 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspness Discovery in Clutters for Fast and Accurate Grasp Detection
Jun 17, 2024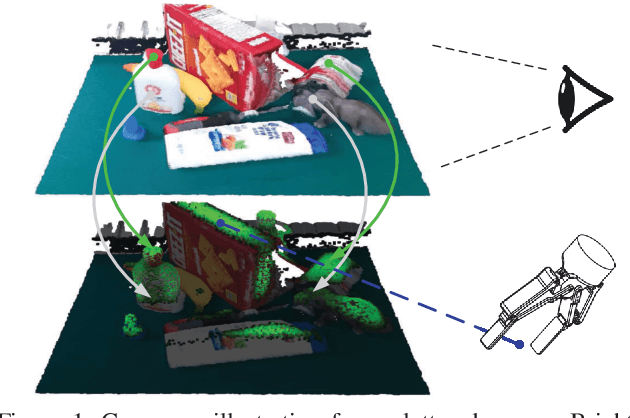

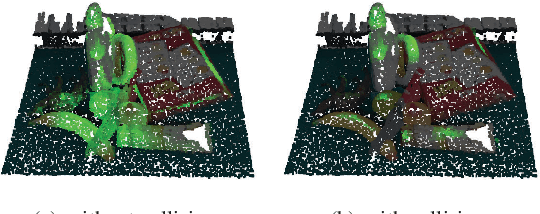
Efficient and robust grasp pose detection is vital for robotic manipulation. For general 6 DoF grasping, conventional methods treat all points in a scene equally and usually adopt uniform sampling to select grasp candidates. However, we discover that ignoring where to grasp greatly harms the speed and accuracy of current grasp pose detection methods. In this paper, we propose "graspness", a quality based on geometry cues that distinguishes graspable areas in cluttered scenes. A look-ahead searching method is proposed for measuring the graspness and statistical results justify the rationality of our method. To quickly detect graspness in practice, we develop a neural network named cascaded graspness model to approximate the searching process. Extensive experiments verify the stability, generality and effectiveness of our graspness model, allowing it to be used as a plug-and-play module for different methods. A large improvement in accuracy is witnessed for various previous methods after equipping our graspness model. Moreover, we develop GSNet, an end-to-end network that incorporates our graspness model for early filtering of low-quality predictions. Experiments on a large-scale benchmark, GraspNet-1Billion, show that our method outperforms previous arts by a large margin (30+ AP) and achieves a high inference speed. The library of GSNet has been integrated into AnyGrasp, which is at https://github.com/graspnet/anygrasp_sdk.
AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains
Dec 16, 2022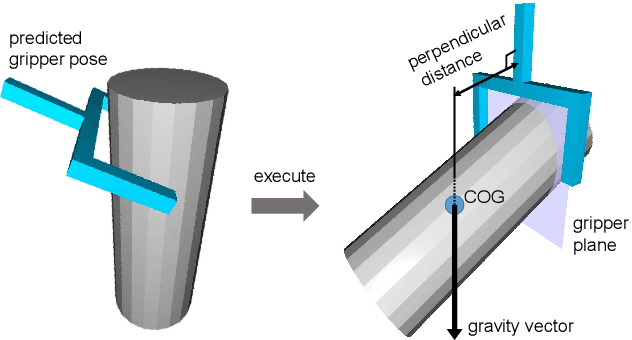
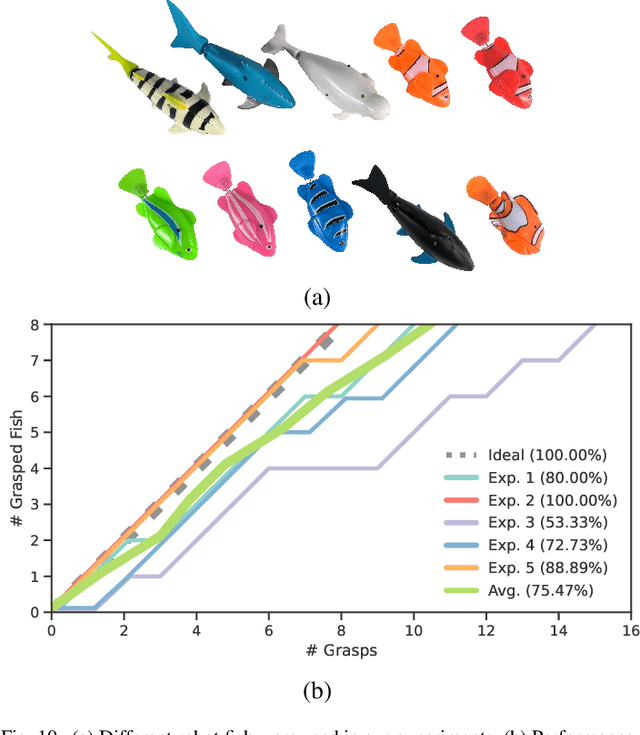

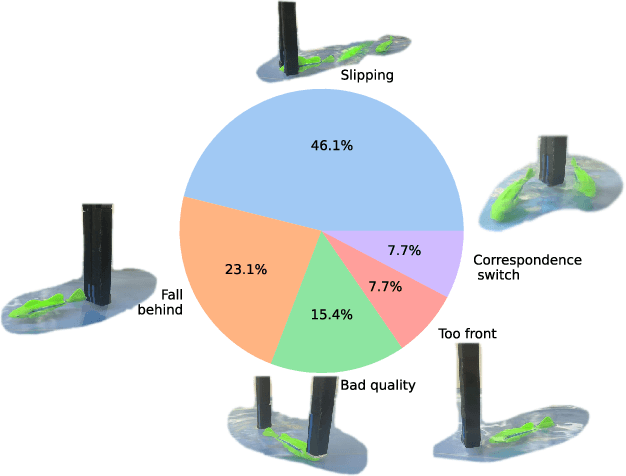
As the basis for prehensile manipulation, it is vital to enable robots to grasp as robustly as humans. In daily manipulation, our grasping system is prompt, accurate, flexible and continuous across spatial and temporal domains. Few existing methods cover all these properties for robot grasping. In this paper, we propose a new methodology for grasp perception to enable robots these abilities. Specifically, we develop a dense supervision strategy with real perception and analytic labels in the spatial-temporal domain. Additional awareness of objects' center-of-mass is incorporated into the learning process to help improve grasping stability. Utilization of grasp correspondence across observations enables dynamic grasp tracking. Our model, AnyGrasp, can generate accurate, full-DoF, dense and temporally-smooth grasp poses efficiently, and works robustly against large depth sensing noise. Embedded with AnyGrasp, we achieve a 93.3% success rate when clearing bins with over 300 unseen objects, which is comparable with human subjects under controlled conditions. Over 900 MPPH is reported on a single-arm system. For dynamic grasping, we demonstrate catching swimming robot fish in the water.
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
Jun 23, 2022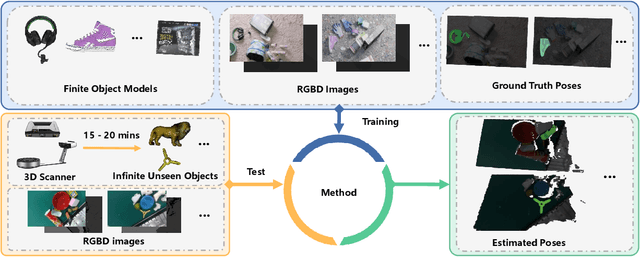
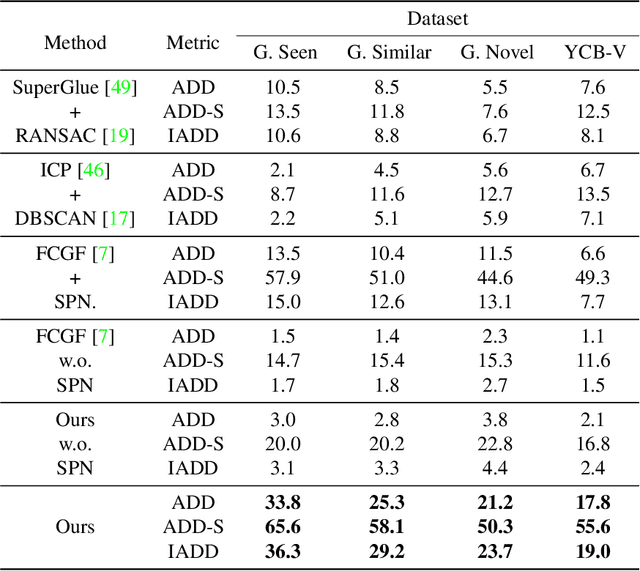

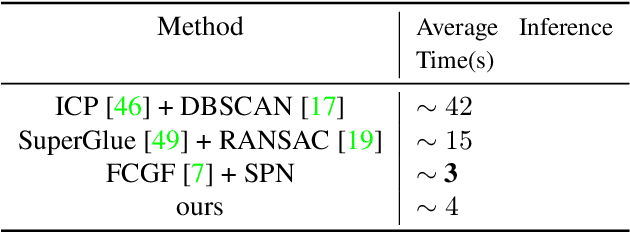
