 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
Feb 03, 2026Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning. More results can be found on our project website at https://BridgeV2W.github.io .
VERM: Leveraging Foundation Models to Create a Virtual Eye for Efficient 3D Robotic Manipulation
Dec 18, 2025When performing 3D manipulation tasks, robots have to execute action planning based on perceptions from multiple fixed cameras. The multi-camera setup introduces substantial redundancy and irrelevant information, which increases computational costs and forces the model to spend extra training time extracting crucial task-relevant details. To filter out redundant information and accurately extract task-relevant features, we propose the VERM (Virtual Eye for Robotic Manipulation) method, leveraging the knowledge in foundation models to imagine a virtual task-adaptive view from the constructed 3D point cloud, which efficiently captures necessary information and mitigates occlusion. To facilitate 3D action planning and fine-grained manipulation, we further design a depth-aware module and a dynamic coarse-to-fine procedure. Extensive experimental results on both simulation benchmark RLBench and real-world evaluations demonstrate the effectiveness of our method, surpassing previous state-of-the-art methods while achieving 1.89x speedup in training time and 1.54x speedup in inference speed. More results can be found on our project website at https://verm-ral.github.io .
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025


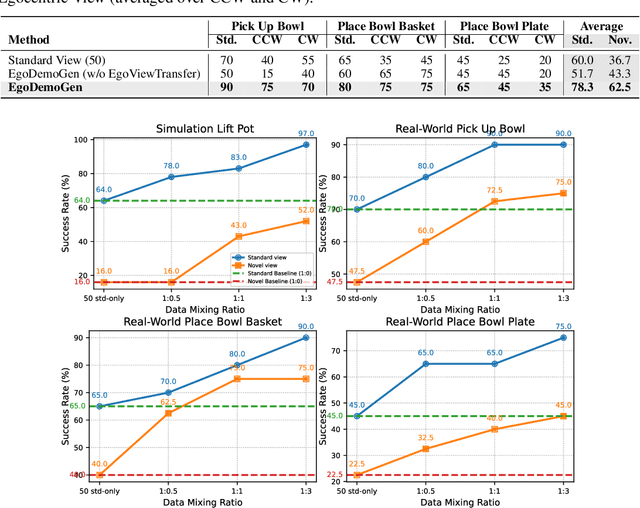
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
DTPA: Dynamic Token-level Prefix Augmentation for Controllable Text Generation
Aug 06, 2025



Controllable Text Generation (CTG) is a vital subfield in Natural Language Processing (NLP), aiming to generate text that aligns with desired attributes. However, previous studies commonly focus on the quality of controllable text generation for short sequences, while the generation of long-form text remains largely underexplored. In this paper, we observe that the controllability of texts generated by the powerful prefix-based method Air-Decoding tends to decline with increasing sequence length, which we hypothesize primarily arises from the observed decay in attention to the prefixes. Meanwhile, different types of prefixes including soft and hard prefixes are also key factors influencing performance. Building on these insights, we propose a lightweight and effective framework called Dynamic Token-level Prefix Augmentation (DTPA) based on Air-Decoding for controllable text generation. Specifically, it first selects the optimal prefix type for a given task. Then we dynamically amplify the attention to the prefix for the attribute distribution to enhance controllability, with a scaling factor growing exponentially as the sequence length increases. Moreover, based on the task, we optionally apply a similar augmentation to the original prompt for the raw distribution to balance text quality. After attribute distribution reconstruction, the generated text satisfies the attribute constraints well. Experiments on multiple CTG tasks demonstrate that DTPA generally outperforms other methods in attribute control while maintaining competitive fluency, diversity, and topic relevance. Further analysis highlights DTPA's superior effectiveness in long text generation.
