 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgVLA-Bench: Towards Evaluating Vision-Language-Action Models for Laparoscopic Surgical Robotics
Jun 28, 2026Vision-Language-Action (VLA) models represent a promising direction for embodied intelligence in surgical robotics. Despite the prevalence of VLA benchmarks for general robotics, standardized evaluation platforms specifically designed for surgical contexts remain absent. To address this limitation, we present SurgVLA-Bench, the first comprehensive benchmark for evaluating VLA models in laparoscopic surgical robotics. Leveraging the SurRoL simulation platform, we construct a hierarchical task taxonomy ranging from atomic actions to complete surgical procedures, complemented by a multi-dimensional evaluation framework assessing action accuracy and semantic consistency. We then systematically evaluate two representative paradigms, including autoregressive models such as OpenVLA, and flow matching models such as $π_{0}$, $π_{0.5}$, and SmolVLA. Our experiments show that autoregressive models tend to excel in semantic understanding, while flow matching models often achieve higher task precision but may face generalization trade-offs. However, even the best-performing models remain far from satisfactory, as the constrained endoscopic field of view, restricted viewing angles, and frequent occlusions persist as fundamental physical bottlenecks. The code and data are available at https://github.com/VCL-HNU/SurgVLA
Amortized Probabilistic Retrieval of Atmospheric CO2 from OCO-2 Spectra Using Deep Learning with Laplace Approximations and Normalizing Flows
Jun 16, 2026Space-based monitoring of atmospheric carbon dioxide (CO2) is essential for constraining the global carbon budget. NASA's Orbiting Carbon Observatory-2 (OCO-2) estimates column-averaged dry-air mole fractions of CO2 (XCO2) using high-resolution spectra. However, current operational retrieval algorithms are computationally expensive and do not properly quantify uncertainties. We present a novel deep learning framework that addresses these challenges. Due to the difficulties of ground-truth data for real satellite observations, we develop and validate our approach using a high-fidelity simulation dataset. This dataset, created to support OCO-2 uncertainty quantification (UQ), incorporates realistic forward model errors. Our architecture encodes spectral bands using a multi-branch neural network and estimates posteriors of the full CO2 column or desired summaries thereof using two scalable UQ methods: Laplace approximations and normalizing flows. Our approach has five key advantages relative to operational "full-physics" solvers: (1) Amortization: Inference is orders of magnitude faster, enabling real-time processing of massive data streams; (2) Model error robustness: By training on simulations that explicitly include model discrepancies, our method accounts for systematic errors often neglected by standard inversions; (3) Point estimate accuracy: We achieve superior predictive accuracy compared to baseline methods; (4) Improved UQ: The probabilistic outputs yield better-calibrated uncertainty estimates; and (5) Non-Gaussian posteriors: When utilizing normalizing flows, our framework successfully models complex, asymmetric posterior distributions, overcoming the limitations of the Gaussian assumption. These results suggest that simulation-based deep learning is a viable path toward next-generation operational processing systems.
GeoCFNet: Geometry-Aware Confidence Field Network for Robot-Assisted Endoscopic Submucosal Dissection
Jun 11, 2026Advanced surgical robotics has made robot-assisted endoscopic submucosal dissection (ESD) a promising approach for the en-bloc resection of large lesions, with the potential to reduce recurrence and improve long-term outcomes. However, the technical complexity and risk of complications in ESD demand stable and precise visual guidance to maintain an accurate dissection corridor and a safe tissue margin. Dense confidence fields provide an effective representation for this purpose by describing both the preferred dissection region and its spatial transition to surrounding tissue. However, reliable confidence field estimation remains challenging in dynamic endoscopic scenes due to smoke, specular highlights, tissue deformation, weak texture, and the thin geometric structure of the target region. To address these challenges, we formulate dissection guidance as a geometry-aware confidence field estimation problem and propose GeoCFNet, a geometry-aware confidence field network built on a pretrained DINOv3 backbone. GeoCFNet integrates a Token-Differentiated Fusion module to aggregate class-token context with dense patch representations, a SegFormer decoder for confidence regression, and Geometry-Aware Spatial Regularization (GASR) to preserve spatial coherence and local geometric transitions. Experimental results show that GeoCFNet achieves RMSE 0.0480, PSNR 27.1995, SSIM 0.3397, and CC 0.2466, indicating accurate and geometrically stable confidence field estimation for robot-assisted ESD guidance.
