 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitch: Learning Agile Skills Switching for Humanoid Robots
Apr 16, 2026Recent advancements in whole-body control through deep reinforcement learning have enabled humanoid robots to achieve remarkable progress in real-world chal lenging locomotion skills. However, existing approaches often struggle with flexible transitions between distinct skills, cre ating safety concerns and practical limitations. To address this challenge, we introduce a hierarchical multi-skill system, Switch, enabling seamless skill transitions at any moment. Our approach comprises three key components: (1) a Skill Graph (SG) that establishes potential cross-skill transitions based on kinematic similarity within multi-skill motion data, (2) a whole-body tracking policy trained on this skill graph through deep reinforcement learning, and (3) an online skill scheduler to drive the tracking policy for robust skill execution and smooth transitions. For skill switching or significant tracking deviations, the scheduler performs online graph search to find the optimal feasible path, which ensures efficient, stable, and real-time execution of diverse locomotion skills. Comprehensive experiments demonstrate that Switch empowers humanoid to execute agile skill transitions with high success rates while maintaining strong motion imitation performance.
Symbiotic-MoE: Unlocking the Synergy between Generation and Understanding
Apr 09, 2026Empowering Large Multimodal Models (LMMs) with image generation often leads to catastrophic forgetting in understanding tasks due to severe gradient conflicts. While existing paradigms like Mixture-of-Transformers (MoT) mitigate this conflict through structural isolation, they fundamentally sever cross-modal synergy and suffer from capacity fragmentation. In this work, we present Symbiotic-MoE, a unified pre-training framework that resolves task interference within a native multimodal Mixture-of-Experts (MoE) Transformers architecture with zero-parameter overhead. We first identify that standard MoE tuning leads to routing collapse, where generative gradients dominate expert utilization. To address this, we introduce Modality-Aware Expert Disentanglement, which partitions experts into task-specific groups while utilizing shared experts as a multimodal semantic bridge. Crucially, this design allows shared experts to absorb fine-grained visual semantics from generative tasks to enrich textual representations. To optimize this, we propose a Progressive Training Strategy featuring differential learning rates and early-stage gradient shielding. This mechanism not only shields pre-trained knowledge from early volatility but eventually transforms generative signals into constructive feedback for understanding. Extensive experiments demonstrate that Symbiotic-MoE achieves rapid generative convergence while unlocking cross-modal synergy, boosting inherent understanding with remarkable gains on MMLU and OCRBench.
AutoWeather4D: Autonomous Driving Video Weather Conversion via G-Buffer Dual-Pass Editing
Mar 27, 2026Generative video models have significantly advanced the photorealistic synthesis of adverse weather for autonomous driving; however, they consistently demand massive datasets to learn rare weather scenarios. While 3D-aware editing methods alleviate these data constraints by augmenting existing video footage, they are fundamentally bottlenecked by costly per-scene optimization and suffer from inherent geometric and illumination entanglement. In this work, we introduce AutoWeather4D, a feed-forward 3D-aware weather editing framework designed to explicitly decouple geometry and illumination. At the core of our approach is a G-buffer Dual-pass Editing mechanism. The Geometry Pass leverages explicit structural foundations to enable surface-anchored physical interactions, while the Light Pass analytically resolves light transport, accumulating the contributions of local illuminants into the global illumination to enable dynamic 3D local relighting. Extensive experiments demonstrate that AutoWeather4D achieves comparable photorealism and structural consistency to generative baselines while enabling fine-grained parametric physical control, serving as a practical data engine for autonomous driving.
