 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIME: Enhancing Policy Self-Improvement with Modal-level Exploration
May 02, 2025Self-improvement requires robotic systems to initially learn from human-provided data and then gradually enhance their capabilities through interaction with the environment. This is similar to how humans improve their skills through continuous practice. However, achieving effective self-improvement is challenging, primarily because robots tend to repeat their existing abilities during interactions, often failing to generate new, valuable data for learning. In this paper, we identify the key to successful self-improvement: modal-level exploration and data selection. By incorporating a modal-level exploration mechanism during policy execution, the robot can produce more diverse and multi-modal interactions. At the same time, we select the most valuable trials and high-quality segments from these interactions for learning. We successfully demonstrate effective robot self-improvement on both simulation benchmarks and real-world experiments. The capability for self-improvement will enable us to develop more robust and high-success-rate robotic control strategies at a lower cost. Our code and experiment scripts are available at https://ericjin2002.github.io/SIME/
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
AnyDexGrasp: General Dexterous Grasping for Different Hands with Human-level Learning Efficiency
Feb 23, 2025We introduce an efficient approach for learning dexterous grasping with minimal data, advancing robotic manipulation capabilities across different robotic hands. Unlike traditional methods that require millions of grasp labels for each robotic hand, our method achieves high performance with human-level learning efficiency: only hundreds of grasp attempts on 40 training objects. The approach separates the grasping process into two stages: first, a universal model maps scene geometry to intermediate contact-centric grasp representations, independent of specific robotic hands. Next, a unique grasp decision model is trained for each robotic hand through real-world trial and error, translating these representations into final grasp poses. Our results show a grasp success rate of 75-95\% across three different robotic hands in real-world cluttered environments with over 150 novel objects, improving to 80-98\% with increased training objects. This adaptable method demonstrates promising applications for humanoid robots, prosthetics, and other domains requiring robust, versatile robotic manipulation.
FoAR: Force-Aware Reactive Policy for Contact-Rich Robotic Manipulation
Nov 24, 2024Contact-rich tasks present significant challenges for robotic manipulation policies due to the complex dynamics of contact and the need for precise control. Vision-based policies often struggle with the skill required for such tasks, as they typically lack critical contact feedback modalities like force/torque information. To address this issue, we propose FoAR, a force-aware reactive policy that combines high-frequency force/torque sensing with visual inputs to enhance the performance in contact-rich manipulation. Built upon the RISE policy, FoAR incorporates a multimodal feature fusion mechanism guided by a future contact predictor, enabling dynamic adjustment of force/torque data usage between non-contact and contact phases. Its reactive control strategy also allows FoAR to accomplish contact-rich tasks accurately through simple position control. Experimental results demonstrate that FoAR significantly outperforms all baselines across various challenging contact-rich tasks while maintaining robust performance under unexpected dynamic disturbances. Project website: https://tonyfang.net/FoAR/
Motion Before Action: Diffusing Object Motion as Manipulation Condition
Nov 14, 2024



Inferring object motion representations from observations enhances the performance of robotic manipulation tasks. This paper introduces a new paradigm for robot imitation learning that generates action sequences by reasoning about object motion from visual observations. We propose MBA (Motion Before Action), a novel module that employs two cascaded diffusion processes for object motion generation and robot action generation under object motion guidance. MBA first predicts the future pose sequence of the object based on observations, then uses this sequence as a condition to guide robot action generation. Designed as a plug-and-play component, MBA can be flexibly integrated into existing robotic manipulation policies with diffusion action heads. Extensive experiments in both simulated and real-world environments demonstrate that our approach substantially improves the performance of existing policies across a wide range of manipulation tasks.
CAGE: Causal Attention Enables Data-Efficient Generalizable Robotic Manipulation
Oct 19, 2024Generalization in robotic manipulation remains a critical challenge, particularly when scaling to new environments with limited demonstrations. This paper introduces CAGE, a novel robotic manipulation policy designed to overcome these generalization barriers by integrating a causal attention mechanism. CAGE utilizes the powerful feature extraction capabilities of the vision foundation model DINOv2, combined with LoRA fine-tuning for robust environment understanding. The policy further employs a causal Perceiver for effective token compression and a diffusion-based action prediction head with attention mechanisms to enhance task-specific fine-grained conditioning. With as few as 50 demonstrations from a single training environment, CAGE achieves robust generalization across diverse visual changes in objects, backgrounds, and viewpoints. Extensive experiments validate that CAGE significantly outperforms existing state-of-the-art RGB/RGB-D approaches in various manipulation tasks, especially under large distribution shifts. In similar environments, CAGE offers an average of 42% increase in task completion rate. While all baselines fail to execute the task in unseen environments, CAGE manages to obtain a 43% completion rate and a 51% success rate in average, making a huge step towards practical deployment of robots in real-world settings. Project website: cage-policy.github.io.
Towards Effective Utilization of Mixed-Quality Demonstrations in Robotic Manipulation via Segment-Level Selection and Optimization
Sep 30, 2024Data is crucial for robotic manipulation, as it underpins the development of robotic systems for complex tasks. While high-quality, diverse datasets enhance the performance and adaptability of robotic manipulation policies, collecting extensive expert-level data is resource-intensive. Consequently, many current datasets suffer from quality inconsistencies due to operator variability, highlighting the need for methods to utilize mixed-quality data effectively. To mitigate these issues, we propose "Select Segments to Imitate" (S2I), a framework that selects and optimizes mixed-quality demonstration data at the segment level, while ensuring plug-and-play compatibility with existing robotic manipulation policies. The framework has three components: demonstration segmentation dividing origin data into meaningful segments, segment selection using contrastive learning to find high-quality segments, and trajectory optimization to refine suboptimal segments for better policy learning. We evaluate S2I through comprehensive experiments in simulation and real-world environments across six tasks, demonstrating that with only 3 expert demonstrations for reference, S2I can improve the performance of various downstream policies when trained with mixed-quality demonstrations. Project website: https://tonyfang.net/s2i/.
Graspness Discovery in Clutters for Fast and Accurate Grasp Detection
Jun 17, 2024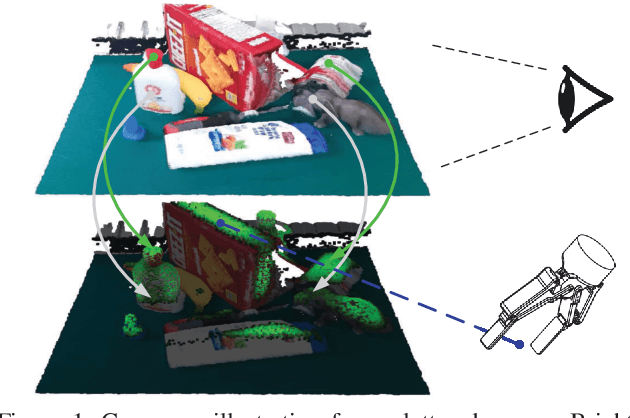

