 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTIS: Agentic Risk-Aware Test-Time Scaling via Iterative Simulation
Feb 03, 2026Current test-time scaling (TTS) techniques enhance large language model (LLM) performance by allocating additional computation at inference time, yet they remain insufficient for agentic settings, where actions directly interact with external environments and their effects can be irreversible and costly. We propose ARTIS, Agentic Risk-Aware Test-Time Scaling via Iterative Simulation, a framework that decouples exploration from commitment by enabling test-time exploration through simulated interactions prior to real-world execution. This design allows extending inference-time computation to improve action-level reliability and robustness without incurring environmental risk. We further show that naive LLM-based simulators struggle to capture rare but high-impact failure modes, substantially limiting their effectiveness for agentic decision making. To address this limitation, we introduce a risk-aware tool simulator that emphasizes fidelity on failure-inducing actions via targeted data generation and rebalanced training. Experiments on multi-turn and multi-step agentic benchmarks demonstrate that iterative simulation substantially improves agent reliability, and that risk-aware simulation is essential for consistently realizing these gains across models and tasks.
From Verifiable Dot to Reward Chain: Harnessing Verifiable Reference-based Rewards for Reinforcement Learning of Open-ended Generation
Jan 26, 2026Reinforcement learning with verifiable rewards (RLVR) succeeds in reasoning tasks (e.g., math and code) by checking the final verifiable answer (i.e., a verifiable dot signal). However, extending this paradigm to open-ended generation is challenging because there is no unambiguous ground truth. Relying on single-dot supervision often leads to inefficiency and reward hacking. To address these issues, we propose reinforcement learning with verifiable reference-based rewards (RLVRR). Instead of checking the final answer, RLVRR extracts an ordered linguistic signal from high-quality references (i.e, reward chain). Specifically, RLVRR decomposes rewards into two dimensions: content, which preserves deterministic core concepts (e.g., keywords), and style, which evaluates adherence to stylistic properties through LLM-based verification. In this way, RLVRR combines the exploratory strength of RL with the efficiency and reliability of supervised fine-tuning (SFT). Extensive experiments on more than 10 benchmarks with Qwen and Llama models confirm the advantages of our approach. RLVRR (1) substantially outperforms SFT trained with ten times more data and advanced reward models, (2) unifies the training of structured reasoning and open-ended generation, and (3) generalizes more effectively while preserving output diversity. These results establish RLVRR as a principled and efficient path toward verifiable reinforcement learning for general-purpose LLM alignment. We release our code and data at https://github.com/YJiangcm/RLVRR.
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
May 23, 2025Mathematical reasoning through Chain-of-Thought (CoT) has emerged as a powerful capability of Large Language Models (LLMs), which can be further enhanced through Test-Time Scaling (TTS) methods like Beam Search and DVTS. However, these methods, despite improving accuracy by allocating more computational resources during inference, often suffer from path homogenization and inefficient use of intermediate results. To address these limitations, we propose Stepwise Reasoning Checkpoint Analysis (SRCA), a framework that introduces checkpoints between reasoning steps. It incorporates two key strategies: (1) Answer-Clustered Search, which groups reasoning paths by their intermediate checkpoint answers to maintain diversity while ensuring quality, and (2) Checkpoint Candidate Augmentation, which leverages all intermediate answers for final decision-making. Our approach effectively reduces path homogenization and creates a fault-tolerant mechanism by utilizing high-quality intermediate results. Experimental results show that SRCA improves reasoning accuracy compared to existing TTS methods across various mathematical datasets.
