 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating CoT Monitorability in Large Reasoning Models
Nov 13, 2025



Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex tasks by engaging in extended reasoning before producing final answers. Beyond improving abilities, these detailed reasoning traces also create a new opportunity for AI safety, CoT Monitorability: monitoring potential model misbehavior, such as the use of shortcuts or sycophancy, through their chain-of-thought (CoT) during decision-making. However, two key fundamental challenges arise when attempting to build more effective monitors through CoT analysis. First, as prior research on CoT faithfulness has pointed out, models do not always truthfully represent their internal decision-making in the generated reasoning. Second, monitors themselves may be either overly sensitive or insufficiently sensitive, and can potentially be deceived by models' long, elaborate reasoning traces. In this paper, we present the first systematic investigation of the challenges and potential of CoT monitorability. Motivated by two fundamental challenges we mentioned before, we structure our study around two central perspectives: (i) verbalization: to what extent do LRMs faithfully verbalize the true factors guiding their decisions in the CoT, and (ii) monitor reliability: to what extent can misbehavior be reliably detected by a CoT-based monitor? Specifically, we provide empirical evidence and correlation analyses between verbalization quality, monitor reliability, and LLM performance across mathematical, scientific, and ethical domains. Then we further investigate how different CoT intervention methods, designed to improve reasoning efficiency or performance, will affect monitoring effectiveness. Finally, we propose MoME, a new paradigm in which LLMs monitor other models' misbehavior through their CoT and provide structured judgments along with supporting evidence.
AutoSCORE: Enhancing Automated Scoring with Multi-Agent Large Language Models via Structured Component Recognition
Sep 26, 2025


Automated scoring plays a crucial role in education by reducing the reliance on human raters, offering scalable and immediate evaluation of student work. While large language models (LLMs) have shown strong potential in this task, their use as end-to-end raters faces challenges such as low accuracy, prompt sensitivity, limited interpretability, and rubric misalignment. These issues hinder the implementation of LLM-based automated scoring in assessment practice. To address the limitations, we propose AutoSCORE, a multi-agent LLM framework enhancing automated scoring via rubric-aligned Structured COmponent REcognition. With two agents, AutoSCORE first extracts rubric-relevant components from student responses and encodes them into a structured representation (i.e., Scoring Rubric Component Extraction Agent), which is then used to assign final scores (i.e., Scoring Agent). This design ensures that model reasoning follows a human-like grading process, enhancing interpretability and robustness. We evaluate AutoSCORE on four benchmark datasets from the ASAP benchmark, using both proprietary and open-source LLMs (GPT-4o, LLaMA-3.1-8B, and LLaMA-3.1-70B). Across diverse tasks and rubrics, AutoSCORE consistently improves scoring accuracy, human-machine agreement (QWK, correlations), and error metrics (MAE, RMSE) compared to single-agent baselines, with particularly strong benefits on complex, multi-dimensional rubrics, and especially large relative gains on smaller LLMs. These results demonstrate that structured component recognition combined with multi-agent design offers a scalable, reliable, and interpretable solution for automated scoring.
Is Long-to-Short a Free Lunch? Investigating Inconsistency and Reasoning Efficiency in LRMs
Jun 24, 2025Large Reasoning Models (LRMs) have achieved remarkable performance on complex tasks by engaging in extended reasoning before producing final answers, yet this strength introduces the risk of overthinking, where excessive token generation occurs even for simple tasks. While recent work in efficient reasoning seeks to reduce reasoning length while preserving accuracy, it remains unclear whether such optimization is truly a free lunch. Drawing on the intuition that compressing reasoning may reduce the robustness of model responses and lead models to omit key reasoning steps, we investigate whether efficient reasoning strategies introduce behavioral inconsistencies. To systematically assess this, we introduce $ICBENCH$, a benchmark designed to measure inconsistency in LRMs across three dimensions: inconsistency across task settings (ITS), inconsistency between training objectives and learned behavior (TR-LB), and inconsistency between internal reasoning and self-explanations (IR-SE). Applying $ICBENCH$ to a range of open-source LRMs, we find that while larger models generally exhibit greater consistency than smaller ones, they all display widespread "scheming" behaviors, including self-disagreement, post-hoc rationalization, and the withholding of reasoning cues. Crucially, our results demonstrate that efficient reasoning strategies such as No-Thinking and Simple Token-Budget consistently increase all three defined types of inconsistency. These findings suggest that although efficient reasoning enhances token-level efficiency, further investigation is imperative to ascertain whether it concurrently introduces the risk of models evading effective supervision.