Universal Pose Pretraining for Generalizable Vision-Language-Action Policies
Feb 23, 2026Existing Vision-Language-Action (VLA) models often suffer from feature collapse and low training efficiency because they entangle high-level perception with sparse, embodiment-specific action supervision. Since these models typically rely on VLM backbones optimized for Visual Question Answering (VQA), they excel at semantic identification but often overlook subtle 3D state variations that dictate distinct action patterns. To resolve these misalignments, we propose Pose-VLA, a decoupled paradigm that separates VLA training into a pre-training phase for extracting universal 3D spatial priors in a unified camera-centric space, and a post-training phase for efficient embodiment alignment within robot-specific action space. By introducing discrete pose tokens as a universal representation, Pose-VLA seamlessly integrates spatial grounding from diverse 3D datasets with geometry-level trajectories from robotic demonstrations. Our framework follows a two-stage pre-training pipeline, establishing fundamental spatial grounding via poses followed by motion alignment through trajectory supervision. Extensive evaluations demonstrate that Pose-VLA achieves state-of-the-art results on RoboTwin 2.0 with a 79.5% average success rate and competitive performance on LIBERO at 96.0%. Real-world experiments further showcase robust generalization across diverse objects using only 100 demonstrations per task, validating the efficiency of our pre-training paradigm.
HumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Feb 02, 2026Enabling humanoid robots to perform agile and adaptive interactive tasks has long been a core challenge in robotics. Current approaches are bottlenecked by either the scarcity of realistic interaction data or the need for meticulous, task-specific reward engineering, which limits their scalability. To narrow this gap, we present HumanX, a full-stack framework that compiles human video into generalizable, real-world interaction skills for humanoids, without task-specific rewards. HumanX integrates two co-designed components: XGen, a data generation pipeline that synthesizes diverse and physically plausible robot interaction data from video while supporting scalable data augmentation; and XMimic, a unified imitation learning framework that learns generalizable interaction skills. Evaluated across five distinct domains--basketball, football, badminton, cargo pickup, and reactive fighting--HumanX successfully acquires 10 different skills and transfers them zero-shot to a physical Unitree G1 humanoid. The learned capabilities include complex maneuvers such as pump-fake turnaround fadeaway jumpshots without any external perception, as well as interactive tasks like sustained human-robot passing sequences over 10 consecutive cycles--learned from a single video demonstration. Our experiments show that HumanX achieves over 8 times higher generalization success than prior methods, demonstrating a scalable and task-agnostic pathway for learning versatile, real-world robot interactive skills.
Gaussian Belief Propagation Network for Depth Completion
Jan 29, 2026Depth completion aims to predict a dense depth map from a color image with sparse depth measurements. Although deep learning methods have achieved state-of-the-art (SOTA), effectively handling the sparse and irregular nature of input depth data in deep networks remains a significant challenge, often limiting performance, especially under high sparsity. To overcome this limitation, we introduce the Gaussian Belief Propagation Network (GBPN), a novel hybrid framework synergistically integrating deep learning with probabilistic graphical models for end-to-end depth completion. Specifically, a scene-specific Markov Random Field (MRF) is dynamically constructed by the Graphical Model Construction Network (GMCN), and then inferred via Gaussian Belief Propagation (GBP) to yield the dense depth distribution. Crucially, the GMCN learns to construct not only the data-dependent potentials of MRF but also its structure by predicting adaptive non-local edges, enabling the capture of complex, long-range spatial dependencies. Furthermore, we enhance GBP with a serial \& parallel message passing scheme, designed for effective information propagation, particularly from sparse measurements. Extensive experiments demonstrate that GBPN achieves SOTA performance on the NYUv2 and KITTI benchmarks. Evaluations across varying sparsity levels, sparsity patterns, and datasets highlight GBPN's superior performance, notable robustness, and generalizable capability.
