 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
Jan 19, 2026Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.
An artificially intelligent magnetic resonance spectroscopy quantification method: Comparison between QNet and LCModel on the cloud computing platform CloudBrain-MRS
Mar 06, 2025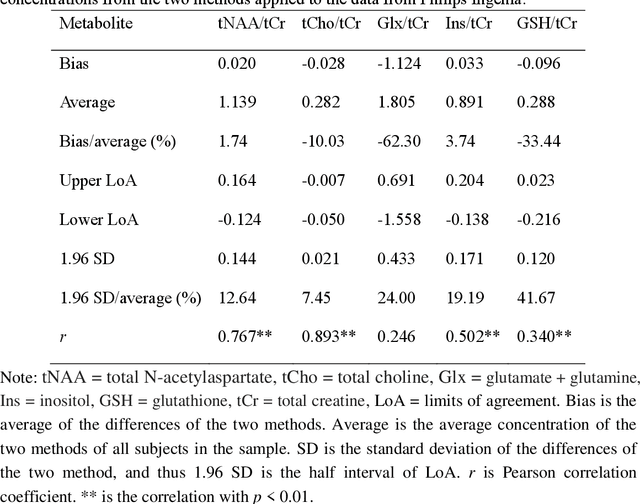

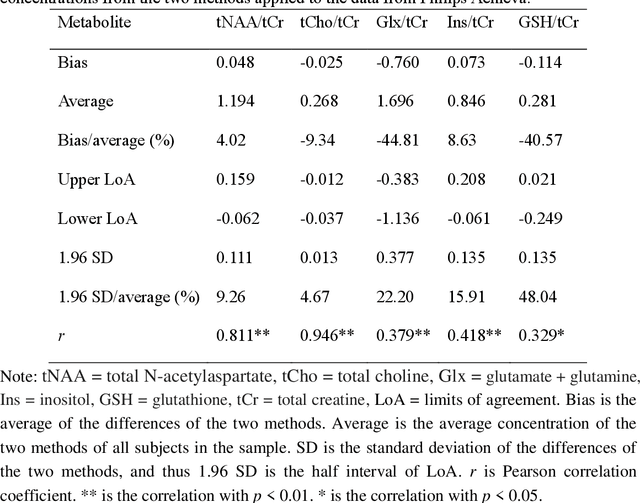
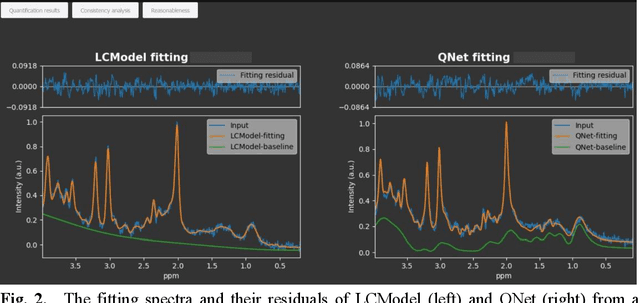
Objctives: This work aimed to statistically compare the metabolite quantification of human brain magnetic resonance spectroscopy (MRS) between the deep learning method QNet and the classical method LCModel through an easy-to-use intelligent cloud computing platform CloudBrain-MRS. Materials and Methods: In this retrospective study, two 3 T MRI scanners Philips Ingenia and Achieva collected 61 and 46 in vivo 1H magnetic resonance (MR) spectra of healthy participants, respectively, from the brain region of pregenual anterior cingulate cortex from September to October 2021. The analyses of Bland-Altman, Pearson correlation and reasonability were performed to assess the degree of agreement, linear correlation and reasonability between the two quantification methods. Results: Fifteen healthy volunteers (12 females and 3 males, age range: 21-35 years, mean age/standard deviation = 27.4/3.9 years) were recruited. The analyses of Bland-Altman, Pearson correlation and reasonability showed high to good consistency and very strong to moderate correlation between the two methods for quantification of total N-acetylaspartate (tNAA), total choline (tCho), and inositol (Ins) (relative half interval of limits of agreement = 3.04%, 9.3%, and 18.5%, respectively; Pearson correlation coefficient r = 0.775, 0.927, and 0.469, respectively). In addition, quantification results of QNet are more likely to be closer to the previous reported average values than those of LCModel. Conclusion: There were high or good degrees of consistency between the quantification results of QNet and LCModel for tNAA, tCho, and Ins, and QNet generally has more reasonable quantification than LCModel.