Estimating the 6D pose for unseen objects is in great demand for many real-world applications. However, current state-of-the-art pose estimation methods can only handle objects that are previously trained. In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing. We collect a dataset with both real and synthetic images and up to 48 unseen objects in the test set. In the mean while, we propose a new metric named Infimum ADD (IADD) which is an invariant measurement for objects with different types of pose ambiguity. A two-stage baseline solution for this task is also provided. By training an end-to-end 3D correspondences network, our method finds corresponding points between an unseen object and a partial view RGBD image accurately and efficiently. It then calculates the 6D pose from the correspondences using an algorithm robust to object symmetry. Extensive experiments show that our method outperforms several intuitive baselines and thus verify its effectiveness. All the data, code and models will be made publicly available. Project page: www.graspnet.net/unseen6d
A Real World Dataset for Multi-view 3D Reconstruction
Mar 22, 2022
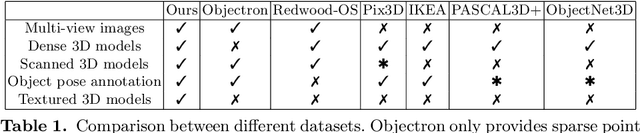
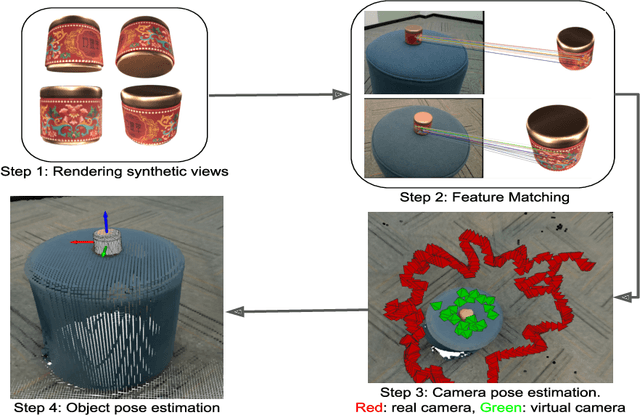
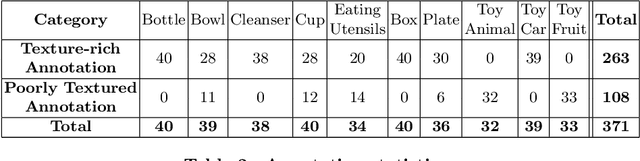
We present a dataset of 371 3D models of everyday tabletop objects along with their 320,000 real world RGB and depth images. Accurate annotations of camera poses and object poses for each image are performed in a semi-automated fashion to facilitate the use of the dataset for myriad 3D applications like shape reconstruction, object pose estimation, shape retrieval etc. We primarily focus on learned multi-view 3D reconstruction due to the lack of appropriate real world benchmark for the task and demonstrate that our dataset can fill that gap. The entire annotated dataset along with the source code for the annotation tools and evaluation baselines will be made publicly available.
RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
Mar 03, 2021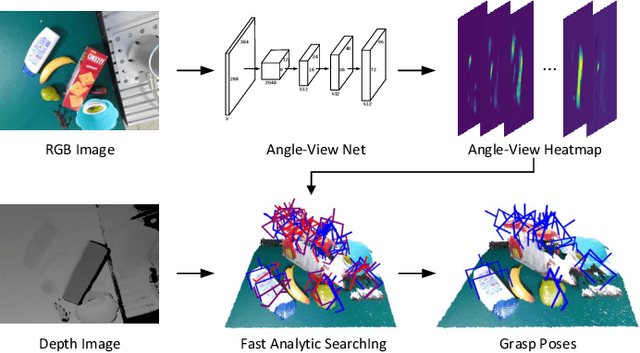
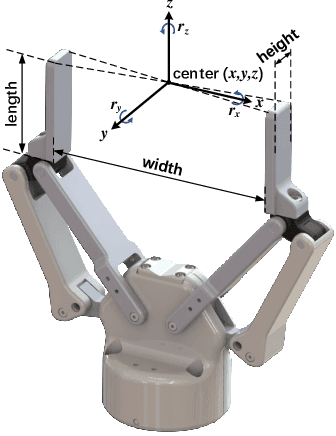
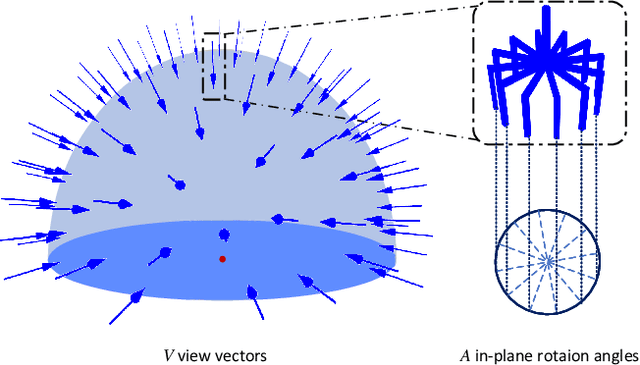
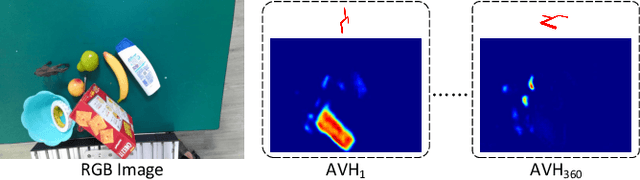
General object grasping is an important yet unsolved problem in the field of robotics. Most of the current methods either generate grasp poses with few DoF that fail to cover most of the success grasps, or only take the unstable depth image or point cloud as input which may lead to poor results in some cases. In this paper, we propose RGBD-Grasp, a pipeline that solves this problem by decoupling 7-DoF grasp detection into two sub-tasks where RGB and depth information are processed separately. In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image. Consequently, a Fast Analytic Searching(FAS) module calculates the opening width and the distance of the gripper to the grasp point. By decoupling the grasp detection problem and introducing the stable RGB modality, our pipeline alleviates the requirement for the high-quality depth image and is robust to depth sensor noise. We achieve state-of-the-art results on GraspNet-1Billion dataset compared with several baselines. Real robot experiments on a UR5 robot with an Intel Realsense camera and a Robotiq two-finger gripper show high success rates for both single object scenes and cluttered scenes. Our code and trained model will be made publicly available.
GraspNet: A Large-Scale Clustered and Densely Annotated Dataset for Object Grasping
Jan 01, 2020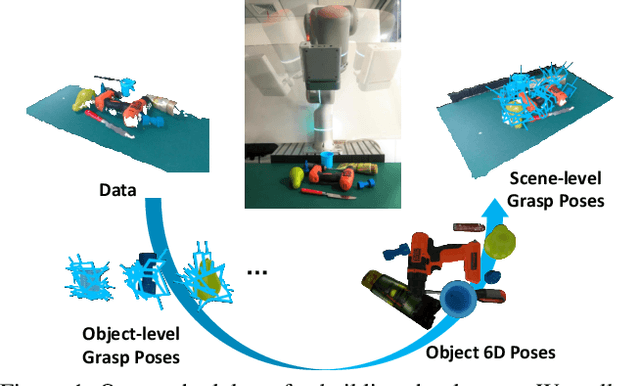
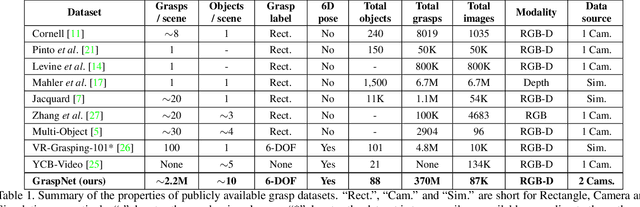

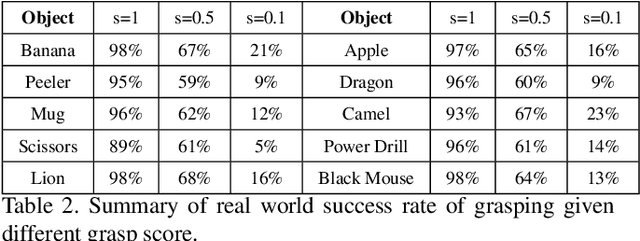
Object grasping is critical for many applications, which is also a challenging computer vision problem. However, for the clustered scene, current researches suffer from the problems of insufficient training data and the lacking of evaluation benchmarks. In this work, we contribute a large-scale grasp pose detection dataset with a unified evaluation system. Our dataset contains 87,040 RGBD images with over 370 million grasp poses. Meanwhile, our evaluation system directly reports whether a grasping is successful or not by analytic computation, which is able to evaluate any kind of grasp poses without exhausted labeling pose ground-truth. We conduct extensive experiments to show that our dataset and evaluation system can align well with real-world experiments. Our dataset, source code and models will be made publicly available.