FashionPose: Text to Pose to Relight Image Generation for Personalized Fashion Visualization
Jul 17, 2025
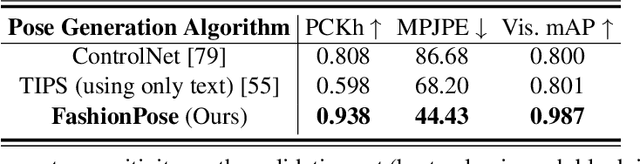
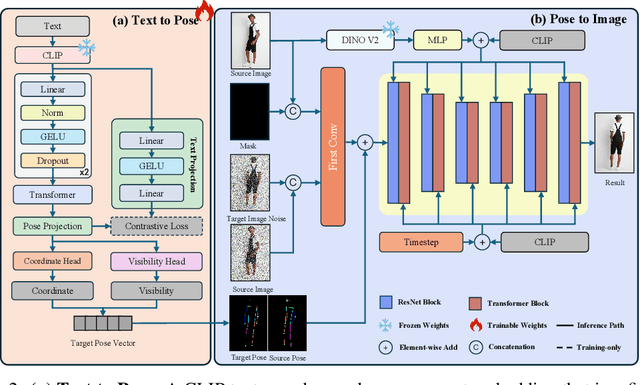
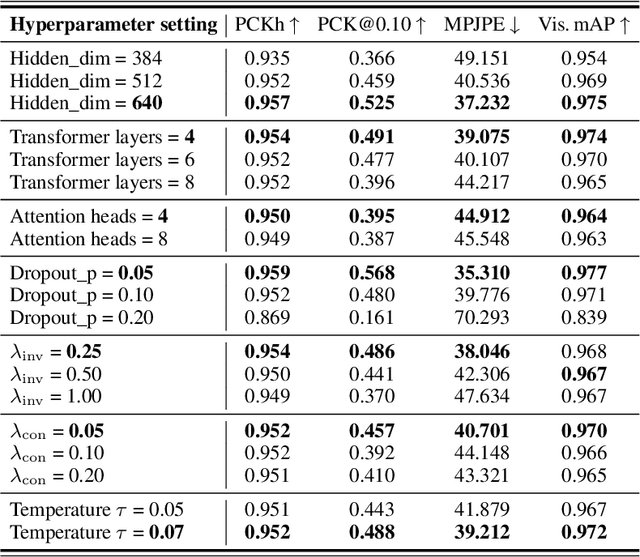
Realistic and controllable garment visualization is critical for fashion e-commerce, where users expect personalized previews under diverse poses and lighting conditions. Existing methods often rely on predefined poses, limiting semantic flexibility and illumination adaptability. To address this, we introduce FashionPose, the first unified text-to-pose-to-relighting generation framework. Given a natural language description, our method first predicts a 2D human pose, then employs a diffusion model to generate high-fidelity person images, and finally applies a lightweight relighting module, all guided by the same textual input. By replacing explicit pose annotations with text-driven conditioning, FashionPose enables accurate pose alignment, faithful garment rendering, and flexible lighting control. Experiments demonstrate fine-grained pose synthesis and efficient, consistent relighting, providing a practical solution for personalized virtual fashion display.
EC-Flow: Enabling Versatile Robotic Manipulation from Action-Unlabeled Videos via Embodiment-Centric Flow
Jul 08, 2025
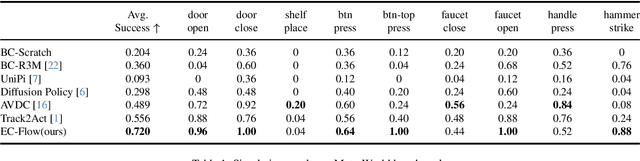
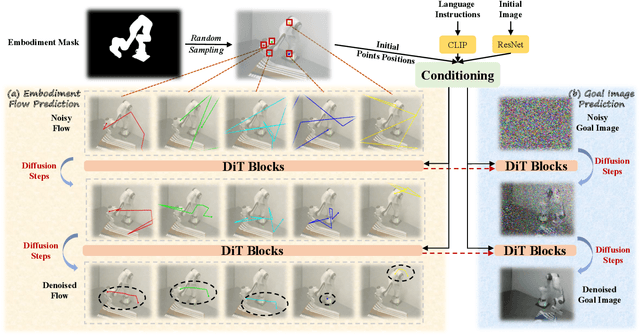
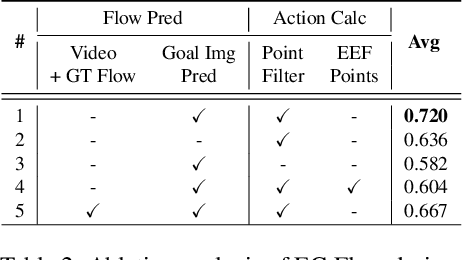
Current language-guided robotic manipulation systems often require low-level action-labeled datasets for imitation learning. While object-centric flow prediction methods mitigate this issue, they remain limited to scenarios involving rigid objects with clear displacement and minimal occlusion. In this work, we present Embodiment-Centric Flow (EC-Flow), a framework that directly learns manipulation from action-unlabeled videos by predicting embodiment-centric flow. Our key insight is that incorporating the embodiment's inherent kinematics significantly enhances generalization to versatile manipulation scenarios, including deformable object handling, occlusions, and non-object-displacement tasks. To connect the EC-Flow with language instructions and object interactions, we further introduce a goal-alignment module by jointly optimizing movement consistency and goal-image prediction. Moreover, translating EC-Flow to executable robot actions only requires a standard robot URDF (Unified Robot Description Format) file to specify kinematic constraints across joints, which makes it easy to use in practice. We validate EC-Flow on both simulation (Meta-World) and real-world tasks, demonstrating its state-of-the-art performance in occluded object handling (62% improvement), deformable object manipulation (45% improvement), and non-object-displacement tasks (80% improvement) than prior state-of-the-art object-centric flow methods. For more information, see our project website at https://ec-flow1.github.io .
