 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Camera View Scaling for Data-Efficient Robot Imitation Learning
Apr 01, 2026The generalization ability of imitation learning policies for robotic manipulation is fundamentally constrained by the diversity of expert demonstrations, while collecting demonstrations across varied environments is costly and difficult in practice. In this paper, we propose a practical framework that exploits inherent scene diversity without additional human effort by scaling camera views during demonstration collection. Instead of acquiring more trajectories, multiple synchronized camera perspectives are used to generate pseudo-demonstrations from each expert trajectory, which enriches the training distribution and improves viewpoint invariance in visual representations. We analyze how different action spaces interact with view scaling and show that camera-space representations further enhance diversity. In addition, we introduce a multiview action aggregation method that allows single-view policies to benefit from multiple cameras during deployment. Extensive experiments in simulation and real-world manipulation tasks demonstrate significant gains in data efficiency and generalization compared to single-view baselines. Our results suggest that scaling camera views provides a practical and scalable solution for imitation learning, which requires minimal additional hardware setup and integrates seamlessly with existing imitation learning algorithms. The website of our project is https://yichen928.github.io/robot_multiview.
ExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
DEXOP: A Device for Robotic Transfer of Dexterous Human Manipulation
Sep 04, 2025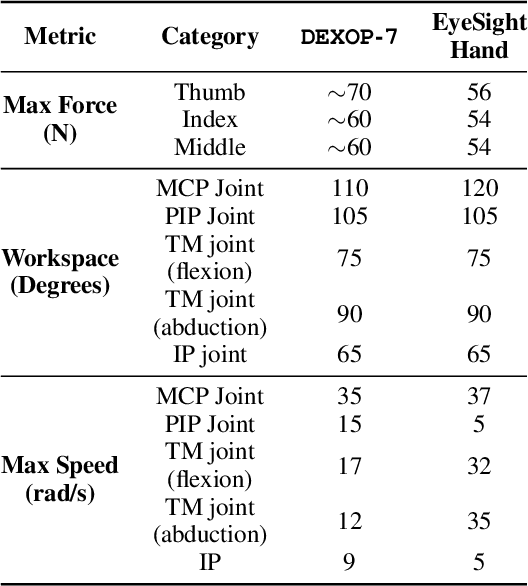
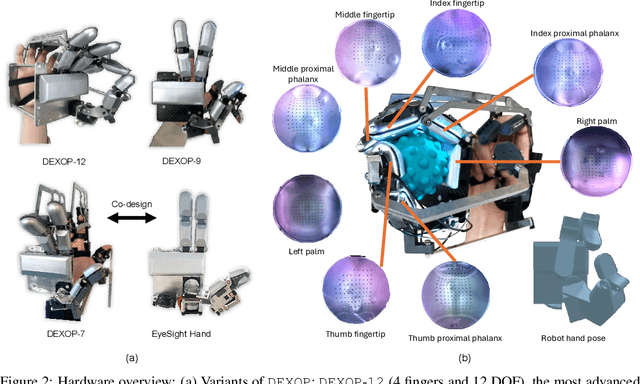

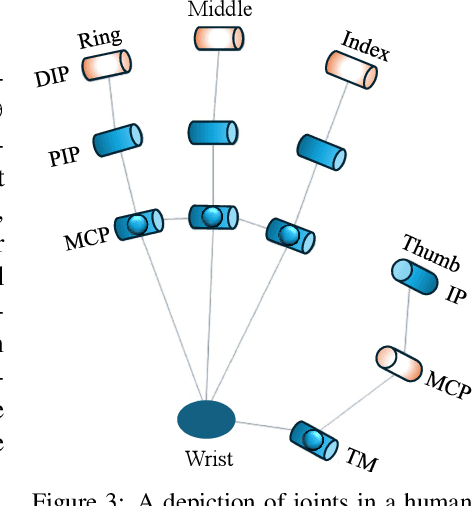
We introduce perioperation, a paradigm for robotic data collection that sensorizes and records human manipulation while maximizing the transferability of the data to real robots. We implement this paradigm in DEXOP, a passive hand exoskeleton designed to maximize human ability to collect rich sensory (vision + tactile) data for diverse dexterous manipulation tasks in natural environments. DEXOP mechanically connects human fingers to robot fingers, providing users with direct contact feedback (via proprioception) and mirrors the human hand pose to the passive robot hand to maximize the transfer of demonstrated skills to the robot. The force feedback and pose mirroring make task demonstrations more natural for humans compared to teleoperation, increasing both speed and accuracy. We evaluate DEXOP across a range of dexterous, contact-rich tasks, demonstrating its ability to collect high-quality demonstration data at scale. Policies learned with DEXOP data significantly improve task performance per unit time of data collection compared to teleoperation, making DEXOP a powerful tool for advancing robot dexterity. Our project page is at https://dex-op.github.io.
VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers
Jul 01, 2025In this paper, we introduce an innovative vector quantization based action tokenizer built upon the largest-scale action trajectory dataset to date, leveraging over 100 times more data than previous approaches. This extensive dataset enables our tokenizer to capture rich spatiotemporal dynamics, resulting in a model that not only accelerates inference but also generates smoother and more coherent action outputs. Once trained, the tokenizer can be seamlessly adapted to a wide range of downstream tasks in a zero-shot manner, from short-horizon reactive behaviors to long-horizon planning. A key finding of our work is that the domain gap between synthetic and real action trajectories is marginal, allowing us to effectively utilize a vast amount of synthetic data during training without compromising real-world performance. To validate our approach, we conducted extensive experiments in both simulated environments and on real robotic platforms. The results demonstrate that as the volume of synthetic trajectory data increases, the performance of our tokenizer on downstream tasks improves significantly-most notably, achieving up to a 30% higher success rate on two real-world tasks in long-horizon scenarios. These findings highlight the potential of our action tokenizer as a robust and scalable solution for real-time embodied intelligence systems, paving the way for more efficient and reliable robotic control in diverse application domains.Project website: https://xiaoxiao0406.github.io/vqvla.github.io
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
AnyDexGrasp: General Dexterous Grasping for Different Hands with Human-level Learning Efficiency
Feb 23, 2025We introduce an efficient approach for learning dexterous grasping with minimal data, advancing robotic manipulation capabilities across different robotic hands. Unlike traditional methods that require millions of grasp labels for each robotic hand, our method achieves high performance with human-level learning efficiency: only hundreds of grasp attempts on 40 training objects. The approach separates the grasping process into two stages: first, a universal model maps scene geometry to intermediate contact-centric grasp representations, independent of specific robotic hands. Next, a unique grasp decision model is trained for each robotic hand through real-world trial and error, translating these representations into final grasp poses. Our results show a grasp success rate of 75-95\% across three different robotic hands in real-world cluttered environments with over 150 novel objects, improving to 80-98\% with increased training objects. This adaptable method demonstrates promising applications for humanoid robots, prosthetics, and other domains requiring robust, versatile robotic manipulation.
FoAR: Force-Aware Reactive Policy for Contact-Rich Robotic Manipulation
Nov 24, 2024Contact-rich tasks present significant challenges for robotic manipulation policies due to the complex dynamics of contact and the need for precise control. Vision-based policies often struggle with the skill required for such tasks, as they typically lack critical contact feedback modalities like force/torque information. To address this issue, we propose FoAR, a force-aware reactive policy that combines high-frequency force/torque sensing with visual inputs to enhance the performance in contact-rich manipulation. Built upon the RISE policy, FoAR incorporates a multimodal feature fusion mechanism guided by a future contact predictor, enabling dynamic adjustment of force/torque data usage between non-contact and contact phases. Its reactive control strategy also allows FoAR to accomplish contact-rich tasks accurately through simple position control. Experimental results demonstrate that FoAR significantly outperforms all baselines across various challenging contact-rich tasks while maintaining robust performance under unexpected dynamic disturbances. Project website: https://tonyfang.net/FoAR/
CAGE: Causal Attention Enables Data-Efficient Generalizable Robotic Manipulation
Oct 19, 2024Generalization in robotic manipulation remains a critical challenge, particularly when scaling to new environments with limited demonstrations. This paper introduces CAGE, a novel robotic manipulation policy designed to overcome these generalization barriers by integrating a causal attention mechanism. CAGE utilizes the powerful feature extraction capabilities of the vision foundation model DINOv2, combined with LoRA fine-tuning for robust environment understanding. The policy further employs a causal Perceiver for effective token compression and a diffusion-based action prediction head with attention mechanisms to enhance task-specific fine-grained conditioning. With as few as 50 demonstrations from a single training environment, CAGE achieves robust generalization across diverse visual changes in objects, backgrounds, and viewpoints. Extensive experiments validate that CAGE significantly outperforms existing state-of-the-art RGB/RGB-D approaches in various manipulation tasks, especially under large distribution shifts. In similar environments, CAGE offers an average of 42% increase in task completion rate. While all baselines fail to execute the task in unseen environments, CAGE manages to obtain a 43% completion rate and a 51% success rate in average, making a huge step towards practical deployment of robots in real-world settings. Project website: cage-policy.github.io.
Towards Effective Utilization of Mixed-Quality Demonstrations in Robotic Manipulation via Segment-Level Selection and Optimization
Sep 30, 2024Data is crucial for robotic manipulation, as it underpins the development of robotic systems for complex tasks. While high-quality, diverse datasets enhance the performance and adaptability of robotic manipulation policies, collecting extensive expert-level data is resource-intensive. Consequently, many current datasets suffer from quality inconsistencies due to operator variability, highlighting the need for methods to utilize mixed-quality data effectively. To mitigate these issues, we propose "Select Segments to Imitate" (S2I), a framework that selects and optimizes mixed-quality demonstration data at the segment level, while ensuring plug-and-play compatibility with existing robotic manipulation policies. The framework has three components: demonstration segmentation dividing origin data into meaningful segments, segment selection using contrastive learning to find high-quality segments, and trajectory optimization to refine suboptimal segments for better policy learning. We evaluate S2I through comprehensive experiments in simulation and real-world environments across six tasks, demonstrating that with only 3 expert demonstrations for reference, S2I can improve the performance of various downstream policies when trained with mixed-quality demonstrations. Project website: https://tonyfang.net/s2i/.