 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Enhancing Radiology Report Generation with Supplementary Knowledge Injection
May 20, 2025Large language models (LLMs) have demonstrated remarkable capabilities in various domains, including radiology report generation. Previous approaches have attempted to utilize multimodal LLMs for this task, enhancing their performance through the integration of domain-specific knowledge retrieval. However, these approaches often overlook the knowledge already embedded within the LLMs, leading to redundant information integration and inefficient utilization of learned representations. To address this limitation, we propose RADAR, a framework for enhancing radiology report generation with supplementary knowledge injection. RADAR improves report generation by systematically leveraging both the internal knowledge of an LLM and externally retrieved information. Specifically, it first extracts the model's acquired knowledge that aligns with expert image-based classification outputs. It then retrieves relevant supplementary knowledge to further enrich this information. Finally, by aggregating both sources, RADAR generates more accurate and informative radiology reports. Extensive experiments on MIMIC-CXR, CheXpert-Plus, and IU X-ray demonstrate that our model outperforms state-of-the-art LLMs in both language quality and clinical accuracy
Learning to Align Multi-Faceted Evaluation: A Unified and Robust Framework
Feb 26, 2025Large Language Models (LLMs) are being used more and more extensively for automated evaluation in various scenarios. Previous studies have attempted to fine-tune open-source LLMs to replicate the evaluation explanations and judgments of powerful proprietary models, such as GPT-4. However, these methods are largely limited to text-based analyses under predefined general criteria, resulting in reduced adaptability for unseen instructions and demonstrating instability in evaluating adherence to quantitative and structural constraints. To address these limitations, we propose a novel evaluation framework, ARJudge, that adaptively formulates evaluation criteria and synthesizes both text-based and code-driven analyses to evaluate LLM responses. ARJudge consists of two components: a fine-tuned Analyzer that generates multi-faceted evaluation analyses and a tuning-free Refiner that combines and refines all analyses to make the final judgment. We construct a Composite Analysis Corpus that integrates tasks for evaluation criteria generation alongside text-based and code-driven analysis generation to train the Analyzer. Our results demonstrate that ARJudge outperforms existing fine-tuned evaluators in effectiveness and robustness. Furthermore, it demonstrates the importance of multi-faceted evaluation and code-driven analyses in enhancing evaluation capabilities.
Memory-Augmented Multimodal LLMs for Surgical VQA via Self-Contained Inquiry
Nov 17, 2024



Comprehensively understanding surgical scenes in Surgical Visual Question Answering (Surgical VQA) requires reasoning over multiple objects. Previous approaches address this task using cross-modal fusion strategies to enhance reasoning ability. However, these methods often struggle with limited scene understanding and question comprehension, and some rely on external resources (e.g., pre-extracted object features), which can introduce errors and generalize poorly across diverse surgical environments. To address these challenges, we propose SCAN, a simple yet effective memory-augmented framework that leverages Multimodal LLMs to improve surgical context comprehension via Self-Contained Inquiry. SCAN operates autonomously, generating two types of memory for context augmentation: Direct Memory (DM), which provides multiple candidates (or hints) to the final answer, and Indirect Memory (IM), which consists of self-contained question-hint pairs to capture broader scene context. DM directly assists in answering the question, while IM enhances understanding of the surgical scene beyond the immediate query. Reasoning over these object-aware memories enables the model to accurately interpret images and respond to questions. Extensive experiments on three publicly available Surgical VQA datasets demonstrate that SCAN achieves state-of-the-art performance, offering improved accuracy and robustness across various surgical scenarios.
