 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
RePose: A Real-Time 3D Human Pose Estimation and Biomechanical Analysis Framework for Rehabilitation
Jan 02, 2026We propose a real-time 3D human pose estimation and motion analysis method termed RePose for rehabilitation training. It is capable of real-time monitoring and evaluation of patients'motion during rehabilitation, providing immediate feedback and guidance to assist patients in executing rehabilitation exercises correctly. Firstly, we introduce a unified pipeline for end-to-end real-time human pose estimation and motion analysis using RGB video input from multiple cameras which can be applied to the field of rehabilitation training. The pipeline can help to monitor and correct patients'actions, thus aiding them in regaining muscle strength and motor functions. Secondly, we propose a fast tracking method for medical rehabilitation scenarios with multiple-person interference, which requires less than 1ms for tracking for a single frame. Additionally, we modify SmoothNet for real-time posture estimation, effectively reducing pose estimation errors and restoring the patient's true motion state, making it visually smoother. Finally, we use Unity platform for real-time monitoring and evaluation of patients' motion during rehabilitation, and to display the muscle stress conditions to assist patients with their rehabilitation training.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Diffusion priors enhanced velocity model building from time-lag images using a neural operator
Dec 29, 2025Velocity model building serves as a crucial component for achieving high precision subsurface imaging. However, conventional velocity model building methods are often computationally expensive and time consuming. In recent years, with the rapid advancement of deep learning, particularly the success of generative models and neural operators, deep learning based approaches that integrate data and their statistics have attracted increasing attention in addressing the limitations of traditional methods. In this study, we propose a novel framework that combines generative models with neural operators to obtain high resolution velocity models efficiently. Within this workflow, the neural operator functions as a forward mapping operator to rapidly generate time lag reverse time migration (RTM) extended images from the true and migration velocity models. In this framework, the neural operator is acting as a surrogate for modeling followed by migration, which uses the true and migration velocities, respectively. The trained neural operator is then employed, through automatic differentiation, to gradually update the migration velocity placed in the true velocity input channel with high resolution components so that the output of the network matches the time lag images of observed data obtained using the migration velocity. By embedding a generative model, trained on a high-resolution velocity model distribution, which corresponds to the true velocity model distribution used to train the neural operator, as a regularizer, the resulting predictions are cleaner with higher resolution information. Both synthetic and field data experiments demonstrate the effectiveness of the proposed generative neural operator based velocity model building approach.
WMPO: World Model-based Policy Optimization for Vision-Language-Action Models
Nov 12, 2025



Vision-Language-Action (VLA) models have shown strong potential for general-purpose robotic manipulation, but their reliance on expert demonstrations limits their ability to learn from failures and perform self-corrections. Reinforcement learning (RL) addresses these through self-improving interactions with the physical environment, but suffers from high sample complexity on real robots. We introduce World-Model-based Policy Optimization (WMPO), a principled framework for on-policy VLA RL without interacting with the real environment. In contrast to widely used latent world models, WMPO focuses on pixel-based predictions that align the "imagined" trajectories with the VLA features pretrained with web-scale images. Crucially, WMPO enables the policy to perform on-policy GRPO that provides stronger performance than the often-used off-policy methods. Extensive experiments in both simulation and real-robot settings demonstrate that WMPO (i) substantially improves sample efficiency, (ii) achieves stronger overall performance, (iii) exhibits emergent behaviors such as self-correction, and (iv) demonstrates robust generalization and lifelong learning capabilities.
An effective physics-informed neural operator framework for predicting wavefields
Jul 22, 2025Solving the wave equation is fundamental for geophysical applications. However, numerical solutions of the Helmholtz equation face significant computational and memory challenges. Therefore, we introduce a physics-informed convolutional neural operator (PICNO) to solve the Helmholtz equation efficiently. The PICNO takes both the background wavefield corresponding to a homogeneous medium and the velocity model as input function space, generating the scattered wavefield as the output function space. Our workflow integrates PDE constraints directly into the training process, enabling the neural operator to not only fit the available data but also capture the underlying physics governing wave phenomena. PICNO allows for high-resolution reasonably accurate predictions even with limited training samples, and it demonstrates significant improvements over a purely data-driven convolutional neural operator (CNO), particularly in predicting high-frequency wavefields. These features and improvements are important for waveform inversion down the road.
Flow-Based Policy for Online Reinforcement Learning
Jun 15, 2025



We present \textbf{FlowRL}, a novel framework for online reinforcement learning that integrates flow-based policy representation with Wasserstein-2-regularized optimization. We argue that in addition to training signals, enhancing the expressiveness of the policy class is crucial for the performance gains in RL. Flow-based generative models offer such potential, excelling at capturing complex, multimodal action distributions. However, their direct application in online RL is challenging due to a fundamental objective mismatch: standard flow training optimizes for static data imitation, while RL requires value-based policy optimization through a dynamic buffer, leading to difficult optimization landscapes. FlowRL first models policies via a state-dependent velocity field, generating actions through deterministic ODE integration from noise. We derive a constrained policy search objective that jointly maximizes Q through the flow policy while bounding the Wasserstein-2 distance to a behavior-optimal policy implicitly derived from the replay buffer. This formulation effectively aligns the flow optimization with the RL objective, enabling efficient and value-aware policy learning despite the complexity of the policy class. Empirical evaluations on DMControl and Humanoidbench demonstrate that FlowRL achieves competitive performance in online reinforcement learning benchmarks.