ToolACE-R: Tool Learning with Adaptive Self-Refinement
Apr 02, 2025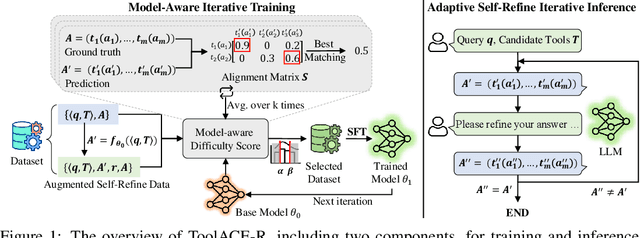
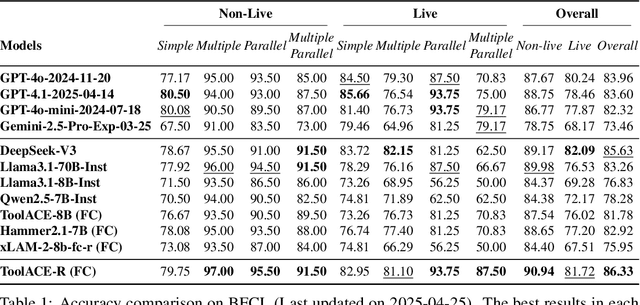
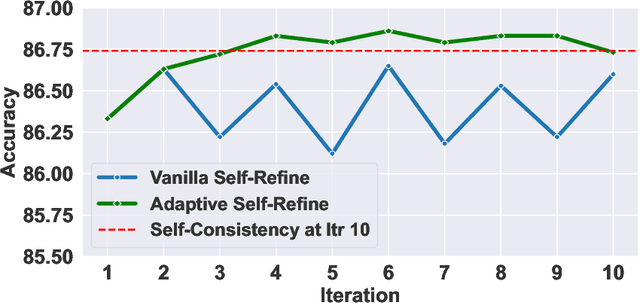

Tool learning, which allows Large Language Models (LLMs) to leverage external tools for solving complex user tasks, has emerged as a promising avenue for extending model capabilities. However, current approaches primarily focus on data synthesis for fine-tuning LLMs to invoke tools effectively, largely ignoring how to fully stimulate the potential of the model. In this paper, we propose ToolACE-R, a novel method that introduces adaptive self-refinement for tool invocations. Our approach features a model-aware iterative training procedure that progressively incorporates more training samples based on the model's evolving capabilities. Additionally, it allows LLMs to iteratively refine their tool calls, optimizing performance without requiring external feedback. To further enhance computational efficiency, we integrate an adaptive mechanism when scaling the inference time, enabling the model to autonomously determine when to stop the refinement process. We conduct extensive experiments across several benchmark datasets, showing that ToolACE-R achieves competitive performance compared to advanced API-based models, even without any refinement. Furthermore, its performance can be further improved efficiently through adaptive self-refinement. Our results demonstrate the effectiveness of the proposed method, which is compatible with base models of various sizes, offering a promising direction for more efficient tool learning.
Learning to Align Multi-Faceted Evaluation: A Unified and Robust Framework
Feb 26, 2025Large Language Models (LLMs) are being used more and more extensively for automated evaluation in various scenarios. Previous studies have attempted to fine-tune open-source LLMs to replicate the evaluation explanations and judgments of powerful proprietary models, such as GPT-4. However, these methods are largely limited to text-based analyses under predefined general criteria, resulting in reduced adaptability for unseen instructions and demonstrating instability in evaluating adherence to quantitative and structural constraints. To address these limitations, we propose a novel evaluation framework, ARJudge, that adaptively formulates evaluation criteria and synthesizes both text-based and code-driven analyses to evaluate LLM responses. ARJudge consists of two components: a fine-tuned Analyzer that generates multi-faceted evaluation analyses and a tuning-free Refiner that combines and refines all analyses to make the final judgment. We construct a Composite Analysis Corpus that integrates tasks for evaluation criteria generation alongside text-based and code-driven analysis generation to train the Analyzer. Our results demonstrate that ARJudge outperforms existing fine-tuned evaluators in effectiveness and robustness. Furthermore, it demonstrates the importance of multi-faceted evaluation and code-driven analyses in enhancing evaluation capabilities.
Crowd Comparative Reasoning: Unlocking Comprehensive Evaluations for LLM-as-a-Judge
Feb 18, 2025



LLM-as-a-Judge, which generates chain-of-thought (CoT) judgments, has become a widely adopted auto-evaluation method. However, its reliability is compromised by the CoT reasoning's inability to capture comprehensive and deeper details, often leading to incomplete outcomes. Existing methods mainly rely on majority voting or criteria expansion, which is insufficient to address the limitation in CoT. We propose Crowd-based Comparative Evaluation, which introduces additional crowd responses to compare with the candidate responses, thereby exposing deeper and more comprehensive details within the candidate responses. This process effectively guides LLM-as-a-Judge to provide a more detailed CoT judgment. Extensive experiments demonstrate that our approach enhances evaluation reliability, achieving an average accuracy gain of 6.7% across five benchmarks. Moreover, our method produces higher-quality CoTs that facilitate judge distillation and exhibit superior performance in rejection sampling for supervised fine-tuning (SFT), referred to as crowd rejection sampling, thereby enabling more efficient SFT. Our analysis confirms that CoTs generated by ours are more comprehensive and of higher quality, and evaluation accuracy improves as inference scales.
