 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2GQL-Bench: A Text to Graph Query Language Benchmark [Experiment, Analysis & Benchmark]
Feb 12, 2026Graph models are fundamental to data analysis in domains rich with complex relationships. Text-to-Graph-Query-Language (Text-to-GQL) systems act as a translator, converting natural language into executable graph queries. This capability allows Large Language Models (LLMs) to directly analyze and manipulate graph data, posi-tioning them as powerful agent infrastructures for Graph Database Management System (GDBMS). Despite recent progress, existing datasets are often limited in domain coverage, supported graph query languages, or evaluation scope. The advancement of Text-to-GQL systems is hindered by the lack of high-quality benchmark datasets and evaluation methods to systematically compare model capabilities across different graph query languages and domains. In this work, we present Text2GQL-Bench, a unified Text-to-GQL benchmark designed to address these limitations. Text2GQL-Bench couples a multi-GQL dataset that has 178,184 (Question, Query) pairs spanning 13 domains, with a scalable construction framework that generates datasets in different domains, question abstraction levels, and GQLs with heterogeneous resources. To support compre-hensive assessment, we introduce an evaluation method that goes beyond a single end-to-end metric by jointly reporting grammatical validity, similarity, semantic alignment, and execution accuracy. Our evaluation uncovers a stark dialect gap in ISO-GQL generation: even strong LLMs achieve only at most 4% execution accuracy (EX) in zero-shot settings, though a fixed 3-shot prompt raises accuracy to around 50%, the grammatical validity remains lower than 70%. Moreover, a fine-tuned 8B open-weight model reaches 45.1% EX, and 90.8% grammatical validity, demonstrating that most of the performance jump is unlocked by exposure to sufficient ISO-GQL examples.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024

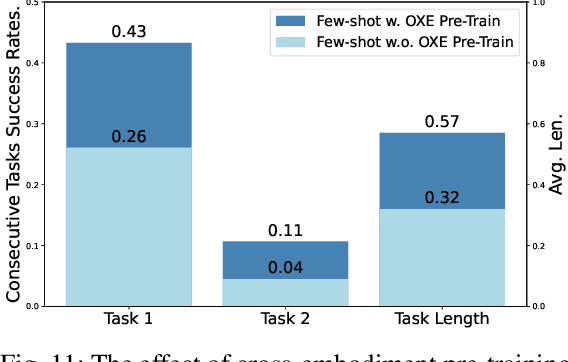

Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
RH20T: A Robotic Dataset for Learning Diverse Skills in One-Shot
Jul 02, 2023