Unsupervised MR-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
Feb 16, 2026Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on Multilevel Correlation Pyramidal Optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is available at https://github.com/wjiazheng/MCPO.
Unsupervised MRI-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
Feb 06, 2026Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on multilevel correlation pyramidal optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is avaliable at https://github.com/wjiazheng/MCPO.
GeoLanG: Geometry-Aware Language-Guided Grasping with Unified RGB-D Multimodal Learning
Feb 04, 2026Language-guided grasping has emerged as a promising paradigm for enabling robots to identify and manipulate target objects through natural language instructions, yet it remains highly challenging in cluttered or occluded scenes. Existing methods often rely on multi-stage pipelines that separate object perception and grasping, which leads to limited cross-modal fusion, redundant computation, and poor generalization in cluttered, occluded, or low-texture scenes. To address these limitations, we propose GeoLanG, an end-to-end multi-task framework built upon the CLIP architecture that unifies visual and linguistic inputs into a shared representation space for robust semantic alignment and improved generalization. To enhance target discrimination under occlusion and low-texture conditions, we explore a more effective use of depth information through the Depth-guided Geometric Module (DGGM), which converts depth into explicit geometric priors and injects them into the attention mechanism without additional computational overhead. In addition, we propose Adaptive Dense Channel Integration, which adaptively balances the contributions of multi-layer features to produce more discriminative and generalizable visual representations. Extensive experiments on the OCID-VLG dataset, as well as in both simulation and real-world hardware, demonstrate that GeoLanG enables precise and robust language-guided grasping in complex, cluttered environments, paving the way toward more reliable multimodal robotic manipulation in real-world human-centric settings.
A Step to Decouple Optimization in 3DGS
Jan 26, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.
Gaussian Primitive Optimized Deformable Retinal Image Registration
Aug 23, 2025



Deformable retinal image registration is notoriously difficult due to large homogeneous regions and sparse but critical vascular features, which cause limited gradient signals in standard learning-based frameworks. In this paper, we introduce Gaussian Primitive Optimization (GPO), a novel iterative framework that performs structured message passing to overcome these challenges. After an initial coarse alignment, we extract keypoints at salient anatomical structures (e.g., major vessels) to serve as a minimal set of descriptor-based control nodes (DCN). Each node is modelled as a Gaussian primitive with trainable position, displacement, and radius, thus adapting its spatial influence to local deformation scales. A K-Nearest Neighbors (KNN) Gaussian interpolation then blends and propagates displacement signals from these information-rich nodes to construct a globally coherent displacement field; focusing interpolation on the top (K) neighbors reduces computational overhead while preserving local detail. By strategically anchoring nodes in high-gradient regions, GPO ensures robust gradient flow, mitigating vanishing gradient signal in textureless areas. The framework is optimized end-to-end via a multi-term loss that enforces both keypoint consistency and intensity alignment. Experiments on the FIRE dataset show that GPO reduces the target registration error from 6.2\,px to ~2.4\,px and increases the AUC at 25\,px from 0.770 to 0.938, substantially outperforming existing methods. The source code can be accessed via https://github.com/xintian-99/GPOreg.