NILE: Internal Consistency Alignment in Large Language Models
Dec 21, 2024As a crucial step to enhance LLMs alignment with human intentions, Instruction Fine-Tuning (IFT) has a high demand on dataset quality. However, existing IFT datasets often contain knowledge that is inconsistent with LLMs' internal knowledge learned from the pre-training phase, which can greatly affect the efficacy of IFT. To address this issue, we introduce NILE (iNternal consIstency aLignmEnt) framework, aimed at optimizing IFT datasets to unlock LLMs' capability further. NILE operates by eliciting target pre-trained LLM's internal knowledge corresponding to instruction data. The internal knowledge is leveraged to revise the answer in IFT datasets. Additionally, we propose a novel Internal Consistency Filtering (ICF) method to filter training samples, ensuring its high consistency with LLM's internal knowledge. Our experiments demonstrate that NILE-aligned IFT datasets sharply boost LLM performance across multiple LLM ability evaluation datasets, achieving up to 66.6% gain on Arena-Hard and 68.5% on Alpaca-Eval V2. Further analysis confirms that each component of the NILE}framework contributes to these substantial performance improvements, and provides compelling evidence that dataset consistency with pre-trained internal knowledge is pivotal for maximizing LLM potential.
ToolFlow: Boosting LLM Tool-Calling Through Natural and Coherent Dialogue Synthesis
Oct 24, 2024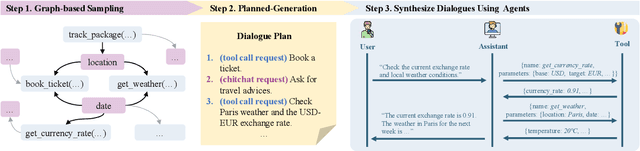
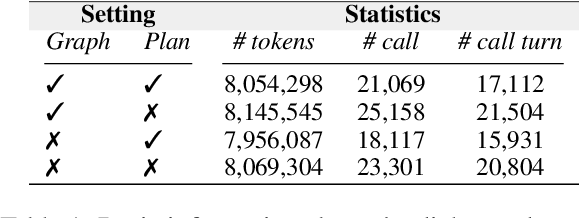


Supervised fine-tuning (SFT) is a common method to enhance the tool calling capabilities of Large Language Models (LLMs), with the training data often being synthesized. The current data synthesis process generally involves sampling a set of tools, formulating a requirement based on these tools, and generating the call statements. However, tools sampled randomly lack relevance, making them difficult to combine and thus reducing the diversity of the data. Additionally, current work overlooks the coherence between turns of dialogues, leading to a gap between the synthesized data and real-world scenarios. To address these issues, we propose a Graph-based Sampling strategy to sample more relevant tool combinations, and a Planned-generation strategy to create plans that guide the synthesis of coherent dialogues. We integrate these two strategies and enable multiple agents to synthesize the dialogue data interactively, resulting in our tool-calling data synthesis pipeline ToolFlow. Data quality assessments demonstrate improvements in the naturalness and coherence of our synthesized dialogues. Finally, we apply SFT on LLaMA-3.1-8B using 8,000 synthetic dialogues generated with ToolFlow. Results show that the model achieves tool-calling performance comparable to or even surpassing GPT-4, while maintaining strong general capabilities.
Subtle Errors Matter: Preference Learning via Error-injected Self-editing
Oct 09, 2024


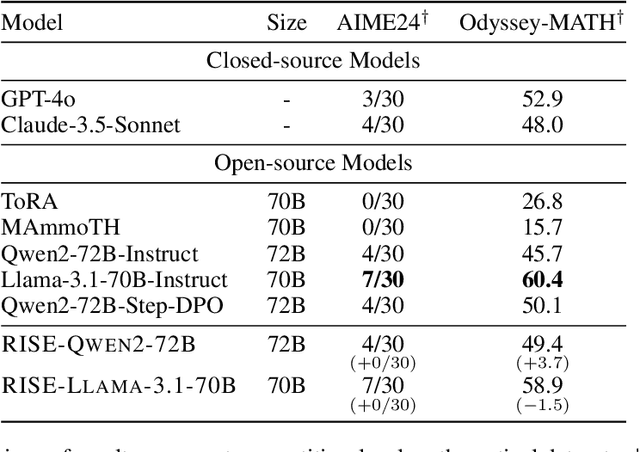
Large Language Models (LLMs) have exhibited strong mathematical reasoning and computational prowess, tackling tasks ranging from basic arithmetic to advanced competition-level problems. However, frequently occurring subtle errors, such as miscalculations or incorrect substitutions, limit the models' full mathematical potential. Existing studies to improve mathematical ability typically involve distilling reasoning skills from stronger LLMs or applying preference learning to step-wise response pairs. Although these methods leverage samples of varying granularity to mitigate reasoning errors, they overlook the frequently occurring subtle errors. A major reason is that sampled preference pairs involve differences unrelated to the errors, which may distract the model from focusing on subtle errors. In this work, we propose a novel preference learning framework called eRror-Injected Self-Editing (RISE), which injects predefined subtle errors into partial tokens of correct solutions to construct hard pairs for error mitigation. In detail, RISE uses the model itself to edit a small number of tokens in the solution, injecting designed subtle errors. Then, pairs composed of self-edited solutions and their corresponding correct ones, along with pairs of correct and incorrect solutions obtained through sampling, are used together for subtle error-aware DPO training. Compared with other preference learning methods, RISE further refines the training objective to focus on predefined errors and their tokens, without requiring fine-grained sampling or preference annotation. Extensive experiments validate the effectiveness of RISE, with preference learning on Qwen2-7B-Instruct yielding notable improvements of 3.0% on GSM8K and 7.9% on MATH.
