 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM Reasoning through Interpretable Role-Playing Steering
Jun 09, 2025



Role-playing has emerged as an effective technique for enhancing the reasoning capabilities of large language models (LLMs). However, existing methods primarily rely on prompt engineering, which often lacks stability and interpretability. In this paper, we introduce Sparse Autoencoder Role-Playing Steering (SRPS), a novel framework that identifies and manipulates internal model features associated with role-playing behavior. Our approach extracts latent representations from role-play prompts, selects the most relevant features based on activation patterns, and constructs a steering vector that can be injected into the model's residual stream with controllable intensity. Our method enables fine-grained control over role-specific behavior and offers insights into how role information influences internal model activations. Extensive experiments across various reasoning benchmarks and model sizes demonstrate consistent performance gains. Notably, in the zero-shot chain-of-thought (CoT) setting, the accuracy of Llama3.1-8B on CSQA improves from 31.86% to 39.80%, while Gemma2-9B on SVAMP increases from 37.50% to 45.10%. These results highlight the potential of SRPS to enhance reasoning ability in LLMs, providing better interpretability and stability compared to traditional prompt-based role-playing.
Beyond Input Activations: Identifying Influential Latents by Gradient Sparse Autoencoders
May 12, 2025Sparse Autoencoders (SAEs) have recently emerged as powerful tools for interpreting and steering the internal representations of large language models (LLMs). However, conventional approaches to analyzing SAEs typically rely solely on input-side activations, without considering the causal influence between each latent feature and the model's output. This work is built on two key hypotheses: (1) activated latents do not contribute equally to the construction of the model's output, and (2) only latents with high causal influence are effective for model steering. To validate these hypotheses, we propose Gradient Sparse Autoencoder (GradSAE), a simple yet effective method that identifies the most influential latents by incorporating output-side gradient information.
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
Mar 07, 2025Large Language Models (LLMs) have revolutionized natural language processing, yet their internal mechanisms remain largely opaque. Recently, mechanistic interpretability has attracted significant attention from the research community as a means to understand the inner workings of LLMs. Among various mechanistic interpretability approaches, Sparse Autoencoders (SAEs) have emerged as a particularly promising method due to their ability to disentangle the complex, superimposed features within LLMs into more interpretable components. This paper presents a comprehensive examination of SAEs as a promising approach to interpreting and understanding LLMs. We provide a systematic overview of SAE principles, architectures, and applications specifically tailored for LLM analysis, covering theoretical foundations, implementation strategies, and recent developments in sparsity mechanisms. We also explore how SAEs can be leveraged to explain the internal workings of LLMs, steer model behaviors in desired directions, and develop more transparent training methodologies for future models. Despite the challenges that remain around SAE implementation and scaling, they continue to provide valuable tools for understanding the internal mechanisms of large language models.
Large Vision-Language Model Alignment and Misalignment: A Survey Through the Lens of Explainability
Jan 02, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in processing both visual and textual information. However, the critical challenge of alignment between visual and linguistic representations is not fully understood. This survey presents a comprehensive examination of alignment and misalignment in LVLMs through an explainability lens. We first examine the fundamentals of alignment, exploring its representational and behavioral aspects, training methodologies, and theoretical foundations. We then analyze misalignment phenomena across three semantic levels: object, attribute, and relational misalignment. Our investigation reveals that misalignment emerges from challenges at multiple levels: the data level, the model level, and the inference level. We provide a comprehensive review of existing mitigation strategies, categorizing them into parameter-frozen and parameter-tuning approaches. Finally, we outline promising future research directions, emphasizing the need for standardized evaluation protocols and in-depth explainability studies.
Target-driven Attack for Large Language Models
Nov 13, 2024