ShorterBetter: Guiding Reasoning Models to Find Optimal Inference Length for Efficient Reasoning
Apr 30, 2025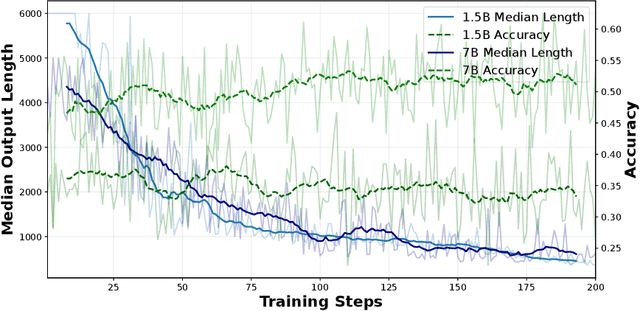
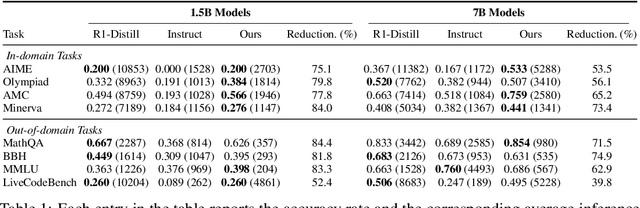
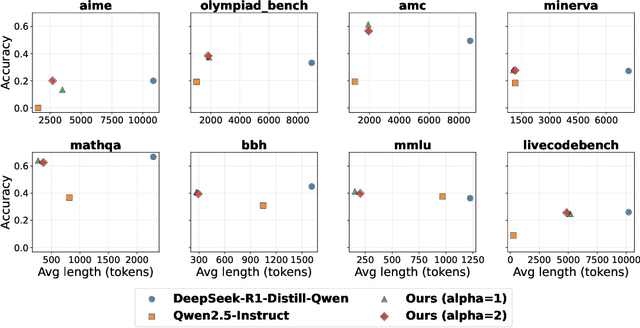
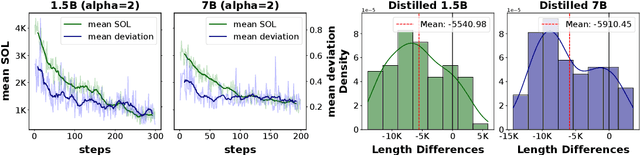
Reasoning models such as OpenAI o3 and DeepSeek-R1 have demonstrated strong performance on reasoning-intensive tasks through extended Chain-of-Thought (CoT) prompting. While longer reasoning traces can facilitate a more thorough exploration of solution paths for complex problems, researchers have observed that these models often "overthink", leading to inefficient inference. In this paper, we introduce ShorterBetter, a simple yet effective reinforcement learning methed that enables reasoning language models to discover their own optimal CoT lengths without human intervention. By sampling multiple outputs per problem and defining the Sample Optimal Length (SOL) as the shortest correct response among all the outputs, our method dynamically guides the model toward optimal inference lengths. Applied to the DeepSeek-Distill-Qwen-1.5B model, ShorterBetter achieves up to an 80% reduction in output length on both in-domain and out-of-domain reasoning tasks while maintaining accuracy. Our analysis shows that overly long reasoning traces often reflect loss of reasoning direction, and thus suggests that the extended CoT produced by reasoning models is highly compressible.
Reproducibility Assessment of Magnetic Resonance Spectroscopy of Pregenual Anterior Cingulate Cortex across Sessions and Vendors via the Cloud Computing Platform CloudBrain-MRS
Mar 06, 2025



Given the need to elucidate the mechanisms underlying illnesses and their treatment, as well as the lack of harmonization of acquisition and post-processing protocols among different magnetic resonance system vendors, this work is to determine if metabolite concentrations obtained from different sessions, machine models and even different vendors of 3 T scanners can be highly reproducible and be pooled for diagnostic analysis, which is very valuable for the research of rare diseases. Participants underwent magnetic resonance imaging (MRI) scanning once on two separate days within one week (one session per day, each session including two proton magnetic resonance spectroscopy (1H-MRS) scans with no more than a 5-minute interval between scans (no off-bed activity)) on each machine. were analyzed for reliability of within- and between- sessions using the coefficient of variation (CV) and intraclass correlation coefficient (ICC), and for reproducibility of across the machines using correlation coefficient. As for within- and between- session, all CV values for a group of all the first or second scans of a session, or for a session were almost below 20%, and most of the ICCs for metabolites range from moderate (0.4-0.59) to excellent (0.75-1), indicating high data reliability. When it comes to the reproducibility across the three scanners, all Pearson correlation coefficients across the three machines approached 1 with most around 0.9, and majority demonstrated statistical significance (P<0.01). Additionally, the intra-vendor reproducibility was greater than the inter-vendor ones.