 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Embodied Chain-of-Thought for Generalizable Robot Manipulation
Jun 03, 2026Embodied chain-of-thought (CoT) aims to bridge linguistic reasoning and robotic control, but its effective form and integration strategy remain underexplored. In this paper, we revisit embodied CoT for vision-language-action (VLA) models at large scale. We construct the largest embodied CoT corpus to date, comprising 978,743 trajectories, 226.3M samples, and 2592.5 hours of robot data. Through extensive experiments, we find that effective embodied CoT should ground high-level semantic understanding into concrete action guidance, such as end-effector movement descriptions and image-space trajectories, while high-level reasoning alone brings only marginal gains. We further show that explicit CoT does not scale reliably when used as an autoregressive action prefix, as it suffers from compounding inference errors and unstable reasoning-action coupling. To address these limitations, we propose ERVLA, a VLA model that uses embodied CoT as representation-shaping supervision rather than mandatory test-time reasoning. ERVLA is trained with a reasoning-dropout strategy, enabling the model to absorb rich reasoning traces during training while predicting actions directly without CoT decoding during inference. This design improves scalability with increasing pre-training data and avoids autoregressive instability. ERVLA achieves state-of-the-art performance on LIBERO-Plus with an 86.9% success rate and reaches 53.2% success rate on VLABench, demonstrating strong out-of-distribution generalization. In real-robot experiments, ERVLA further outperforms competitive state-of-the-art baselines, especially on tasks requiring semantic disambiguation and long-horizon execution.
SKIP: Sparse Keyframe Interpolation Paradigm for Efficient Embodied World Models
May 30, 2026Embodied world models have emerged as a promising paradigm in robotics by predicting how robot actions affect the surrounding scene. However, the rollout inference remains computationally expensive in pixel space, as long-horizon manipulation videos typically have to be generated frame by frame. This cost cannot be easily reduced by indiscriminately dropping frames, since downstream policies rely on complete preservation of sparse task-relevant events such as approach, contact, grasp, and release. To address this challenge, we propose Sparse Keyframe Interpolation Paradigm (SKIP), an event-preserving sparse-to-dense framework that avoids dense frame-by-frame generation. SKIP first identifies task-relevant keyframes by leveraging robot-aware multimodal features. It then synthesizes only these keyframes with a sparse video diffusion model. A learned gap predictor and an action-conditioned interpolator subsequently reconstruct the missing intervals according to the robot actions. On LIBERO, SKIP generates dense rollouts $4.16\times$ faster than a dense baseline while improving visual fidelity and reducing aggregate FVD by $89.0\%$. Importantly, SKIP-generated videos are effective policy-training data. Even when they fully replace real demonstrations, $π_{0.5}$ success drops only $1.3$ pp in LIBERO simulation and $6.7$ pp on the real robot, whereas fully dense frame-by-frame generation collapses by $48$ to $58$ pp.
RotVLA: Rotational Latent Action for Vision-Language-Action Model
May 13, 2026Latent Action Models (LAMs) have emerged as an effective paradigm for handling heterogeneous datasets during Vision-Language-Action (VLA) model pretraining, offering a unified action space across embodiments. However, existing LAMs often rely on discrete quantization encode and decode pipelines, which can lead to trivial frame reconstruction behavior, limited representational capacity, and a lack of physically meaningful structure. We introduce RotVLA, a VLA framework built on a continuous rotational latent action representation. Latent actions are modeled as elements of SO(n), providing continuity, compositionality, and structured geometry aligned with real-world action dynamics. A triplet frame learning framework further enforces meaningful temporal dynamics while avoiding degeneration. RotVLA consists of a VLM backbone and a flow-matching action head, pretrained on large-scale cross-embodiment robotic datasets and human videos with latent-action supervision. For downstream robot control, the flow-matching head is extended into a unified action expert that jointly denoises latent and robot actions. Here, latent actions serve as a latent planner, providing high-level guidance that conditions action generation. With only 1.7B parameters and 1700+ hours of pretraining data, RotVLA achieves 98.2% on LIBERO and 89.6% / 88.5% on RoboTwin2.0 under clean and randomized settings, respectively. It also demonstrates strong real-world performance on manipulation tasks, consistently outperforming existing VLA models.
Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
Scaling World Model for Hierarchical Manipulation Policies
Feb 12, 2026Vision-Language-Action (VLA) models are promising for generalist robot manipulation but remain brittle in out-of-distribution (OOD) settings, especially with limited real-robot data. To resolve the generalization bottleneck, we introduce a hierarchical Vision-Language-Action framework \our{} that leverages the generalization of large-scale pre-trained world model for robust and generalizable VIsual Subgoal TAsk decomposition VISTA. Our hierarchical framework \our{} consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios. We validate both visual goal synthesis and our hierarchical VLA policies in massive out-of-distribution scenarios, and the performance of the same-structured VLA in novel scenarios could boost from 14% to 69% with the guidance generated by the world model. Results demonstrate that our method outperforms previous baselines with a clear margin, particularly in out-of-distribution scenarios. Project page: \href{https://vista-wm.github.io/}{https://vista-wm.github.io}
BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
Feb 03, 2026Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning. More results can be found on our project website at https://BridgeV2W.github.io .
VERM: Leveraging Foundation Models to Create a Virtual Eye for Efficient 3D Robotic Manipulation
Dec 18, 2025When performing 3D manipulation tasks, robots have to execute action planning based on perceptions from multiple fixed cameras. The multi-camera setup introduces substantial redundancy and irrelevant information, which increases computational costs and forces the model to spend extra training time extracting crucial task-relevant details. To filter out redundant information and accurately extract task-relevant features, we propose the VERM (Virtual Eye for Robotic Manipulation) method, leveraging the knowledge in foundation models to imagine a virtual task-adaptive view from the constructed 3D point cloud, which efficiently captures necessary information and mitigates occlusion. To facilitate 3D action planning and fine-grained manipulation, we further design a depth-aware module and a dynamic coarse-to-fine procedure. Extensive experimental results on both simulation benchmark RLBench and real-world evaluations demonstrate the effectiveness of our method, surpassing previous state-of-the-art methods while achieving 1.89x speedup in training time and 1.54x speedup in inference speed. More results can be found on our project website at https://verm-ral.github.io .
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025


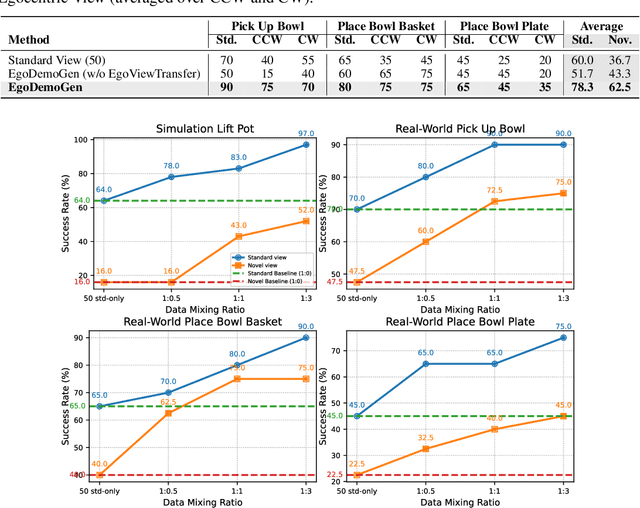
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
DTPA: Dynamic Token-level Prefix Augmentation for Controllable Text Generation
Aug 06, 2025



Controllable Text Generation (CTG) is a vital subfield in Natural Language Processing (NLP), aiming to generate text that aligns with desired attributes. However, previous studies commonly focus on the quality of controllable text generation for short sequences, while the generation of long-form text remains largely underexplored. In this paper, we observe that the controllability of texts generated by the powerful prefix-based method Air-Decoding tends to decline with increasing sequence length, which we hypothesize primarily arises from the observed decay in attention to the prefixes. Meanwhile, different types of prefixes including soft and hard prefixes are also key factors influencing performance. Building on these insights, we propose a lightweight and effective framework called Dynamic Token-level Prefix Augmentation (DTPA) based on Air-Decoding for controllable text generation. Specifically, it first selects the optimal prefix type for a given task. Then we dynamically amplify the attention to the prefix for the attribute distribution to enhance controllability, with a scaling factor growing exponentially as the sequence length increases. Moreover, based on the task, we optionally apply a similar augmentation to the original prompt for the raw distribution to balance text quality. After attribute distribution reconstruction, the generated text satisfies the attribute constraints well. Experiments on multiple CTG tasks demonstrate that DTPA generally outperforms other methods in attribute control while maintaining competitive fluency, diversity, and topic relevance. Further analysis highlights DTPA's superior effectiveness in long text generation.