Reproducibility Assessment of Magnetic Resonance Spectroscopy of Pregenual Anterior Cingulate Cortex across Sessions and Vendors via the Cloud Computing Platform CloudBrain-MRS
Mar 06, 2025



Given the need to elucidate the mechanisms underlying illnesses and their treatment, as well as the lack of harmonization of acquisition and post-processing protocols among different magnetic resonance system vendors, this work is to determine if metabolite concentrations obtained from different sessions, machine models and even different vendors of 3 T scanners can be highly reproducible and be pooled for diagnostic analysis, which is very valuable for the research of rare diseases. Participants underwent magnetic resonance imaging (MRI) scanning once on two separate days within one week (one session per day, each session including two proton magnetic resonance spectroscopy (1H-MRS) scans with no more than a 5-minute interval between scans (no off-bed activity)) on each machine. were analyzed for reliability of within- and between- sessions using the coefficient of variation (CV) and intraclass correlation coefficient (ICC), and for reproducibility of across the machines using correlation coefficient. As for within- and between- session, all CV values for a group of all the first or second scans of a session, or for a session were almost below 20%, and most of the ICCs for metabolites range from moderate (0.4-0.59) to excellent (0.75-1), indicating high data reliability. When it comes to the reproducibility across the three scanners, all Pearson correlation coefficients across the three machines approached 1 with most around 0.9, and majority demonstrated statistical significance (P<0.01). Additionally, the intra-vendor reproducibility was greater than the inter-vendor ones.
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Feb 27, 2024For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known "facts" that are relevant to the input prompt from the LLM. And then it asks the model to "reflect" over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment
Feb 25, 2024We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and unstable to fine-tune large foundation models using reinforcement learning (RL), and the multi-dimensionality, heterogeneity, and conflicting nature of human preferences further complicate the alignment process. In this paper, we introduce Rewards-in-Context (RiC), which conditions the response of a foundation model on multiple rewards in its prompt context and applies supervised fine-tuning for alignment. The salient features of RiC are simplicity and adaptivity, as it only requires supervised fine-tuning of a single foundation model and supports dynamic adjustment for user preferences during inference time. Inspired by the analytical solution of an abstracted convex optimization problem, our dynamic inference-time adjustment method approaches the Pareto-optimal solution for multiple objectives. Empirical evidence demonstrates the efficacy of our method in aligning both Large Language Models (LLMs) and diffusion models to accommodate diverse rewards with only around 10% GPU hours compared with multi-objective RL baseline.
MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning
Nov 15, 2023



With the rapid development of large language models (LLMs) and their integration into large multimodal models (LMMs), there has been impressive progress in zero-shot completion of user-oriented vision-language tasks. However, a gap remains in the domain of chart image understanding due to the distinct abstract components in charts. To address this, we introduce a large-scale MultiModal Chart Instruction (MMC-Instruction) dataset comprising 600k instances supporting diverse tasks and chart types. Leveraging this data, we develop MultiModal Chart Assistant (MMCA), an LMM that achieves state-of-the-art performance on existing chart QA benchmarks. Recognizing the need for a comprehensive evaluation of LMM chart understanding, we also propose a MultiModal Chart Benchmark (MMC-Benchmark), a comprehensive human-annotated benchmark with 9 distinct tasks evaluating reasoning capabilities over charts. Extensive experiments on MMC-Benchmark reveal the limitations of existing LMMs on correctly interpreting charts, even for the most recent GPT-4V model. Our work provides an instruction-tuning methodology and benchmark to advance multimodal understanding of charts.