Simple Radiology VLLM Test-time Scaling with Thought Graph Traversal
Jun 13, 2025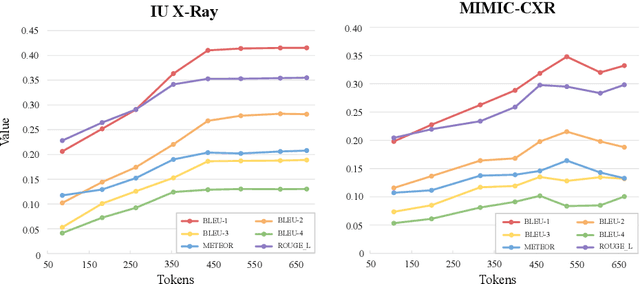
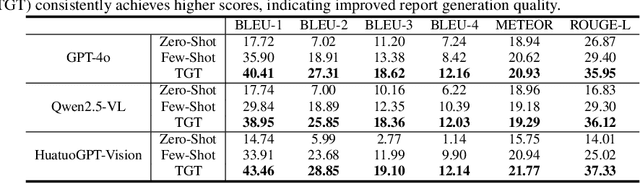
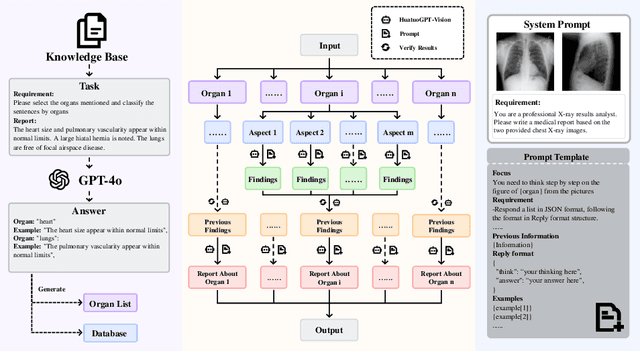
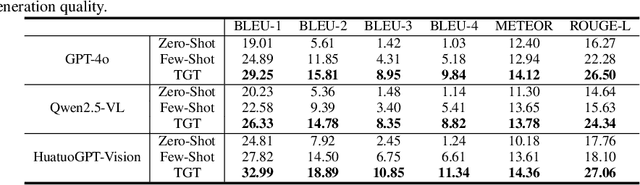
Test-time scaling offers a promising way to improve the reasoning performance of vision-language large models (VLLMs) without additional training. In this paper, we explore a simple but effective approach for applying test-time scaling to radiology report generation. Specifically, we introduce a lightweight Thought Graph Traversal (TGT) framework that guides the model to reason through organ-specific findings in a medically coherent order. This framework integrates structured medical priors into the prompt, enabling deeper and more logical analysis with no changes to the underlying model. To further enhance reasoning depth, we apply a reasoning budget forcing strategy that adjusts the model's inference depth at test time by dynamically extending its generation process. This simple yet powerful combination allows a frozen radiology VLLM to self-correct and generate more accurate, consistent chest X-ray reports. Our method outperforms baseline prompting approaches on standard benchmarks, and also reveals dataset biases through traceable reasoning paths. Code and prompts are open-sourced for reproducibility at https://github.com/glerium/Thought-Graph-Traversal.
Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
Jun 11, 2025We present Chain-of-Action (CoA), a novel visuo-motor policy paradigm built upon Trajectory Autoregressive Modeling. Unlike conventional approaches that predict next step action(s) forward, CoA generates an entire trajectory by explicit backward reasoning with task-specific goals through an action-level Chain-of-Thought (CoT) process. This process is unified within a single autoregressive structure: (1) the first token corresponds to a stable keyframe action that encodes the task-specific goals; and (2) subsequent action tokens are generated autoregressively, conditioned on the initial keyframe and previously predicted actions. This backward action reasoning enforces a global-to-local structure, allowing each local action to be tightly constrained by the final goal. To further realize the action reasoning structure, CoA incorporates four complementary designs: continuous action token representation; dynamic stopping for variable-length trajectory generation; reverse temporal ensemble; and multi-token prediction to balance action chunk modeling with global structure. As a result, CoA gives strong spatial generalization capabilities while preserving the flexibility and simplicity of a visuo-motor policy. Empirically, we observe CoA achieves the state-of-the-art performance across 60 RLBench tasks and 8 real-world manipulation tasks.
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/