Denoising Concept Vectors with Sparse Autoencoders for Improved Language Model Steering
May 21, 2025Linear Concept Vectors have proven effective for steering large language models (LLMs). While existing approaches like linear probing and difference-in-means derive these vectors from LLM hidden representations, diverse data introduces noises (i.e., irrelevant features) that challenge steering robustness. To address this, we propose Sparse Autoencoder-Denoised Concept Vectors (SDCV), which uses Sparse Autoencoders to filter out noisy features from hidden representations. When applied to linear probing and difference-in-means, our method improves their steering success rates. We validate our noise hypothesis through counterfactual experiments and feature visualizations.
Artificial Intelligence Bias on English Language Learners in Automatic Scoring
May 15, 2025This study investigated potential scoring biases and disparities toward English Language Learners (ELLs) when using automatic scoring systems for middle school students' written responses to science assessments. We specifically focus on examining how unbalanced training data with ELLs contributes to scoring bias and disparities. We fine-tuned BERT with four datasets: responses from (1) ELLs, (2) non-ELLs, (3) a mixed dataset reflecting the real-world proportion of ELLs and non-ELLs (unbalanced), and (4) a balanced mixed dataset with equal representation of both groups. The study analyzed 21 assessment items: 10 items with about 30,000 ELL responses, five items with about 1,000 ELL responses, and six items with about 200 ELL responses. Scoring accuracy (Acc) was calculated and compared to identify bias using Friedman tests. We measured the Mean Score Gaps (MSGs) between ELLs and non-ELLs and then calculated the differences in MSGs generated through both the human and AI models to identify the scoring disparities. We found that no AI bias and distorted disparities between ELLs and non-ELLs were found when the training dataset was large enough (ELL = 30,000 and ELL = 1,000), but concerns could exist if the sample size is limited (ELL = 200).
Beyond Input Activations: Identifying Influential Latents by Gradient Sparse Autoencoders
May 12, 2025Sparse Autoencoders (SAEs) have recently emerged as powerful tools for interpreting and steering the internal representations of large language models (LLMs). However, conventional approaches to analyzing SAEs typically rely solely on input-side activations, without considering the causal influence between each latent feature and the model's output. This work is built on two key hypotheses: (1) activated latents do not contribute equally to the construction of the model's output, and (2) only latents with high causal influence are effective for model steering. To validate these hypotheses, we propose Gradient Sparse Autoencoder (GradSAE), a simple yet effective method that identifies the most influential latents by incorporating output-side gradient information.
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
Mar 07, 2025Large Language Models (LLMs) have revolutionized natural language processing, yet their internal mechanisms remain largely opaque. Recently, mechanistic interpretability has attracted significant attention from the research community as a means to understand the inner workings of LLMs. Among various mechanistic interpretability approaches, Sparse Autoencoders (SAEs) have emerged as a particularly promising method due to their ability to disentangle the complex, superimposed features within LLMs into more interpretable components. This paper presents a comprehensive examination of SAEs as a promising approach to interpreting and understanding LLMs. We provide a systematic overview of SAE principles, architectures, and applications specifically tailored for LLM analysis, covering theoretical foundations, implementation strategies, and recent developments in sparsity mechanisms. We also explore how SAEs can be leveraged to explain the internal workings of LLMs, steer model behaviors in desired directions, and develop more transparent training methodologies for future models. Despite the challenges that remain around SAE implementation and scaling, they continue to provide valuable tools for understanding the internal mechanisms of large language models.
