 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
Unified Vision-Language-Action Model
Jun 24, 2025



Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
SafeGenBench: A Benchmark Framework for Security Vulnerability Detection in LLM-Generated Code
Jun 06, 2025The code generation capabilities of large language models(LLMs) have emerged as a critical dimension in evaluating their overall performance. However, prior research has largely overlooked the security risks inherent in the generated code. In this work, we introduce \benchmark, a benchmark specifically designed to assess the security of LLM-generated code. The dataset encompasses a wide range of common software development scenarios and vulnerability types. Building upon this benchmark, we develop an automatic evaluation framework that leverages both static application security testing(SAST) and LLM-based judging to assess the presence of security vulnerabilities in model-generated code. Through the empirical evaluation of state-of-the-art LLMs on \benchmark, we reveal notable deficiencies in their ability to produce vulnerability-free code. Our findings highlight pressing challenges and offer actionable insights for future advancements in the secure code generation performance of LLMs. The data and code will be released soon.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024

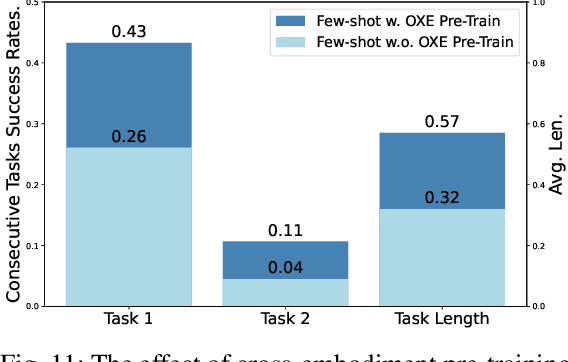

Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
Sparse Spectral Training and Inference on Euclidean and Hyperbolic Neural Networks
May 24, 2024The growing computational demands posed by increasingly number of neural network's parameters necessitate low-memory-consumption training approaches. Previous memory reduction techniques, such as Low-Rank Adaptation (LoRA) and ReLoRA, suffer from the limitation of low rank and saddle point issues, particularly during intensive tasks like pre-training. In this paper, we propose Sparse Spectral Training (SST), an advanced training methodology that updates all singular values and selectively updates singular vectors of network weights, thereby optimizing resource usage while closely approximating full-rank training. SST refines the training process by employing a targeted updating strategy for singular vectors, which is determined by a multinomial sampling method weighted by the significance of the singular values, ensuring both high performance and memory reduction. Through comprehensive testing on both Euclidean and hyperbolic neural networks across various tasks, including natural language generation, machine translation, node classification and link prediction, SST demonstrates its capability to outperform existing memory reduction training methods and is comparable with full-rank training in some cases. On OPT-125M, with rank equating to 8.3% of embedding dimension, SST reduces the perplexity gap to full-rank training by 67.6%, demonstrating a significant reduction of the performance loss with prevalent low-rank methods. This approach offers a strong alternative to traditional training techniques, paving the way for more efficient and scalable neural network training solutions.
SInViG: A Self-Evolving Interactive Visual Agent for Human-Robot Interaction
Feb 20, 2024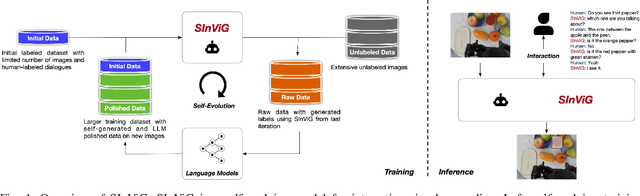

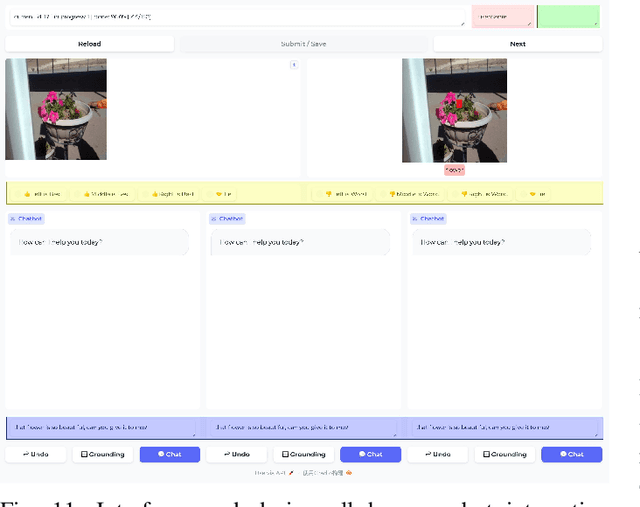

Linguistic ambiguity is ubiquitous in our daily lives. Previous works adopted interaction between robots and humans for language disambiguation. Nevertheless, when interactive robots are deployed in daily environments, there are significant challenges for natural human-robot interaction, stemming from complex and unpredictable visual inputs, open-ended interaction, and diverse user demands. In this paper, we present SInViG, which is a self-evolving interactive visual agent for human-robot interaction based on natural languages, aiming to resolve language ambiguity, if any, through multi-turn visual-language dialogues. It continuously and automatically learns from unlabeled images and large language models, without human intervention, to be more robust against visual and linguistic complexity. Benefiting from self-evolving, it sets new state-of-the-art on several interactive visual grounding benchmarks. Moreover, our human-robot interaction experiments show that the evolved models consistently acquire more and more preferences from human users. Besides, we also deployed our model on a Franka robot for interactive manipulation tasks. Results demonstrate that our model can follow diverse user instructions and interact naturally with humans in natural language, despite the complexity and disturbance of the environment.
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Dec 21, 2023



