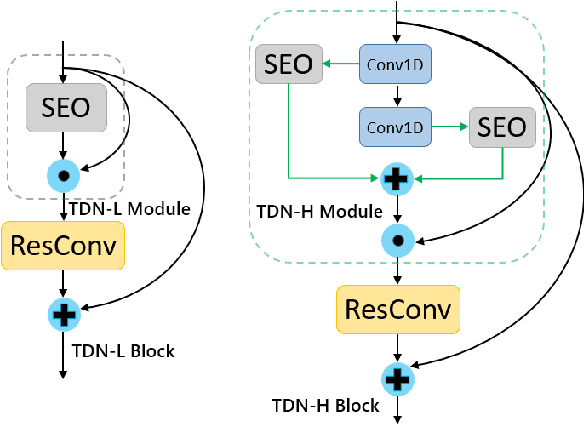
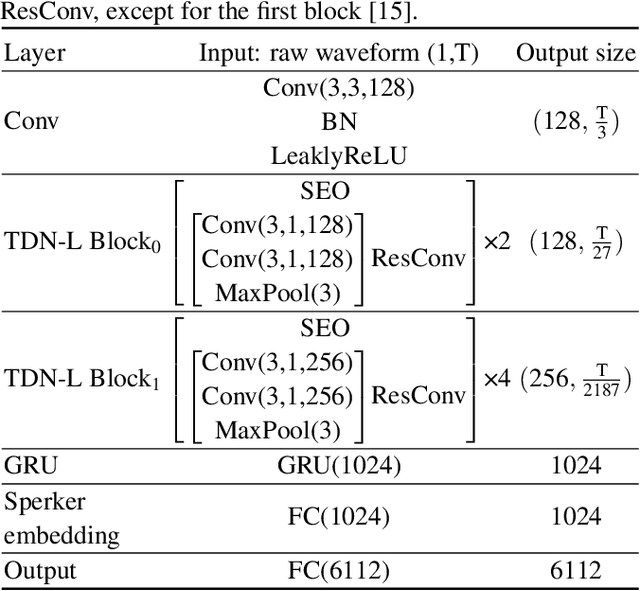
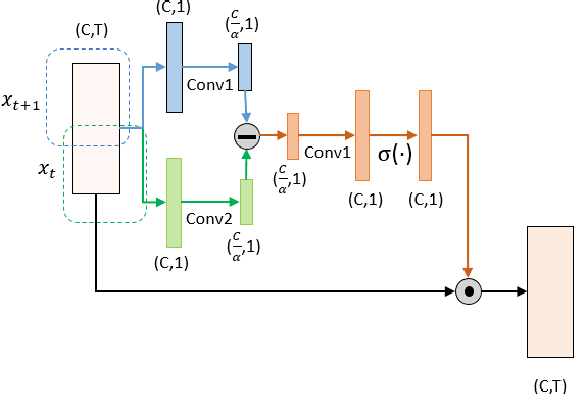
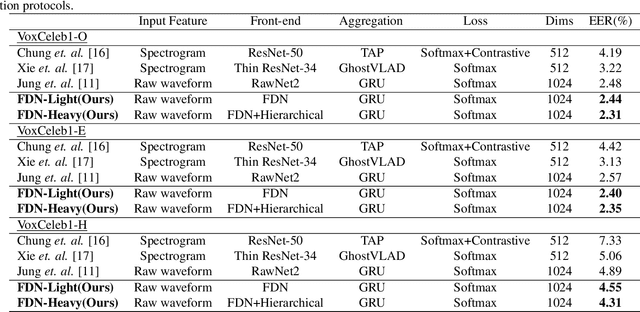
Recently, directly utilize raw waveforms as input is widely explored for the speaker verification system. For example, RawNet [1] and RawNet2 [2] extract feature embeddings from raw waveforms, which largely reduce the front-end computation and achieve state-of-the-art performance. However, they do not consider the speech speed influence which is different from person to person. In this paper, we propose a novel finite-difference network to obtain speaker embeddings. It incorporates speaker speech speed by computing the finite difference between adjacent time speech pieces. Furthermore, we design a hierarchical layer to capture multiscale speech speed features to improve the system accuracy. The speaker embeddings is then input into the GRU to aggregate utterance-level features before the softmax loss. Experiment results on official VoxCeleb1 test data and expanded evaluation on VoxCeleb1-E and VoxCeleb-H protocols show our method outperforms existing state-of-the-art systems. To facilitate further research, code is available at https://github.com/happyjin/FDN