 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-center analysis of deep learning methods for video polyp detection and segmentation
Mar 04, 2026Colonic polyps are well-recognized precursors to colorectal cancer (CRC), typically detected during colonoscopy. However, the variability in appearance, location, and size of these polyps complicates their detection and removal, leading to challenges in effective surveillance, intervention, and subsequently CRC prevention. The processes of colonoscopy surveillance and polyp removal are highly reliant on the expertise of gastroenterologists and occur within the complexities of the colonic structure. As a result, there is a high rate of missed detections and incomplete removal of colonic polyps, which can adversely impact patient outcomes. Recently, automated methods that use machine learning have been developed to enhance polyps detection and segmentation, thus helping clinical processes and reducing missed rates. These advancements highlight the potential for improving diagnostic accuracy in real-time applications, which ultimately facilitates more effective patient management. Furthermore, integrating sequence data and temporal information could significantly enhance the precision of these methods by capturing the dynamic nature of polyp growth and the changes that occur over time. To rigorously investigate these challenges, data scientists and experts gastroenterologists collaborated to compile a comprehensive dataset that spans multiple centers and diverse populations. This initiative aims to underscore the critical importance of incorporating sequence data and temporal information in the development of robust automated detection and segmentation methods. This study evaluates the applicability of deep learning techniques developed in real-time clinical colonoscopy tasks using sequence data, highlighting the critical role of temporal relationships between frames in improving diagnostic precision.
Early and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
Automated Safety Benchmarking: A Multi-agent Pipeline for LVLMs
Jan 27, 2026Large vision-language models (LVLMs) exhibit remarkable capabilities in cross-modal tasks but face significant safety challenges, which undermine their reliability in real-world applications. Efforts have been made to build LVLM safety evaluation benchmarks to uncover their vulnerability. However, existing benchmarks are hindered by their labor-intensive construction process, static complexity, and limited discriminative power. Thus, they may fail to keep pace with rapidly evolving models and emerging risks. To address these limitations, we propose VLSafetyBencher, the first automated system for LVLM safety benchmarking. VLSafetyBencher introduces four collaborative agents: Data Preprocessing, Generation, Augmentation, and Selection agents to construct and select high-quality samples. Experiments validates that VLSafetyBencher can construct high-quality safety benchmarks within one week at a minimal cost. The generated benchmark effectively distinguish safety, with a safety rate disparity of 70% between the most and least safe models.