RevisEval: Improving LLM-as-a-Judge via Response-Adapted References
Oct 07, 2024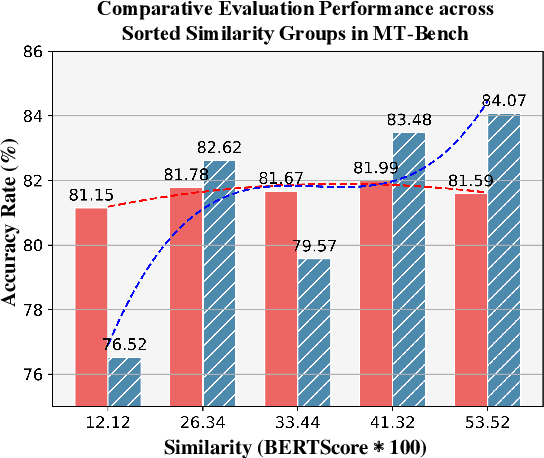
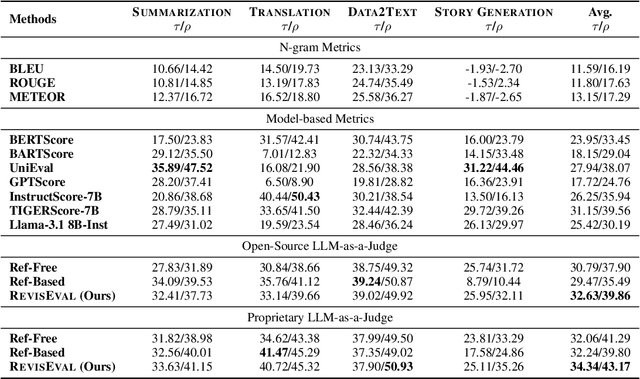
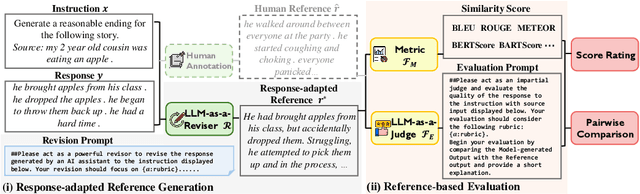
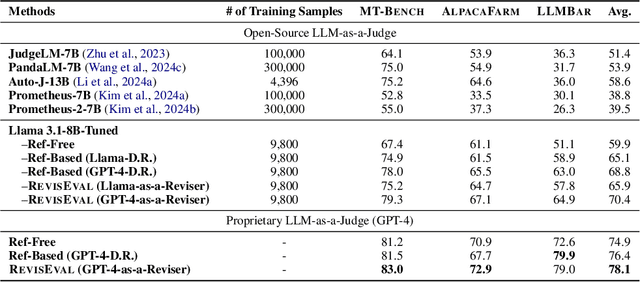
With significant efforts in recent studies, LLM-as-a-Judge has become a cost-effective alternative to human evaluation for assessing the text generation quality in a wide range of tasks. However, there still remains a reliability gap between LLM-as-a-Judge and human evaluation. One important reason is the lack of guided oracles in the evaluation process. Motivated by the role of reference pervasively used in classic text evaluation, we introduce RevisEval, a novel text generation evaluation paradigm via the response-adapted references. RevisEval is driven by the key observation that an ideal reference should maintain the necessary relevance to the response to be evaluated. Specifically, RevisEval leverages the text revision capabilities of large language models (LLMs) to adaptively revise the response, then treat the revised text as the reference (response-adapted reference) for the subsequent evaluation. Extensive experiments demonstrate that RevisEval outperforms traditional reference-free and reference-based evaluation paradigms that use LLM-as-a-Judge across NLG tasks and open-ended instruction-following tasks. More importantly, our response-adapted references can further boost the classical text metrics, e.g., BLEU and BERTScore, compared to traditional references and even rival the LLM-as-a-Judge. A detailed analysis is also conducted to confirm RevisEval's effectiveness in bias reduction, the impact of inference cost, and reference relevance.