Interpreting and Steering LLMs with Mutual Information-based Explanations on Sparse Autoencoders
Feb 21, 2025
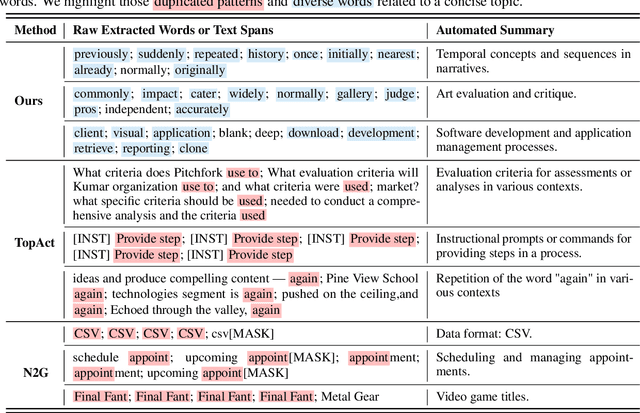
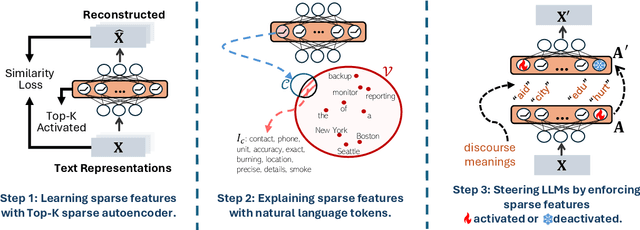
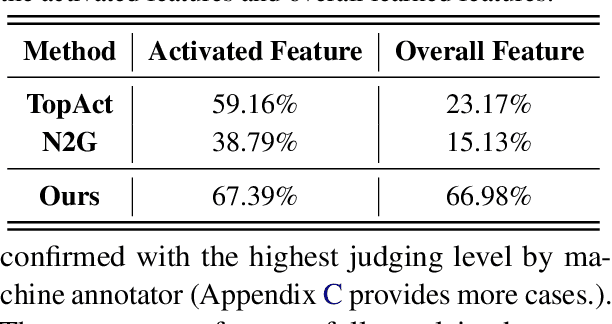
Large language models (LLMs) excel at handling human queries, but they can occasionally generate flawed or unexpected responses. Understanding their internal states is crucial for understanding their successes, diagnosing their failures, and refining their capabilities. Although sparse autoencoders (SAEs) have shown promise for interpreting LLM internal representations, limited research has explored how to better explain SAE features, i.e., understanding the semantic meaning of features learned by SAE. Our theoretical analysis reveals that existing explanation methods suffer from the frequency bias issue, where they emphasize linguistic patterns over semantic concepts, while the latter is more critical to steer LLM behaviors. To address this, we propose using a fixed vocabulary set for feature interpretations and designing a mutual information-based objective, aiming to better capture the semantic meaning behind these features. We further propose two runtime steering strategies that adjust the learned feature activations based on their corresponding explanations. Empirical results show that, compared to baselines, our method provides more discourse-level explanations and effectively steers LLM behaviors to defend against jailbreak attacks. These findings highlight the value of explanations for steering LLM behaviors in downstream applications. We will release our code and data once accepted.
Self-Regularization with Latent Space Explanations for Controllable LLM-based Classification
Feb 19, 2025Modern text classification methods heavily rely on contextual embeddings from large language models (LLMs). Compared to human-engineered features, these embeddings provide automatic and effective representations for classification model training. However, they also introduce a challenge: we lose the ability to manually remove unintended features, such as sensitive or task-irrelevant features, to guarantee regulatory compliance or improve the generalizability of classification models. This limitation arises because LLM embeddings are opaque and difficult to interpret. In this paper, we propose a novel framework to identify and regularize unintended features in the LLM latent space. Specifically, we first pre-train a sparse autoencoder (SAE) to extract interpretable features from LLM latent spaces. To ensure the SAE can capture task-specific features, we further fine-tune it on task-specific datasets. In training the classification model, we propose a simple and effective regularizer, by minimizing the similarity between the classifier weights and the identified unintended feature, to remove the impacts of these unintended features toward classification. We evaluate the proposed framework on three real-world tasks, including toxic chat detection, reward modeling, and disease diagnosis. Results show that the proposed framework can significantly improve the classifier's generalizability by regularizing those features that are not semantically correlated to each task. This work pioneers controllable text classification on LLM latent spaces by leveraging interpreted features to address generalizability, fairness, and privacy challenges. We will release our code and data once accepted.
LMOD: A Large Multimodal Ophthalmology Dataset and Benchmark for Large Vision-Language Models
Oct 02, 2024



Ophthalmology relies heavily on detailed image analysis for diagnosis and treatment planning. While large vision-language models (LVLMs) have shown promise in understanding complex visual information, their performance on ophthalmology images remains underexplored. We introduce LMOD, a dataset and benchmark for evaluating LVLMs on ophthalmology images, covering anatomical understanding, diagnostic analysis, and demographic extraction. LMODincludes 21,993 images spanning optical coherence tomography, scanning laser ophthalmoscopy, eye photos, surgical scenes, and color fundus photographs. We benchmark 13 state-of-the-art LVLMs and find that they are far from perfect for comprehending ophthalmology images. Models struggle with diagnostic analysis and demographic extraction, reveal weaknesses in spatial reasoning, diagnostic analysis, handling out-of-domain queries, and safeguards for handling biomarkers of ophthalmology images.