Geometry-Grounded Gaussian Splatting
Jan 25, 2026Gaussian Splatting (GS) has demonstrated impressive quality and efficiency in novel view synthesis. However, shape extraction from Gaussian primitives remains an open problem. Due to inadequate geometry parameterization and approximation, existing shape reconstruction methods suffer from poor multi-view consistency and are sensitive to floaters. In this paper, we present a rigorous theoretical derivation that establishes Gaussian primitives as a specific type of stochastic solids. This theoretical framework provides a principled foundation for Geometry-Grounded Gaussian Splatting by enabling the direct treatment of Gaussian primitives as explicit geometric representations. Using the volumetric nature of stochastic solids, our method efficiently renders high-quality depth maps for fine-grained geometry extraction. Experiments show that our method achieves the best shape reconstruction results among all Gaussian Splatting-based methods on public datasets.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Jan 09, 2026Verification is a key bottleneck in improving inference speed while maintaining distribution fidelity in Speculative Decoding. Recent work has shown that sequence-level verification leads to a higher number of accepted tokens compared to token-wise verification. However, existing solutions often rely on surrogate approximations or are constrained by partial information, struggling with joint intractability. In this work, we propose Hierarchical Speculative Decoding (HSD), a provably lossless verification method that significantly boosts the expected number of accepted tokens and overcomes joint intractability by balancing excess and deficient probability mass across accessible branches. Our extensive large-scale experiments demonstrate that HSD yields consistent improvements in acceptance rates across diverse model families and benchmarks. Moreover, its strong explainability and generality make it readily integrable into a wide range of speculative decoding frameworks. Notably, integrating HSD into EAGLE-3 yields over a 12% performance gain, establishing state-of-the-art decoding efficiency without compromising distribution fidelity. Code is available at https://github.com/ZhouYuxuanYX/Hierarchical-Speculative-Decoding.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025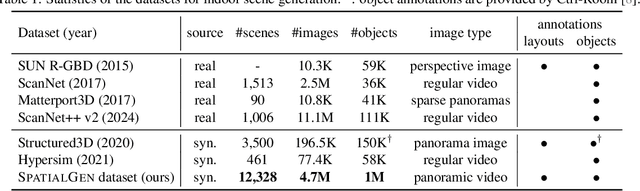
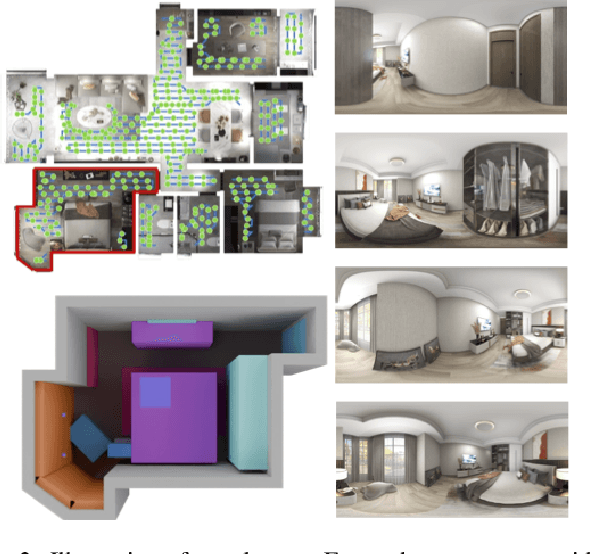
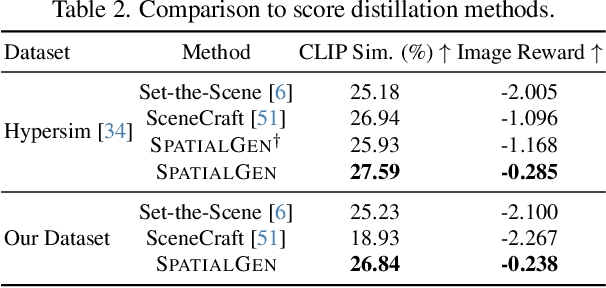
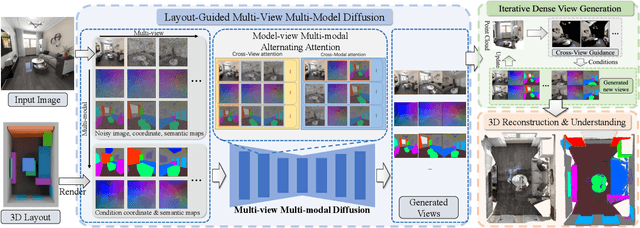
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.