Geometry-Grounded Gaussian Splatting
Jan 25, 2026Gaussian Splatting (GS) has demonstrated impressive quality and efficiency in novel view synthesis. However, shape extraction from Gaussian primitives remains an open problem. Due to inadequate geometry parameterization and approximation, existing shape reconstruction methods suffer from poor multi-view consistency and are sensitive to floaters. In this paper, we present a rigorous theoretical derivation that establishes Gaussian primitives as a specific type of stochastic solids. This theoretical framework provides a principled foundation for Geometry-Grounded Gaussian Splatting by enabling the direct treatment of Gaussian primitives as explicit geometric representations. Using the volumetric nature of stochastic solids, our method efficiently renders high-quality depth maps for fine-grained geometry extraction. Experiments show that our method achieves the best shape reconstruction results among all Gaussian Splatting-based methods on public datasets.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model
Dec 11, 2025We propose a decoupled 3D scene generation framework called SceneMaker in this work. Due to the lack of sufficient open-set de-occlusion and pose estimation priors, existing methods struggle to simultaneously produce high-quality geometry and accurate poses under severe occlusion and open-set settings. To address these issues, we first decouple the de-occlusion model from 3D object generation, and enhance it by leveraging image datasets and collected de-occlusion datasets for much more diverse open-set occlusion patterns. Then, we propose a unified pose estimation model that integrates global and local mechanisms for both self-attention and cross-attention to improve accuracy. Besides, we construct an open-set 3D scene dataset to further extend the generalization of the pose estimation model. Comprehensive experiments demonstrate the superiority of our decoupled framework on both indoor and open-set scenes. Our codes and datasets is released at https://idea-research.github.io/SceneMaker/.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025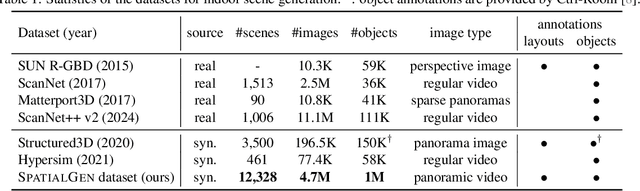
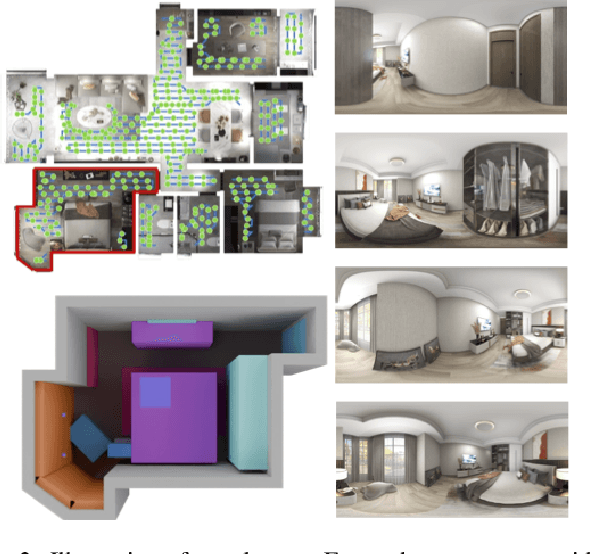
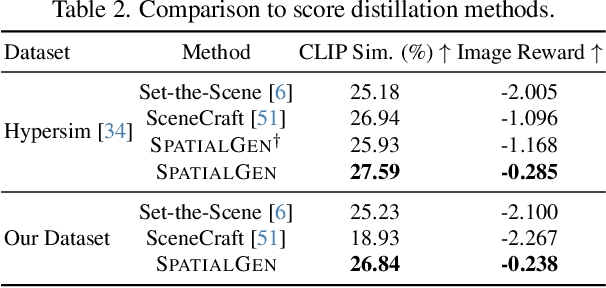
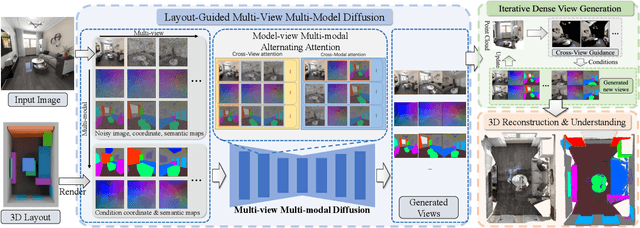
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.