 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilar Users-Augmented Interest Network
Apr 26, 2026Click-through rate (CTR) prediction is one of the core tasks in recommender systems. User behavior sequences, as one of the most effective features, can accurately reflect user preferences and significantly improve prediction accuracy. Richer behavior sequences often enable more comprehensive user profiling, and recent studies have shown that scaling the length of user behavior sequence can yield substantial gains in CTR. However, due to the widespread sparsity in recommender systems, incomplete behavior sequences are common in real-world scenarios. Existing sequential modeling methods often rely solely on the target user's own behavior, and therefore struggle in such scenarios. This paper proposes a novel method called SUIN (Similar Users-augmented Interest Network), which enhances the target user's behavior sequence with behaviors from similar users to enhance the user profile for CTR prediction. Specifically, we use behavior embeddings encoded by a sequence encoder to retrieve users with similar behaviors from a user retrieval pool. The behavior sequences of these similar users are then concatenated with that of the target user in descending order of similarity to construct an augmented sequence. Given that the augmented sequence contains behaviors from multiple users, we propose a user-specific target-aware position encoding, which identifies the source user of each behavior and captures its relative position to the target item. Furthermore, to mitigate the empirically observed noise in similar users' behaviors, we design a user-aware target attention that jointly considers item-item and user-user correlations, fully exploiting the potential of the augmented behavior sequence. Comprehensive experiments on widely-used short-term and long-term sequence benchmark datasets demonstrate that our method significantly outperforms state-of-the-art sequential CTR models.
LLM-Guided Safety Agent for Edge Robotics with an ISO-Compliant Perception-Compute-Control Architecture
Apr 22, 2026Ensuring functional safety in human-robot interaction is challenging because AI perception is inherently probabilistic, whereas industrial standards require deterministic behavior. We present an LLM-guided safety agent for edge robotics, built on an ISO-compliant low-latency perception-compute-control architecture. Our method translates natural-language safety regulations into executable predicates and deploys them through a redundant heterogeneous edge runtime. For fault-tolerant closed-loop execution under edge constraints, we adopt a symmetric dual-modular redundancy design with parallel independent execution for low-latency perception, computation, and control. We prototype the system on a dual-RK3588 platform and evaluate it in representative human-robot interaction scenarios. The results demonstrate a practical edge implementation path toward ISO 13849 Category 3 and PL d using cost-effective hardware, supporting practical deployment of safety-critical embodied AI.
Agentic LLM Reasoning in a Self-Driving Laboratory for Air-Sensitive Lithium Halide Spinel Conductors
Apr 13, 2026Self-driving laboratories promise to accelerate materials discovery. Yet current automated solid-state synthesis platforms are limited to ambient conditions, thereby precluding their use for air-sensitive materials. Here, we present A-Lab for Glovebox Powder Solid-state Synthesis (A-Lab GPSS), a robotic platform capable of synthesizing and characterizing air-sensitive inorganic materials under strict air-free conditions. By integrating an agentic AI framework into the A-Lab GPSS platform, we structure autonomous experimental design through abductive and inductive reasoning. We deploy this platform to explore the vast compositional space of lithium halide spinel solid-state ionic conductors. Across a synthesis campaign comprising 352 samples with diverse compositions, the system explores a broad chemical space, experimentally realizing 72% of the 171 possible pairwise combinations among the 19 metals considered in this study. Over the course of the campaign, the fraction of compositions exhibiting both good ionic conductivity (> 0.05 mS/cm) and high halide spinel phase purity increases from 1.33% in the first 75 agent-proposed samples to 5.33% in the final 75. Furthermore, by inspecting the AI's reasoning processes, we reveal distinct yet complementary discovery strategies: abductive reasoning interrogates abnormal observations within already explored regions, whereas inductive reasoning expands the search into broader, previously unvisited chemical space. This work establishes a scalable platform for the autonomous discovery of complex, air-sensitive solid-state materials.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
TAPO: Translation Augmented Policy Optimization for Multilingual Mathematical Reasoning
Mar 26, 2026Large Language Models (LLMs) have demonstrated remarkable proficiency in English mathematical reasoning, yet a significant performance disparity persists in multilingual contexts, largely attributed to deficiencies in language understanding. To bridge this gap, we introduce Translation-Augmented Policy Optimization (TAPO), a novel reinforcement learning framework built upon GRPO. TAPO enforces an explicit alignment strategy where the model leverages English as a pivot and follows an understand-then-reason paradigm. Crucially, we employ a step-level relative advantage mechanism that decouples understanding from reasoning, allowing the integration of translation quality rewards without introducing optimization conflicts. Extensive experiments reveal that TAPO effectively synergizes language understanding with reasoning capabilities and is compatible with various models. It outperforms baseline methods in both multilingual mathematical reasoning and translation tasks, while generalizing well to unseen languages and out-of-domain tasks.
MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Feb 15, 2026As industrial recommender systems enter a scaling-driven regime, Transformer architectures have become increasingly attractive for scaling models towards larger capacity and longer sequence. However, existing Transformer-based recommendation models remain structurally fragmented, where sequence modeling and feature interaction are implemented as separate modules with independent parameterization. Such designs introduce a fundamental co-scaling challenge, as model capacity must be suboptimally allocated between dense feature interaction and sequence modeling under a limited computational budget. In this work, we propose MixFormer, a unified Transformer-style architecture tailored for recommender systems, which jointly models sequential behaviors and feature interactions within a single backbone. Through a unified parameterization, MixFormer enables effective co-scaling across both dense capacity and sequence length, mitigating the trade-off observed in decoupled designs. Moreover, the integrated architecture facilitates deep interaction between sequential and non-sequential representations, allowing high-order feature semantics to directly inform sequence aggregation and enhancing overall expressiveness. To ensure industrial practicality, we further introduce a user-item decoupling strategy for efficiency optimizations that significantly reduce redundant computation and inference latency. Extensive experiments on large-scale industrial datasets demonstrate that MixFormer consistently exhibits superior accuracy and efficiency. Furthermore, large-scale online A/B tests on two production recommender systems, Douyin and Douyin Lite, show consistent improvements in user engagement metrics, including active days and in-app usage duration.
CASCADE: Cumulative Agentic Skill Creation through Autonomous Development and Evolution
Dec 29, 2025Large language model (LLM) agents currently depend on predefined tools or brittle tool generation, constraining their capability and adaptability to complex scientific tasks. We introduce CASCADE, a self-evolving agentic framework representing an early instantiation of the transition from "LLM + tool use" to "LLM + skill acquisition". CASCADE enables agents to master complex external tools and codify knowledge through two meta-skills: continuous learning via web search and code extraction, and self-reflection via introspection and knowledge graph exploration, among others. We evaluate CASCADE on SciSkillBench, a benchmark of 116 materials science and chemistry research tasks. CASCADE achieves a 93.3% success rate using GPT-5, compared to 35.4% without evolution mechanisms. We further demonstrate real-world applications in computational analysis, autonomous laboratory experiments, and selective reproduction of published papers. Along with human-agent collaboration and memory consolidation, CASCADE accumulates executable skills that can be shared across agents and scientists, moving toward scalable AI-assisted scientific research.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
NDCG-Consistent Softmax Approximation with Accelerated Convergence
Jun 11, 2025
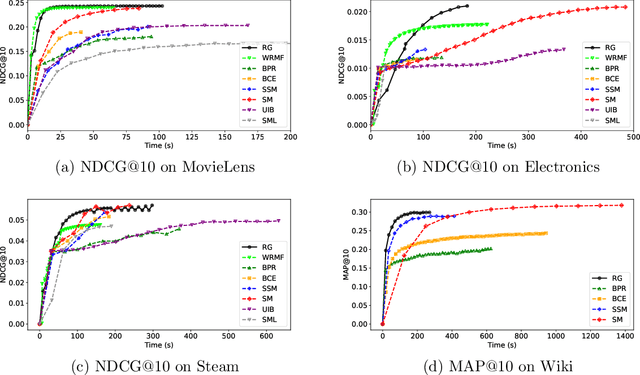

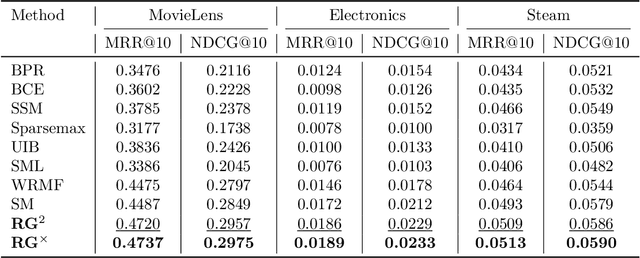
Ranking tasks constitute fundamental components of extreme similarity learning frameworks, where extremely large corpora of objects are modeled through relative similarity relationships adhering to predefined ordinal structures. Among various ranking surrogates, Softmax (SM) Loss has been widely adopted due to its natural capability to handle listwise ranking via global negative comparisons, along with its flexibility across diverse application scenarios. However, despite its effectiveness, SM Loss often suffers from significant computational overhead and scalability limitations when applied to large-scale object spaces. To address this challenge, we propose novel loss formulations that align directly with ranking metrics: the Ranking-Generalizable \textbf{squared} (RG$^2$) Loss and the Ranking-Generalizable interactive (RG$^\times$) Loss, both derived through Taylor expansions of the SM Loss. Notably, RG$^2$ reveals the intrinsic mechanisms underlying weighted squared losses (WSL) in ranking methods and uncovers fundamental connections between sampling-based and non-sampling-based loss paradigms. Furthermore, we integrate the proposed RG losses with the highly efficient Alternating Least Squares (ALS) optimization method, providing both generalization guarantees and convergence rate analyses. Empirical evaluations on real-world datasets demonstrate that our approach achieves comparable or superior ranking performance relative to SM Loss, while significantly accelerating convergence. This framework offers the similarity learning community both theoretical insights and practically efficient tools, with methodologies applicable to a broad range of tasks where balancing ranking quality and computational efficiency is essential.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.