Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real World Dataset for Multi-view 3D Reconstruction
Paper and Code
Mar 22, 2022
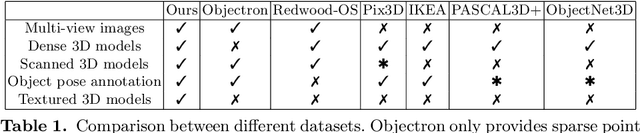
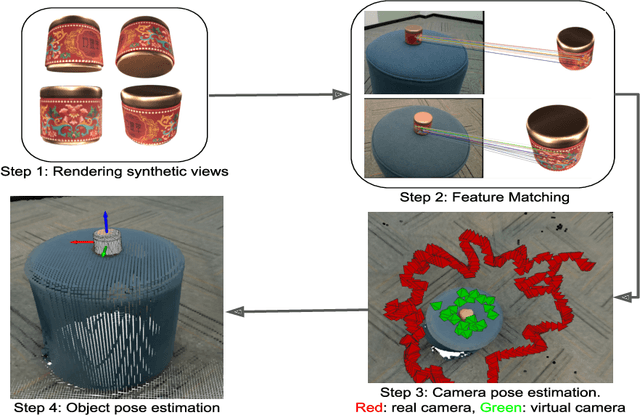
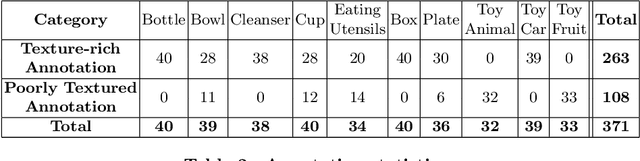
We present a dataset of 371 3D models of everyday tabletop objects along with their 320,000 real world RGB and depth images. Accurate annotations of camera poses and object poses for each image are performed in a semi-automated fashion to facilitate the use of the dataset for myriad 3D applications like shape reconstruction, object pose estimation, shape retrieval etc. We primarily focus on learned multi-view 3D reconstruction due to the lack of appropriate real world benchmark for the task and demonstrate that our dataset can fill that gap. The entire annotated dataset along with the source code for the annotation tools and evaluation baselines will be made publicly available.
View paper on