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
MRD-RAG: Enhancing Medical Diagnosis with Multi-Round Retrieval-Augmented Generation
Apr 10, 2025In recent years, accurately and quickly deploying medical large language models (LLMs) has become a significant trend. Among these, retrieval-augmented generation (RAG) has garnered significant attention due to its features of rapid deployment and privacy protection. However, existing medical RAG frameworks still have shortcomings. Most existing medical RAG frameworks are designed for single-round question answering tasks and are not suitable for multi-round diagnostic dialogue. On the other hand, existing medical multi-round RAG frameworks do not consider the interconnections between potential diseases to inquire precisely like a doctor. To address these issues, we propose a Multi-Round Diagnostic RAG (MRD-RAG) framework that mimics the doctor's diagnostic process. This RAG framework can analyze diagnosis information of potential diseases and accurately conduct multi-round diagnosis like a doctor. To evaluate the effectiveness of our proposed frameworks, we conduct experiments on two modern medical datasets and two traditional Chinese medicine datasets, with evaluations by GPT and human doctors on different methods. The results indicate that our RAG framework can significantly enhance the diagnostic performance of LLMs, highlighting the potential of our approach in medical diagnosis. The code and data can be found in our project website https://github.com/YixiangCh/MRD-RAG/tree/master.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025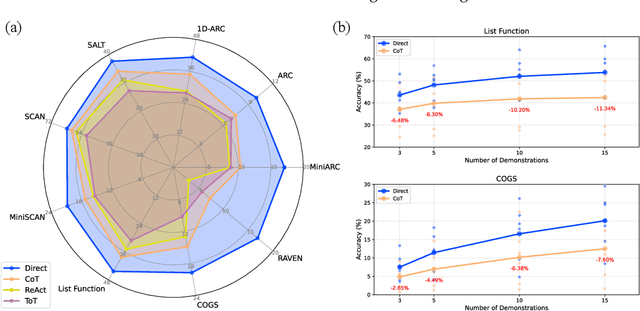
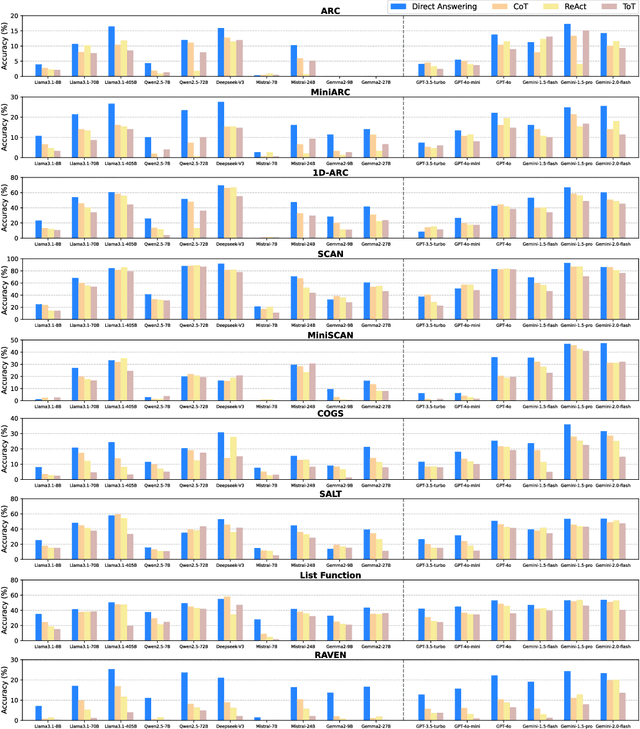
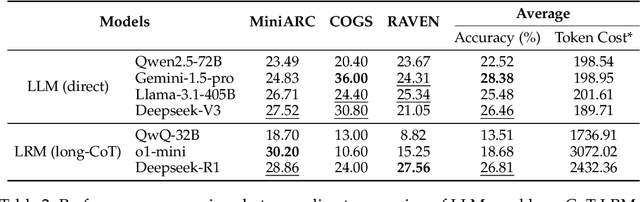
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.