InstaBoost: Boosting Instance Segmentation via Probability Map Guided Copy-Pasting
Aug 21, 2019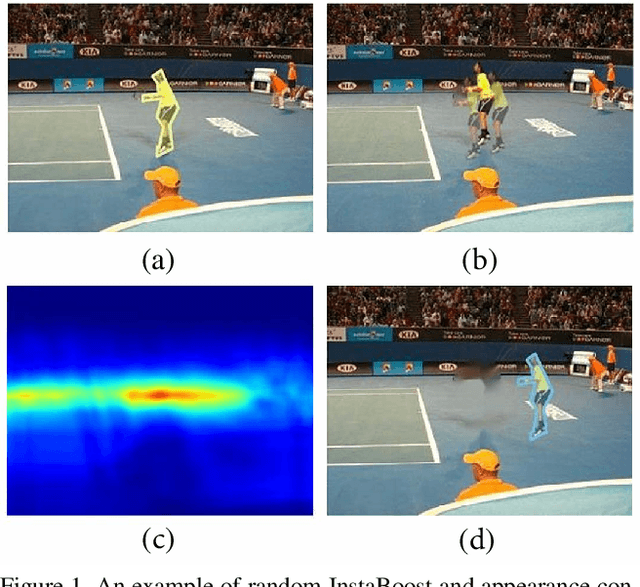
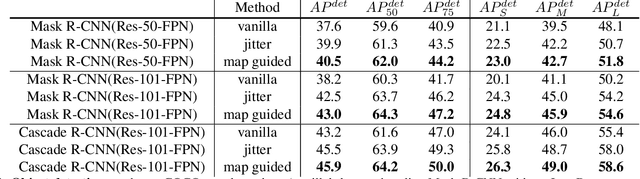

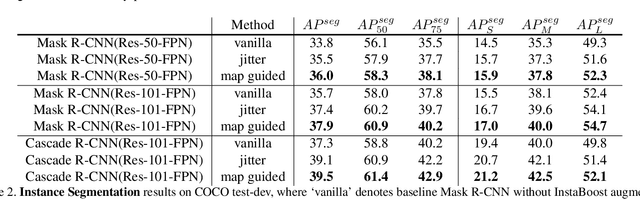
Instance segmentation requires a large number of training samples to achieve satisfactory performance and benefits from proper data augmentation. To enlarge the training set and increase the diversity, previous methods have investigated using data annotation from other domain (e.g. bbox, point) in a weakly supervised mechanism. In this paper, we present a simple, efficient and effective method to augment the training set using the existing instance mask annotations. Exploiting the pixel redundancy of the background, we are able to improve the performance of Mask R-CNN for 1.7 mAP on COCO dataset and 3.3 mAP on Pascal VOC dataset by simply introducing random jittering to objects. Furthermore, we propose a location probability map based approach to explore the feasible locations that objects can be placed based on local appearance similarity. With the guidance of such map, we boost the performance of R101-Mask R-CNN on instance segmentation from 35.7 mAP to 37.9 mAP without modifying the backbone or network structure. Our method is simple to implement and does not increase the computational complexity. It can be integrated into the training pipeline of any instance segmentation model without affecting the training and inference efficiency. Our code and models have been released at https://github.com/GothicAi/InstaBoost