Current large language models (LLM) provide a strong foundation for large-scale user-oriented natural language tasks. Many users can easily inject adversarial text or instructions through the user interface, thus causing LLM model security challenges like the language model not giving the correct answer. Although there is currently a large amount of research on black-box attacks, most of these black-box attacks use random and heuristic strategies. It is unclear how these strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we propose our target-driven black-box attack method to maximize the KL divergence between the conditional probabilities of the clean text and the attack text to redefine the attack's goal. We transform the distance maximization problem into two convex optimization problems based on the attack goal to solve the attack text and estimate the covariance. Furthermore, the projected gradient descent algorithm solves the vector corresponding to the attack text. Our target-driven black-box attack approach includes two attack strategies: token manipulation and misinformation attack. Experimental results on multiple Large Language Models and datasets demonstrate the effectiveness of our attack method.
Exploring the Alignment Landscape: LLMs and Geometric Deep Models in Protein Representation
Nov 08, 2024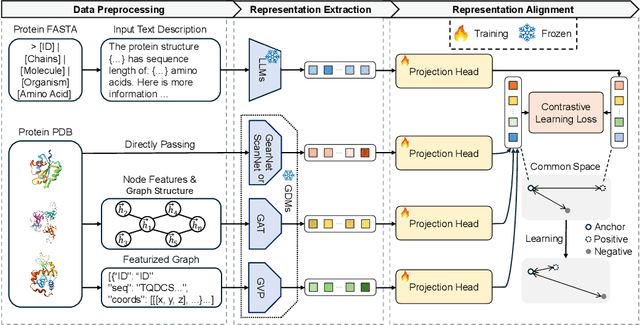

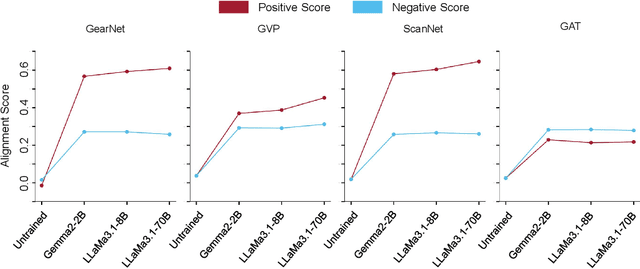

Latent representation alignment has become a foundational technique for constructing multimodal large language models (MLLM) by mapping embeddings from different modalities into a shared space, often aligned with the embedding space of large language models (LLMs) to enable effective cross-modal understanding. While preliminary protein-focused MLLMs have emerged, they have predominantly relied on heuristic approaches, lacking a fundamental understanding of optimal alignment practices across representations. In this study, we explore the alignment of multimodal representations between LLMs and Geometric Deep Models (GDMs) in the protein domain. We comprehensively evaluate three state-of-the-art LLMs (Gemma2-2B, LLaMa3.1-8B, and LLaMa3.1-70B) with four protein-specialized GDMs (GearNet, GVP, ScanNet, GAT). Our work examines alignment factors from both model and protein perspectives, identifying challenges in current alignment methodologies and proposing strategies to improve the alignment process. Our key findings reveal that GDMs incorporating both graph and 3D structural information align better with LLMs, larger LLMs demonstrate improved alignment capabilities, and protein rarity significantly impacts alignment performance. We also find that increasing GDM embedding dimensions, using two-layer projection heads, and fine-tuning LLMs on protein-specific data substantially enhance alignment quality. These strategies offer potential enhancements to the performance of protein-related multimodal models. Our code and data are available at https://github.com/Tizzzzy/LLM-GDM-alignment.
Comparative Analysis of Demonstration Selection Algorithms for LLM In-Context Learning
Oct 30, 2024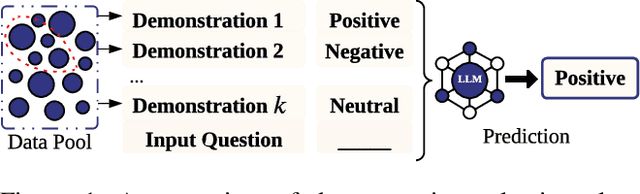