SAIL-Recon: Large SfM by Augmenting Scene Regression with Localization
Aug 25, 2025
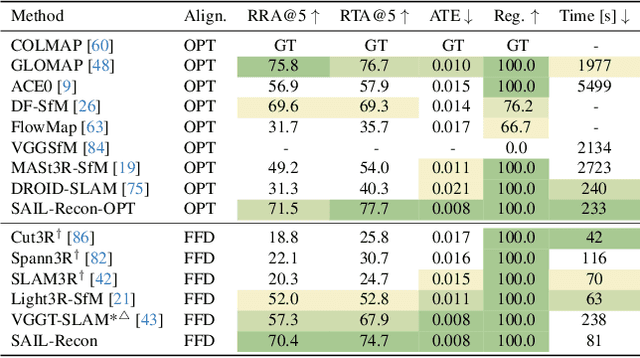
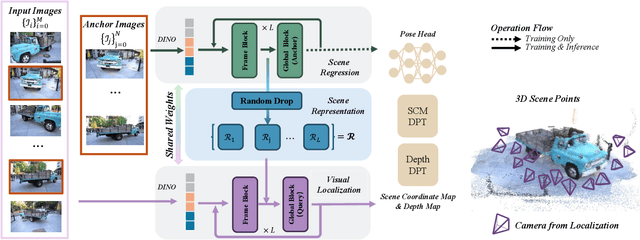
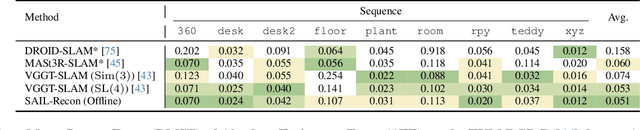
Scene regression methods, such as VGGT, solve the Structure-from-Motion (SfM) problem by directly regressing camera poses and 3D scene structures from input images. They demonstrate impressive performance in handling images under extreme viewpoint changes. However, these methods struggle to handle a large number of input images. To address this problem, we introduce SAIL-Recon, a feed-forward Transformer for large scale SfM, by augmenting the scene regression network with visual localization capabilities. Specifically, our method first computes a neural scene representation from a subset of anchor images. The regression network is then fine-tuned to reconstruct all input images conditioned on this neural scene representation. Comprehensive experiments show that our method not only scales efficiently to large-scale scenes, but also achieves state-of-the-art results on both camera pose estimation and novel view synthesis benchmarks, including TUM-RGBD, CO3Dv2, and Tanks & Temples. We will publish our model and code. Code and models are publicly available at: https://hkust-sail.github.io/ sail-recon/.
Endoscopic Depth Estimation Based on Deep Learning: A Survey
Jul 28, 2025Endoscopic depth estimation is a critical technology for improving the safety and precision of minimally invasive surgery. It has attracted considerable attention from researchers in medical imaging, computer vision, and robotics. Over the past decade, a large number of methods have been developed. Despite the existence of several related surveys, a comprehensive overview focusing on recent deep learning-based techniques is still limited. This paper endeavors to bridge this gap by systematically reviewing the state-of-the-art literature. Specifically, we provide a thorough survey of the field from three key perspectives: data, methods, and applications, covering a range of methods including both monocular and stereo approaches. We describe common performance evaluation metrics and summarize publicly available datasets. Furthermore, this review analyzes the specific challenges of endoscopic scenes and categorizes representative techniques based on their supervision strategies and network architectures. The application of endoscopic depth estimation in the important area of robot-assisted surgery is also reviewed. Finally, we outline potential directions for future research, such as domain adaptation, real-time implementation, and enhanced model generalization, thereby providing a valuable starting point for researchers to engage with and advance the field.
PanTS: The Pancreatic Tumor Segmentation Dataset
Jul 02, 2025PanTS is a large-scale, multi-institutional dataset curated to advance research in pancreatic CT analysis. It contains 36,390 CT scans from 145 medical centers, with expert-validated, voxel-wise annotations of over 993,000 anatomical structures, covering pancreatic tumors, pancreas head, body, and tail, and 24 surrounding anatomical structures such as vascular/skeletal structures and abdominal/thoracic organs. Each scan includes metadata such as patient age, sex, diagnosis, contrast phase, in-plane spacing, slice thickness, etc. AI models trained on PanTS achieve significantly better performance in pancreatic tumor detection, localization, and segmentation compared to those trained on existing public datasets. Our analysis indicates that these gains are directly attributable to the 16x larger-scale tumor annotations and indirectly supported by the 24 additional surrounding anatomical structures. As the largest and most comprehensive resource of its kind, PanTS offers a new benchmark for developing and evaluating AI models in pancreatic CT analysis.