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Sep 30, 2023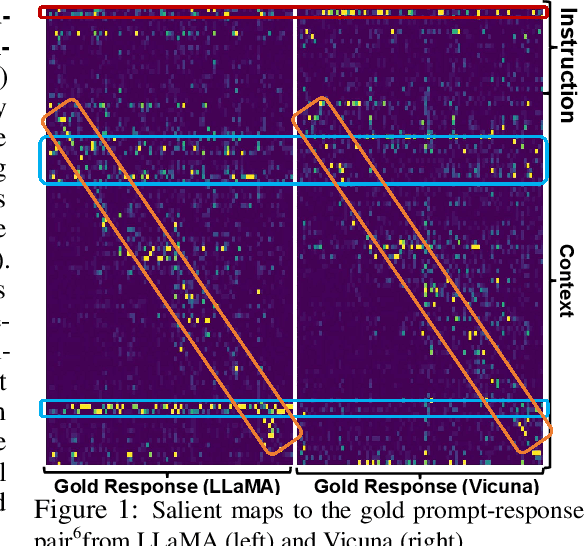
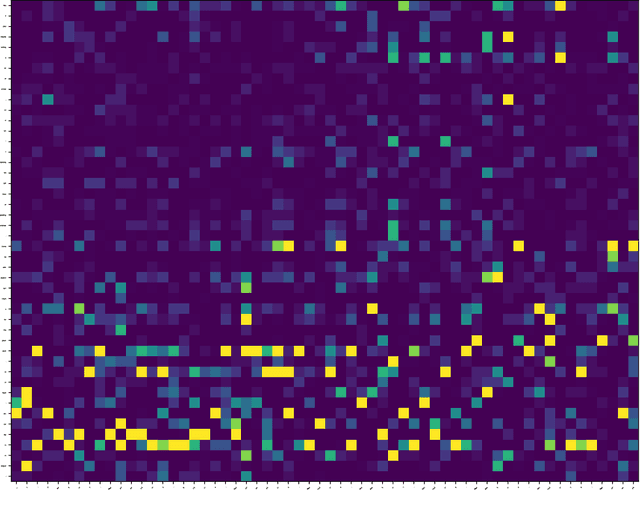
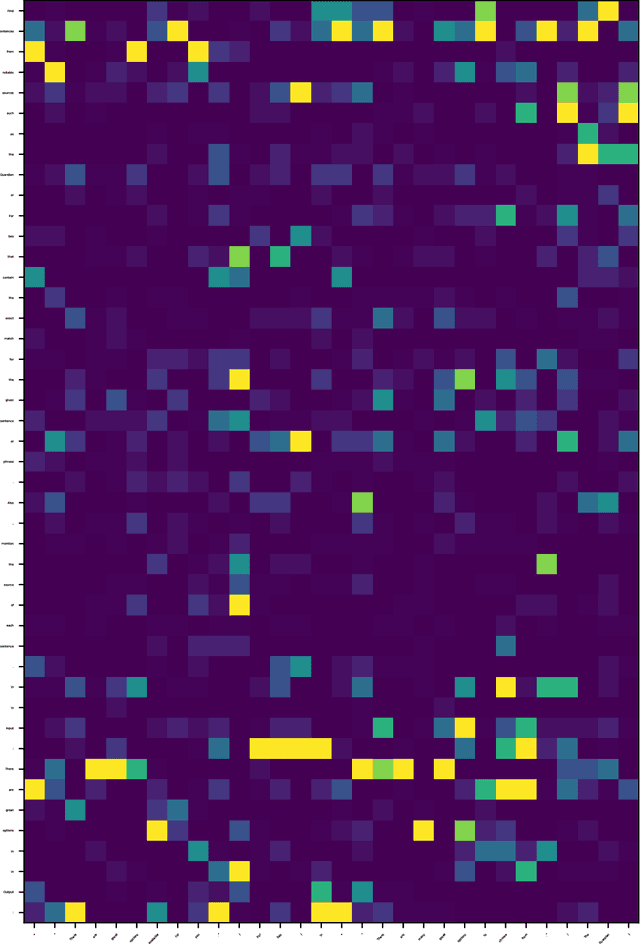

Large Language Models (LLMs) have achieved remarkable success, demonstrating powerful instruction-following capabilities across diverse tasks. Instruction fine-tuning is critical in enabling LLMs to align with user intentions and effectively follow instructions. In this work, we investigate how instruction fine-tuning modifies pre-trained models, focusing on two perspectives: instruction recognition and knowledge evolution. To study the behavior shift of LLMs, we employ a suite of local and global explanation methods, including a gradient-based approach for input-output attribution and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. Our findings reveal three significant impacts of instruction fine-tuning: 1) It empowers LLMs to better recognize the instruction parts from user prompts, thereby facilitating high-quality response generation and addressing the ``lost-in-the-middle'' issue observed in pre-trained models; 2) It aligns the knowledge stored in feed-forward layers with user-oriented tasks, exhibiting minimal shifts across linguistic levels. 3) It facilitates the learning of word-word relations with instruction verbs through the self-attention mechanism, particularly in the lower and middle layers, indicating enhanced recognition of instruction words. These insights contribute to a deeper understanding of the behavior shifts in LLMs after instruction fine-tuning and lay the groundwork for future research aimed at interpreting and optimizing LLMs for various applications. We will release our code and data soon.