EC-Flow: Enabling Versatile Robotic Manipulation from Action-Unlabeled Videos via Embodiment-Centric Flow
Jul 08, 2025
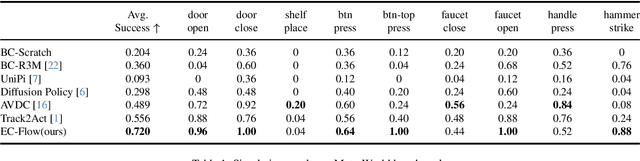
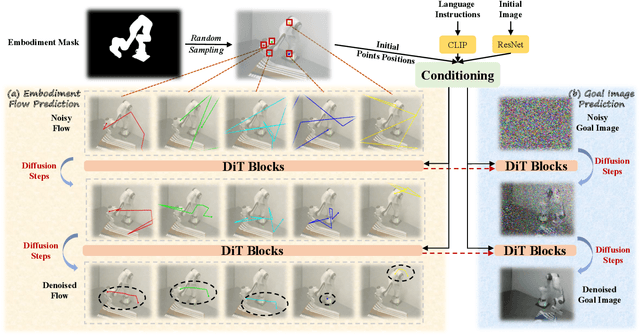
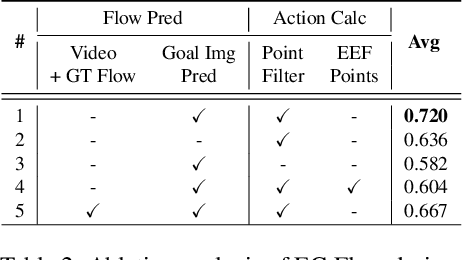
Current language-guided robotic manipulation systems often require low-level action-labeled datasets for imitation learning. While object-centric flow prediction methods mitigate this issue, they remain limited to scenarios involving rigid objects with clear displacement and minimal occlusion. In this work, we present Embodiment-Centric Flow (EC-Flow), a framework that directly learns manipulation from action-unlabeled videos by predicting embodiment-centric flow. Our key insight is that incorporating the embodiment's inherent kinematics significantly enhances generalization to versatile manipulation scenarios, including deformable object handling, occlusions, and non-object-displacement tasks. To connect the EC-Flow with language instructions and object interactions, we further introduce a goal-alignment module by jointly optimizing movement consistency and goal-image prediction. Moreover, translating EC-Flow to executable robot actions only requires a standard robot URDF (Unified Robot Description Format) file to specify kinematic constraints across joints, which makes it easy to use in practice. We validate EC-Flow on both simulation (Meta-World) and real-world tasks, demonstrating its state-of-the-art performance in occluded object handling (62% improvement), deformable object manipulation (45% improvement), and non-object-displacement tasks (80% improvement) than prior state-of-the-art object-centric flow methods. For more information, see our project website at https://ec-flow1.github.io .