A key challenge in robotic manipulation in open domains is how to acquire diverse and generalizable skills for robots. Recent research in one-shot imitation learning has shown promise in transferring trained policies to new tasks based on demonstrations. This feature is attractive for enabling robots to acquire new skills and improving task and motion planning. However, due to limitations in the training dataset, the current focus of the community has mainly been on simple cases, such as push or pick-place tasks, relying solely on visual guidance. In reality, there are many complex skills, some of which may even require both visual and tactile perception to solve. This paper aims to unlock the potential for an agent to generalize to hundreds of real-world skills with multi-modal perception. To achieve this, we have collected a dataset comprising over 110,000 \emph{contact-rich} robot manipulation sequences across diverse skills, contexts, robots, and camera viewpoints, all collected \emph{in the real world}. Each sequence in the dataset includes visual, force, audio, and action information, along with a corresponding human demonstration video. We have invested significant efforts in calibrating all the sensors and ensuring a high-quality dataset. The dataset is made publicly available at rh20t.github.io
AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains
Dec 16, 2022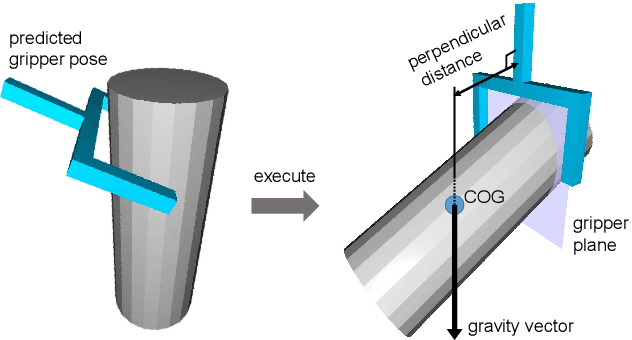
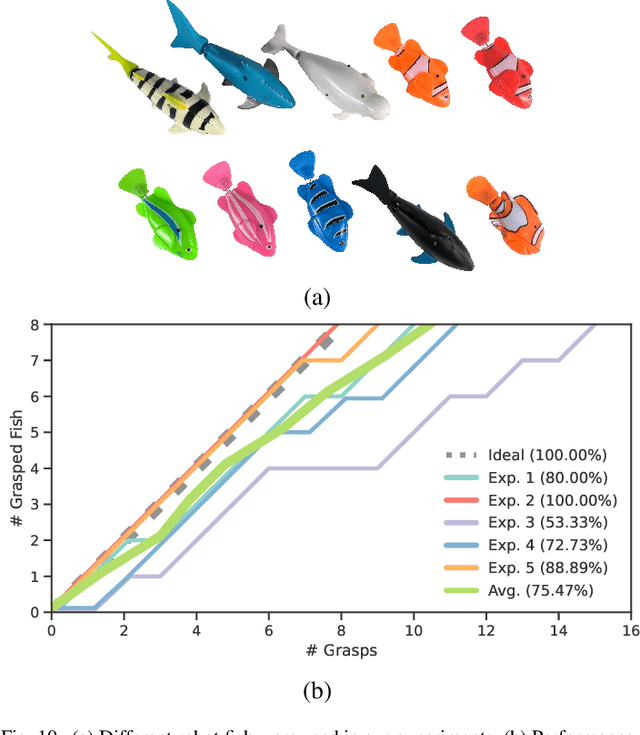

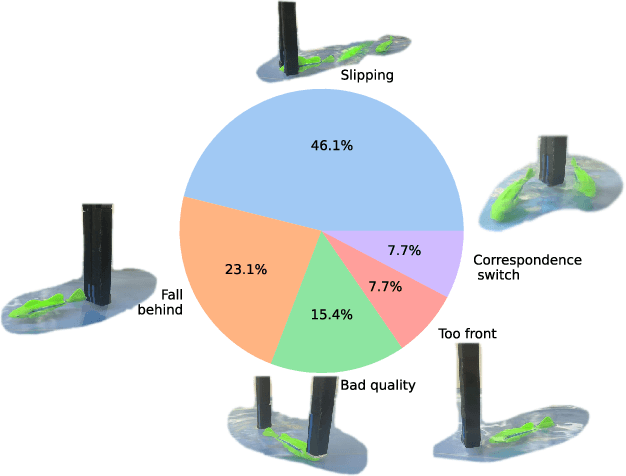
As the basis for prehensile manipulation, it is vital to enable robots to grasp as robustly as humans. In daily manipulation, our grasping system is prompt, accurate, flexible and continuous across spatial and temporal domains. Few existing methods cover all these properties for robot grasping. In this paper, we propose a new methodology for grasp perception to enable robots these abilities. Specifically, we develop a dense supervision strategy with real perception and analytic labels in the spatial-temporal domain. Additional awareness of objects' center-of-mass is incorporated into the learning process to help improve grasping stability. Utilization of grasp correspondence across observations enables dynamic grasp tracking. Our model, AnyGrasp, can generate accurate, full-DoF, dense and temporally-smooth grasp poses efficiently, and works robustly against large depth sensing noise. Embedded with AnyGrasp, we achieve a 93.3% success rate when clearing bins with over 300 unseen objects, which is comparable with human subjects under controlled conditions. Over 900 MPPH is reported on a single-arm system. For dynamic grasping, we demonstrate catching swimming robot fish in the water.