Skills-in-Context Prompting: Unlocking Compositionality in Large Language Models
Aug 14, 2023We consider the problem of eliciting compositional generalization capabilities in large language models (LLMs) with a novel type of prompting strategy. Compositional generalization empowers the LLMs to solve problems that are harder than the ones they have seen (i.e., easy-to-hard generalization), which is a critical reasoning capability of human-like intelligence. However, even the current state-of-the-art LLMs still struggle with this form of reasoning. To bridge this gap, we propose skills-in-context (SKiC) prompting, which instructs LLMs how to compose basic skills to resolve more complex problems. We find that it is crucial to demonstrate both the skills and the compositional examples within the same prompting context. With as few as two examplars, our SKiC prompting initiates strong synergies between skills and their composition capabilities. Notably, it empowers LLMs to solve unseen problems that require innovative skill compositions, achieving near-perfect generalization on a broad range of challenging compositionality tasks. Intriguingly, SKiC prompting unlocks the latent potential of LLMs, enabling them to leverage pre-existing internal skills acquired during earlier pre-training stages, even when these skills are not explicitly presented in the prompting context. This results in the capability of LLMs to solve unseen complex problems by activating and composing internal competencies. With such prominent features, SKiC prompting is able to achieve state-of-the-art performance on challenging mathematical reasoning benchmarks (e.g., MATH).
Thrust: Adaptively Propels Large Language Models with External Knowledge
Jul 19, 2023Although large-scale pre-trained language models (PTLMs) are shown to encode rich knowledge in their model parameters, the inherent knowledge in PTLMs can be opaque or static, making external knowledge necessary. However, the existing information retrieval techniques could be costly and may even introduce noisy and sometimes misleading knowledge. To address these challenges, we propose the instance-level adaptive propulsion of external knowledge (IAPEK), where we only conduct the retrieval when necessary. To achieve this goal, we propose measuring whether a PTLM contains enough knowledge to solve an instance with a novel metric, Thrust, which leverages the representation distribution of a small number of seen instances. Extensive experiments demonstrate that thrust is a good measurement of PTLM models' instance-level knowledgeability. Moreover, we can achieve significantly higher cost-efficiency with the Thrust score as the retrieval indicator than the naive usage of external knowledge on 88% of the evaluated tasks with 26% average performance improvement. Such findings shed light on the real-world practice of knowledge-enhanced LMs with a limited knowledge-seeking budget due to computation latency or costs.
A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation
Jul 08, 2023Recently developed large language models have achieved remarkable success in generating fluent and coherent text. However, these models often tend to 'hallucinate' which critically hampers their reliability. In this work, we address this crucial problem and propose an approach that actively detects and mitigates hallucinations during the generation process. Specifically, we first identify the candidates of potential hallucination leveraging the model's logit output values, check their correctness through a validation procedure, mitigate the detected hallucinations, and then continue with the generation process. Through extensive experiments with the 'article generation task', we first demonstrate the individual efficacy of our detection and mitigation techniques. Specifically, the detection technique achieves a recall of 88% and the mitigation technique successfully mitigates 57.6% of the correctly detected hallucinations. Importantly, our mitigation technique does not introduce new hallucinations even in the case of incorrectly detected hallucinations, i.e., false positives. Then, we show that the proposed active detection and mitigation approach successfully reduces the hallucinations of the GPT-3 model from 47.5% to 14.5% on average. In summary, our work contributes to improving the reliability and trustworthiness of large language models, a crucial step en route to enabling their widespread adoption in real-world applications.