Subtle Errors Matter: Preference Learning via Error-injected Self-editing
Oct 09, 2024


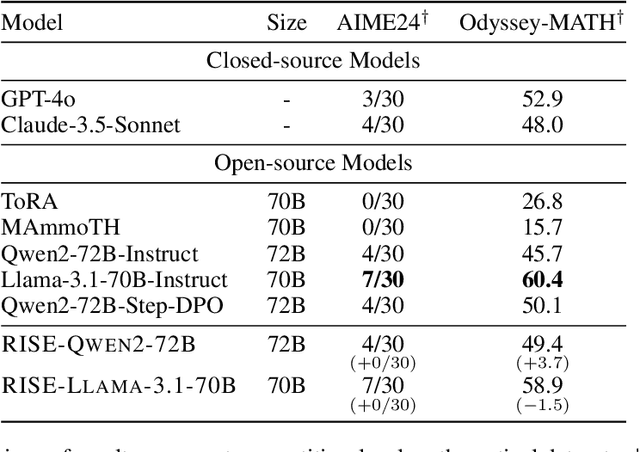
Large Language Models (LLMs) have exhibited strong mathematical reasoning and computational prowess, tackling tasks ranging from basic arithmetic to advanced competition-level problems. However, frequently occurring subtle errors, such as miscalculations or incorrect substitutions, limit the models' full mathematical potential. Existing studies to improve mathematical ability typically involve distilling reasoning skills from stronger LLMs or applying preference learning to step-wise response pairs. Although these methods leverage samples of varying granularity to mitigate reasoning errors, they overlook the frequently occurring subtle errors. A major reason is that sampled preference pairs involve differences unrelated to the errors, which may distract the model from focusing on subtle errors. In this work, we propose a novel preference learning framework called eRror-Injected Self-Editing (RISE), which injects predefined subtle errors into partial tokens of correct solutions to construct hard pairs for error mitigation. In detail, RISE uses the model itself to edit a small number of tokens in the solution, injecting designed subtle errors. Then, pairs composed of self-edited solutions and their corresponding correct ones, along with pairs of correct and incorrect solutions obtained through sampling, are used together for subtle error-aware DPO training. Compared with other preference learning methods, RISE further refines the training objective to focus on predefined errors and their tokens, without requiring fine-grained sampling or preference annotation. Extensive experiments validate the effectiveness of RISE, with preference learning on Qwen2-7B-Instruct yielding notable improvements of 3.0% on GSM8K and 7.9% on MATH.
Integrative Decoding: Improve Factuality via Implicit Self-consistency
Oct 02, 2024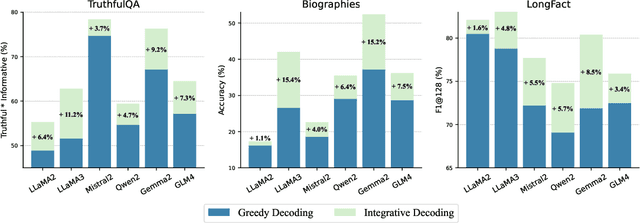
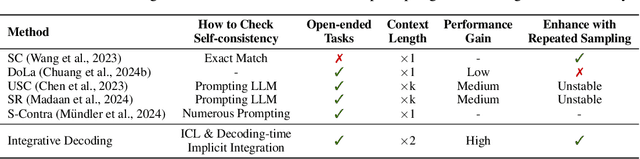
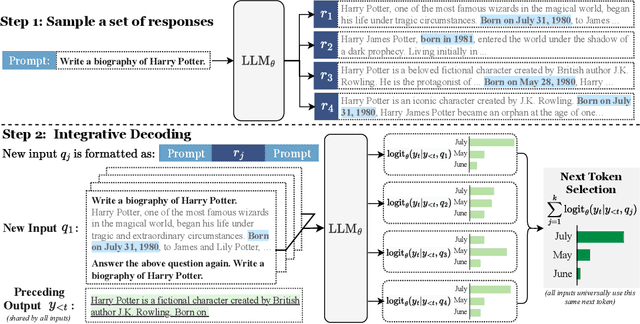
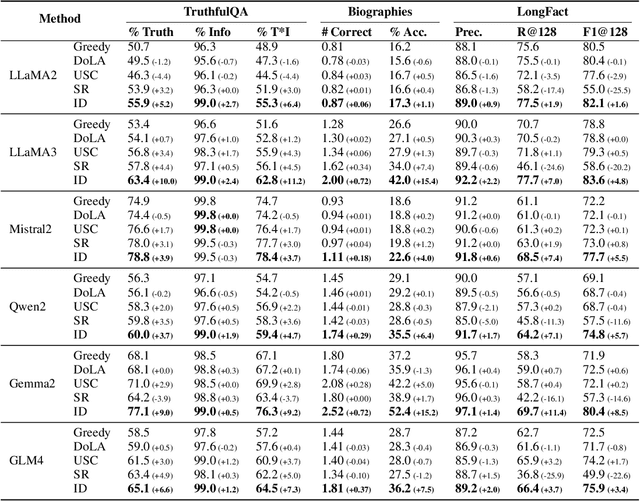
Self-consistency-based approaches, which involve repeatedly sampling multiple outputs and selecting the most consistent one as the final response, prove to be remarkably effective in improving the factual accuracy of large language models. Nonetheless, existing methods usually have strict constraints on the task format, largely limiting their applicability. In this paper, we present Integrative Decoding (ID), to unlock the potential of self-consistency in open-ended generation tasks. ID operates by constructing a set of inputs, each prepended with a previously sampled response, and then processes them concurrently, with the next token being selected by aggregating of all their corresponding predictions at each decoding step. In essence, this simple approach implicitly incorporates self-consistency in the decoding objective. Extensive evaluation shows that ID consistently enhances factuality over a wide range of language models, with substantial improvements on the TruthfulQA (+11.2%), Biographies (+15.4%) and LongFact (+8.5%) benchmarks. The performance gains amplify progressively as the number of sampled responses increases, indicating the potential of ID to scale up with repeated sampling.