Generative pre-trained models have demonstrated remarkable effectiveness in language and vision domains by learning useful representations. In this paper, we extend the scope of this effectiveness by showing that visual robot manipulation can significantly benefit from large-scale video generative pre-training. We introduce GR-1, a straightforward GPT-style model designed for multi-task language-conditioned visual robot manipulation. GR-1 takes as inputs a language instruction, a sequence of observation images, and a sequence of robot states. It predicts robot actions as well as future images in an end-to-end manner. Thanks to a flexible design, GR-1 can be seamlessly finetuned on robot data after pre-trained on a large-scale video dataset. We perform extensive experiments on the challenging CALVIN benchmark and a real robot. On CALVIN benchmark, our method outperforms state-of-the-art baseline methods and improves the success rate from 88.9% to 94.9%. In the setting of zero-shot unseen scene generalization, GR-1 improves the success rate from 53.3% to 85.4%. In real robot experiments, GR-1 also outperforms baseline methods and shows strong potentials in generalization to unseen scenes and objects. We provide inaugural evidence that a unified GPT-style transformer, augmented with large-scale video generative pre-training, exhibits remarkable generalization to multi-task visual robot manipulation. Project page: https://GR1-Manipulation.github.io
Vision-Language Foundation Models as Effective Robot Imitators
Nov 06, 2023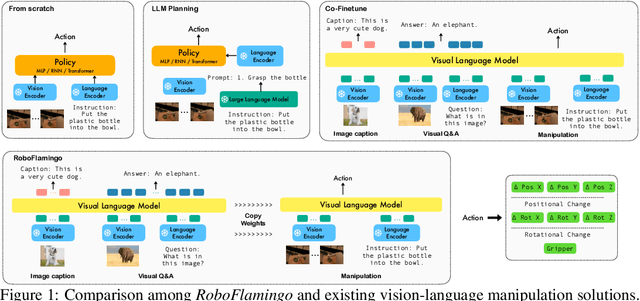
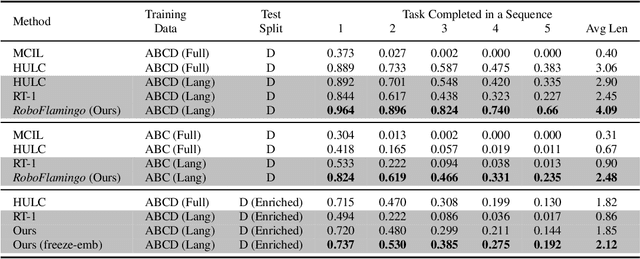
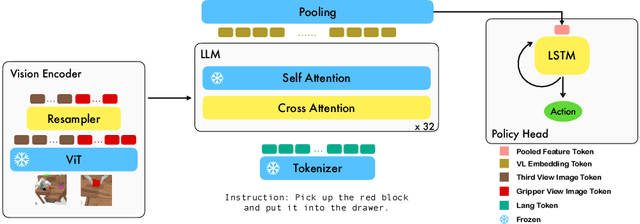
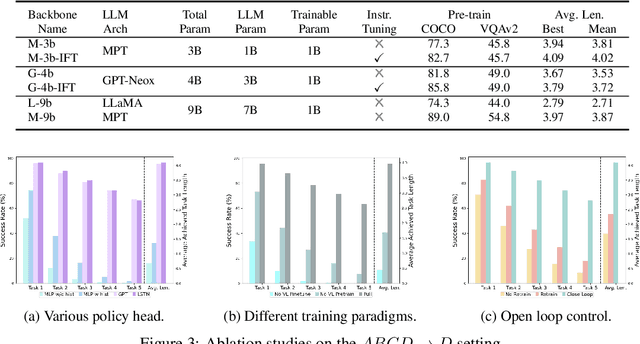
Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
Mixed Neural Voxels for Fast Multi-view Video Synthesis
Dec 01, 2022



Synthesizing high-fidelity videos from real-world multi-view input is challenging because of the complexities of real-world environments and highly dynamic motions. Previous works based on neural radiance fields have demonstrated high-quality reconstructions of dynamic scenes. However, training such models on real-world scenes is time-consuming, usually taking days or weeks. In this paper, we present a novel method named MixVoxels to better represent the dynamic scenes with fast training speed and competitive rendering qualities. The proposed MixVoxels represents the 4D dynamic scenes as a mixture of static and dynamic voxels and processes them with different networks. In this way, the computation of the required modalities for static voxels can be processed by a lightweight model, which essentially reduces the amount of computation, especially for many daily dynamic scenes dominated by the static background. To separate the two kinds of voxels, we propose a novel variation field to estimate the temporal variance of each voxel. For the dynamic voxels, we design an inner-product time query method to efficiently query multiple time steps, which is essential to recover the high-dynamic motions. As a result, with 15 minutes of training for dynamic scenes with inputs of 300-frame videos, MixVoxels achieves better PSNR than previous methods. Codes and trained models are available at https://github.com/fengres/mixvoxels