Unleashing Diffusion and State Space Models for Medical Image Segmentation
Jun 15, 2025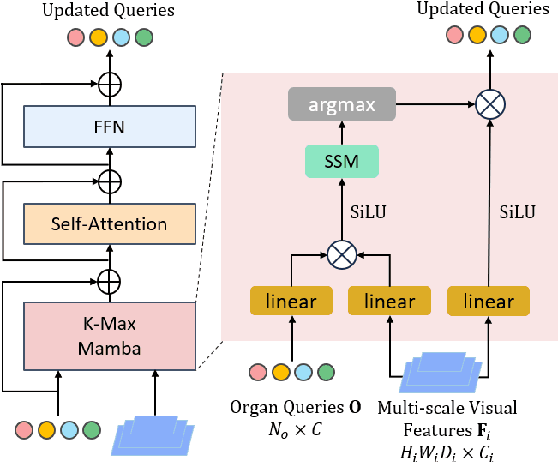
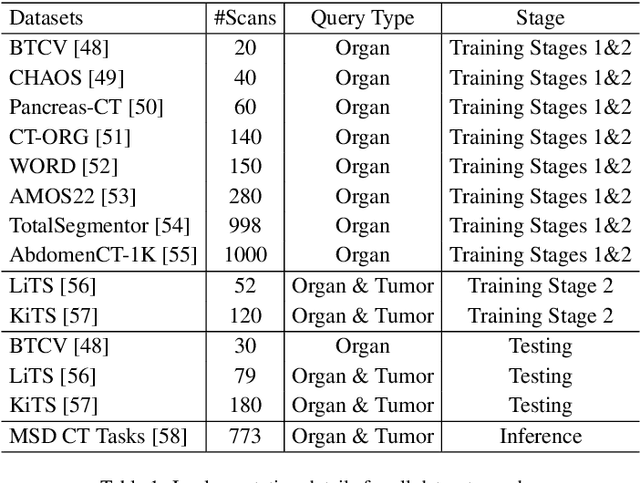
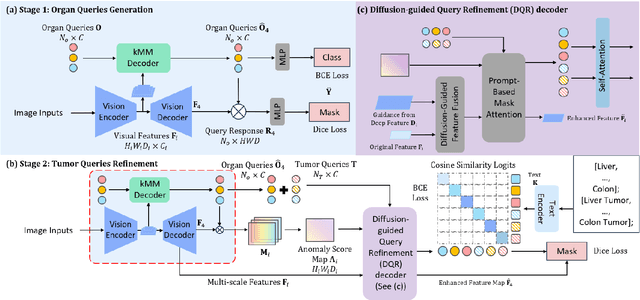
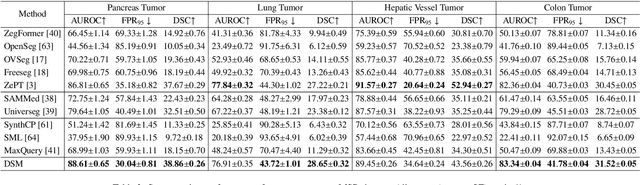
Existing segmentation models trained on a single medical imaging dataset often lack robustness when encountering unseen organs or tumors. Developing a robust model capable of identifying rare or novel tumor categories not present during training is crucial for advancing medical imaging applications. We propose DSM, a novel framework that leverages diffusion and state space models to segment unseen tumor categories beyond the training data. DSM utilizes two sets of object queries trained within modified attention decoders to enhance classification accuracy. Initially, the model learns organ queries using an object-aware feature grouping strategy to capture organ-level visual features. It then refines tumor queries by focusing on diffusion-based visual prompts, enabling precise segmentation of previously unseen tumors. Furthermore, we incorporate diffusion-guided feature fusion to improve semantic segmentation performance. By integrating CLIP text embeddings, DSM captures category-sensitive classes to improve linguistic transfer knowledge, thereby enhancing the model's robustness across diverse scenarios and multi-label tasks. Extensive experiments demonstrate the superior performance of DSM in various tumor segmentation tasks. Code is available at https://github.com/Rows21/KMax-Mamba.