Reasoning Like a Doctor: Improving Medical Dialogue Systems via Diagnostic Reasoning Process Alignment
Jun 20, 2024



Medical dialogue systems have attracted significant attention for their potential to act as medical assistants. Enabling these medical systems to emulate clinicians' diagnostic reasoning process has been the long-standing research focus. Previous studies rudimentarily realized the simulation of clinicians' diagnostic process by fine-tuning language models on high-quality dialogue datasets. Nonetheless, they overly focus on the outcomes of the clinician's reasoning process while ignoring their internal thought processes and alignment with clinician preferences. Our work aims to build a medical dialogue system that aligns with clinicians' diagnostic reasoning processes. We propose a novel framework, Emulation, designed to generate an appropriate response that relies on abductive and deductive diagnostic reasoning analyses and aligns with clinician preferences through thought process modeling. Experimental results on two datasets confirm the efficacy of Emulation. Crucially, our framework furnishes clear explanations for the generated responses, enhancing its transparency in medical consultations.
Evolving to be Your Soulmate: Personalized Dialogue Agents with Dynamically Adapted Personas
Jun 20, 2024
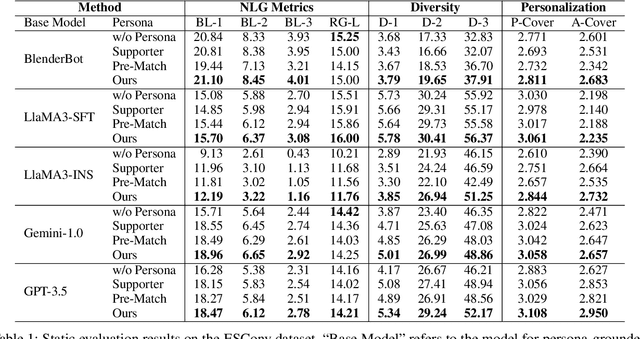
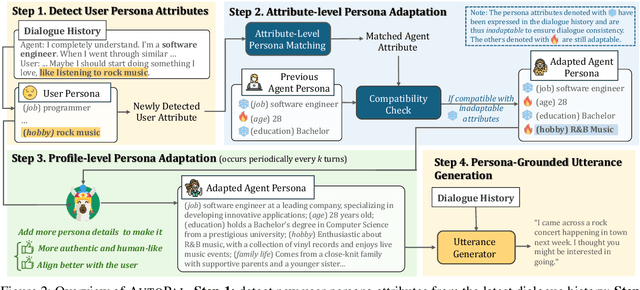
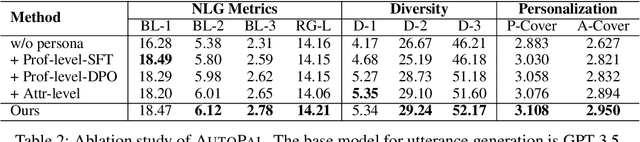
Previous research on persona-based dialogue agents typically preset the agent's persona before deployment, which remains static thereafter. In this paper, we take a step further and explore a new paradigm called Self-evolving Personalized Dialogue Agents (SPDA), where the agent continuously evolves during the conversation to better align with the user's anticipation by dynamically adapting its persona. This paradigm could enable better personalization for each user, but also introduce unique challenges, which mainly lie in the process of persona adaptation. Two key issues include how to achieve persona alignment with the user and how to ensure smooth transition in the adaptation process. To address them, we propose a novel framework that refines the persona at hierarchical levels to progressively align better with the user in a controllable way. Experiments show that integrating the personas adapted by our framework consistently enhances personalization and overall dialogue performance across various base systems.