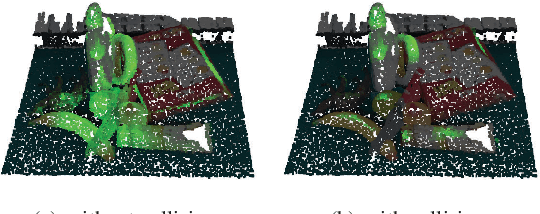
Efficient and robust grasp pose detection is vital for robotic manipulation. For general 6 DoF grasping, conventional methods treat all points in a scene equally and usually adopt uniform sampling to select grasp candidates. However, we discover that ignoring where to grasp greatly harms the speed and accuracy of current grasp pose detection methods. In this paper, we propose "graspness", a quality based on geometry cues that distinguishes graspable areas in cluttered scenes. A look-ahead searching method is proposed for measuring the graspness and statistical results justify the rationality of our method. To quickly detect graspness in practice, we develop a neural network named cascaded graspness model to approximate the searching process. Extensive experiments verify the stability, generality and effectiveness of our graspness model, allowing it to be used as a plug-and-play module for different methods. A large improvement in accuracy is witnessed for various previous methods after equipping our graspness model. Moreover, we develop GSNet, an end-to-end network that incorporates our graspness model for early filtering of low-quality predictions. Experiments on a large-scale benchmark, GraspNet-1Billion, show that our method outperforms previous arts by a large margin (30+ AP) and achieves a high inference speed. The library of GSNet has been integrated into AnyGrasp, which is at https://github.com/graspnet/anygrasp_sdk.
RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective
Apr 18, 2024

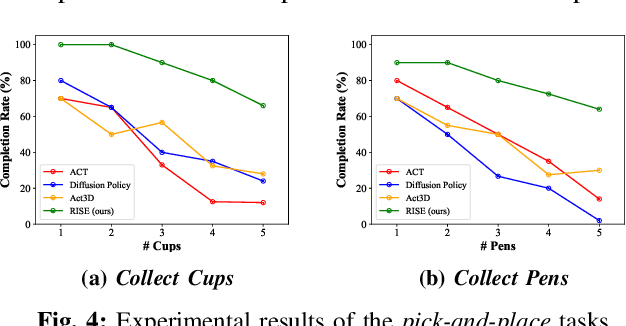

Precise robot manipulations require rich spatial information in imitation learning. Image-based policies model object positions from fixed cameras, which are sensitive to camera view changes. Policies utilizing 3D point clouds usually predict keyframes rather than continuous actions, posing difficulty in dynamic and contact-rich scenarios. To utilize 3D perception efficiently, we present RISE, an end-to-end baseline for real-world imitation learning, which predicts continuous actions directly from single-view point clouds. It compresses the point cloud to tokens with a sparse 3D encoder. After adding sparse positional encoding, the tokens are featurized using a transformer. Finally, the features are decoded into robot actions by a diffusion head. Trained with 50 demonstrations for each real-world task, RISE surpasses currently representative 2D and 3D policies by a large margin, showcasing significant advantages in both accuracy and efficiency. Experiments also demonstrate that RISE is more general and robust to environmental change compared with previous baselines. Project website: rise-policy.github.io.