In-context learning can help Large Language Models (LLMs) to adapt new tasks without additional training. However, this performance heavily depends on the quality of the demonstrations, driving research into effective demonstration selection algorithms to optimize this process. These algorithms assist users in selecting the best $k$ input-label pairs (demonstration examples) based on a given test input, enabling LLMs to in-context learn the relationship between the provided examples and the test inputs. Despite all the proposed demonstration selection algorithms, their efficiency and effectiveness remain unclear. This lack of clarity make it difficult to apply these algorithms in real-world scenarios and poses challenges for future research aimed at developing improved methods. This paper revisits six proposed algorithms, evaluating them on five datasets from both efficiency and effectiveness perspectives. Our experiments reveal significant variations in algorithm performance across different tasks, with some methods struggling to outperform random selection in certain scenarios. We also find that increasing the number of demonstrations does not always lead to better performance, and that there are often trade-offs between accuracy and computational efficiency. Our code is available at https://github.com/Tizzzzy/Demonstration_Selection_Overview.
LawLLM: Law Large Language Model for the US Legal System
Jul 27, 2024



In the rapidly evolving field of legal analytics, finding relevant cases and accurately predicting judicial outcomes are challenging because of the complexity of legal language, which often includes specialized terminology, complex syntax, and historical context. Moreover, the subtle distinctions between similar and precedent cases require a deep understanding of legal knowledge. Researchers often conflate these concepts, making it difficult to develop specialized techniques to effectively address these nuanced tasks. In this paper, we introduce the Law Large Language Model (LawLLM), a multi-task model specifically designed for the US legal domain to address these challenges. LawLLM excels at Similar Case Retrieval (SCR), Precedent Case Recommendation (PCR), and Legal Judgment Prediction (LJP). By clearly distinguishing between precedent and similar cases, we provide essential clarity, guiding future research in developing specialized strategies for these tasks. We propose customized data preprocessing techniques for each task that transform raw legal data into a trainable format. Furthermore, we also use techniques such as in-context learning (ICL) and advanced information retrieval methods in LawLLM. The evaluation results demonstrate that LawLLM consistently outperforms existing baselines in both zero-shot and few-shot scenarios, offering unparalleled multi-task capabilities and filling critical gaps in the legal domain.
Knowledge Graph Large Language Model for Link Prediction
Mar 19, 2024



The task of predicting multiple links within knowledge graphs (KGs) stands as a challenge in the field of knowledge graph analysis, a challenge increasingly resolvable due to advancements in natural language processing (NLP) and KG embedding techniques. This paper introduces a novel methodology, the Knowledge Graph Large Language Model Framework (KG-LLM), which leverages pivotal NLP paradigms, including chain-of-thought (CoT) prompting and in-context learning (ICL), to enhance multi-hop link prediction in KGs. By converting the KG to a CoT prompt, our framework is designed to discern and learn the latent representations of entities and their interrelations. To show the efficacy of the KG-LLM Framework, we fine-tune three leading Large Language Models (LLMs) within this framework, employing both non-ICL and ICL tasks for a comprehensive evaluation. Further, we explore the framework's potential to provide LLMs with zero-shot capabilities for handling previously unseen prompts. Our experimental findings discover that integrating ICL and CoT not only augments the performance of our approach but also significantly boosts the models' generalization capacity, thereby ensuring more precise predictions in unfamiliar scenarios.
Generative Models and Connected and Automated Vehicles: A Survey in Exploring the Intersection of Transportation and AI
Mar 14, 2024This report investigates the history and impact of Generative Models and Connected and Automated Vehicles (CAVs), two groundbreaking forces pushing progress in technology and transportation. By focusing on the application of generative models within the context of CAVs, the study aims to unravel how this integration could enhance predictive modeling, simulation accuracy, and decision-making processes in autonomous vehicles. This thesis discusses the benefits and challenges of integrating generative models and CAV technology in transportation. It aims to highlight the progress made, the remaining obstacles, and the potential for advancements in safety and innovation.