ICON: Improving Inter-Report Consistency of Radiology Report Generation via Lesion-aware Mix-up Augmentation
Feb 20, 2024
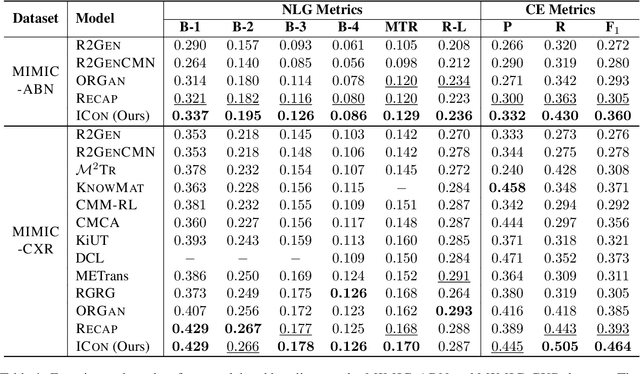

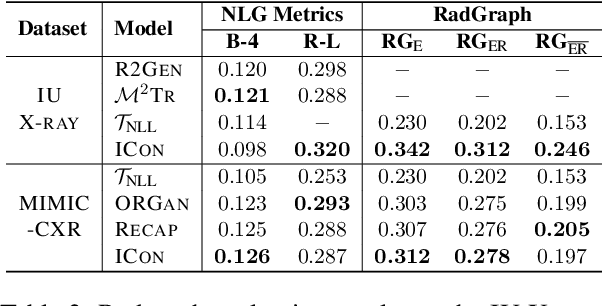
Previous research on radiology report generation has made significant progress in terms of increasing the clinical accuracy of generated reports. In this paper, we emphasize another crucial quality that it should possess, i.e., inter-report consistency, which refers to the capability of generating consistent reports for semantically equivalent radiographs. This quality is even of greater significance than the overall report accuracy in terms of ensuring the system's credibility, as a system prone to providing conflicting results would severely erode users' trust. Regrettably, existing approaches struggle to maintain inter-report consistency, exhibiting biases towards common patterns and susceptibility to lesion variants. To address this issue, we propose ICON, which improves the inter-report consistency of radiology report generation. Aiming at enhancing the system's ability to capture the similarities in semantically equivalent lesions, our approach involves first extracting lesions from input images and examining their characteristics. Then, we introduce a lesion-aware mix-up augmentation technique to ensure that the representations of the semantically equivalent lesions align with the same attributes, by linearly interpolating them during the training phase. Extensive experiments on three publicly available chest X-ray datasets verify the effectiveness of our approach, both in terms of improving the consistency and accuracy of the generated reports.
Medical Dialogue Generation via Intuitive-then-Analytical Differential Diagnosis
Jan 12, 2024Medical dialogue systems have attracted growing research attention as they have the potential to provide rapid diagnoses, treatment plans, and health consultations. In medical dialogues, a proper diagnosis is crucial as it establishes the foundation for future consultations. Clinicians typically employ both intuitive and analytic reasoning to formulate a differential diagnosis. This reasoning process hypothesizes and verifies a variety of possible diseases and strives to generate a comprehensive and rigorous diagnosis. However, recent studies on medical dialogue generation have overlooked the significance of modeling a differential diagnosis, which hinders the practical application of these systems. To address the above issue, we propose a medical dialogue generation framework with the Intuitive-then-Analytic Differential Diagnosis (IADDx). Our method starts with a differential diagnosis via retrieval-based intuitive association and subsequently refines it through a graph-enhanced analytic procedure. The resulting differential diagnosis is then used to retrieve medical knowledge and guide response generation. Experimental results on two datasets validate the efficacy of our method. Besides, we demonstrate how our framework assists both clinicians and patients in understanding the diagnostic process, for instance, by producing intermediate results and graph-based diagnosis paths.
RECAP: Towards Precise Radiology Report Generation via Dynamic Disease Progression Reasoning
Oct 21, 2023Automating radiology report generation can significantly alleviate radiologists' workloads. Previous research has primarily focused on realizing highly concise observations while neglecting the precise attributes that determine the severity of diseases (e.g., small pleural effusion). Since incorrect attributes will lead to imprecise radiology reports, strengthening the generation process with precise attribute modeling becomes necessary. Additionally, the temporal information contained in the historical records, which is crucial in evaluating a patient's current condition (e.g., heart size is unchanged), has also been largely disregarded. To address these issues, we propose RECAP, which generates precise and accurate radiology reports via dynamic disease progression reasoning. Specifically, RECAP first predicts the observations and progressions (i.e., spatiotemporal information) given two consecutive radiographs. It then combines the historical records, spatiotemporal information, and radiographs for report generation, where a disease progression graph and dynamic progression reasoning mechanism are devised to accurately select the attributes of each observation and progression. Extensive experiments on two publicly available datasets demonstrate the effectiveness of our model.