 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailing on Bias Mitigation: Investigating Why Predictive Models Struggle with Government Data
Jan 21, 2026The potential for bias and unfairness in AI-supporting government services raises ethical and legal concerns. Using crime rate prediction with the Bristol City Council data as a case study, we examine how these issues persist. Rather than auditing real-world deployed systems, our goal is to understand why widely adopted bias mitigation techniques often fail when applied to government data. Our findings reveal that bias mitigation approaches applied to government data are not always effective -- not because of flaws in model architecture or metric selection, but due to the inherent properties of the data itself. Through comparing a set of comprehensive models and fairness methods, our experiments consistently show that the mitigation efforts cannot overcome the embedded unfairness in the data -- further reinforcing that the origin of bias lies in the structure and history of government datasets. We then explore the reasons for the mitigation failures in predictive models on government data and highlight the potential sources of unfairness posed by data distribution shifts, the accumulation of historical bias, and delays in data release. We also discover the limitations of the blind spots in fairness analysis and bias mitigation methods when only targeting a single sensitive feature through a set of intersectional fairness experiments. Although this study is limited to one city, the findings are highly suggestive, which can contribute to an early warning that biases in government data may persist even with standard mitigation methods.
MONICA: Real-Time Monitoring and Calibration of Chain-of-Thought Sycophancy in Large Reasoning Models
Nov 09, 2025Large Reasoning Models (LRMs) suffer from sycophantic behavior, where models tend to agree with users' incorrect beliefs and follow misinformation rather than maintain independent reasoning. This behavior undermines model reliability and poses societal risks. Mitigating LRM sycophancy requires monitoring how this sycophancy emerges during the reasoning trajectory; however, current methods mainly focus on judging based on final answers and correcting them, without understanding how sycophancy develops during reasoning processes. To address this limitation, we propose MONICA, a novel Monitor-guided Calibration framework that monitors and mitigates sycophancy during model inference at the level of reasoning steps, without requiring the model to finish generating its complete answer. MONICA integrates a sycophantic monitor that provides real-time monitoring of sycophantic drift scores during response generation with a calibrator that dynamically suppresses sycophantic behavior when scores exceed predefined thresholds. Extensive experiments across 12 datasets and 3 LRMs demonstrate that our method effectively reduces sycophantic behavior in both intermediate reasoning steps and final answers, yielding robust performance improvements.
TriShGAN: Enhancing Sparsity and Robustness in Multivariate Time Series Counterfactuals Explanation
Nov 09, 2025In decision-making processes, stakeholders often rely on counterfactual explanations, which provide suggestions about what should be changed in the queried instance to alter the outcome of an AI system. However, generating these explanations for multivariate time series presents challenges due to their complex, multi-dimensional nature. Traditional Nearest Unlike Neighbor-based methods typically substitute subsequences in a queried time series with influential subsequences from an NUN, which is not always realistic in real-world scenarios due to the rigid direct substitution. Counterfactual with Residual Generative Adversarial Networks-based methods aim to address this by learning from the distribution of observed data to generate synthetic counterfactual explanations. However, these methods primarily focus on minimizing the cost from the queried time series to the counterfactual explanations and often neglect the importance of distancing the counterfactual explanation from the decision boundary. This oversight can result in explanations that no longer qualify as counterfactual if minor changes occur within the model. To generate a more robust counterfactual explanation, we introduce TriShGAN, under the CounteRGAN framework enhanced by the incorporation of triplet loss. This unsupervised learning approach uses distance metric learning to encourage the counterfactual explanations not only to remain close to the queried time series but also to capture the feature distribution of the instance with the desired outcome, thereby achieving a better balance between minimal cost and robustness. Additionally, we integrate a Shapelet Extractor that strategically selects the most discriminative parts of the high-dimensional queried time series to enhance the sparsity of counterfactual explanation and efficiency of the training process.
Mitigating Degree Bias Adaptively with Hard-to-Learn Nodes in Graph Contrastive Learning
Jun 05, 2025Graph Neural Networks (GNNs) often suffer from degree bias in node classification tasks, where prediction performance varies across nodes with different degrees. Several approaches, which adopt Graph Contrastive Learning (GCL), have been proposed to mitigate this bias. However, the limited number of positive pairs and the equal weighting of all positives and negatives in GCL still lead to low-degree nodes acquiring insufficient and noisy information. This paper proposes the Hardness Adaptive Reweighted (HAR) contrastive loss to mitigate degree bias. It adds more positive pairs by leveraging node labels and adaptively weights positive and negative pairs based on their learning hardness. In addition, we develop an experimental framework named SHARP to extend HAR to a broader range of scenarios. Both our theoretical analysis and experiments validate the effectiveness of SHARP. The experimental results across four datasets show that SHARP achieves better performance against baselines at both global and degree levels.
Fine-Grained Interpretation of Political Opinions in Large Language Models
Jun 05, 2025Studies of LLMs' political opinions mainly rely on evaluations of their open-ended responses. Recent work indicates that there is a misalignment between LLMs' responses and their internal intentions. This motivates us to probe LLMs' internal mechanisms and help uncover their internal political states. Additionally, we found that the analysis of LLMs' political opinions often relies on single-axis concepts, which can lead to concept confounds. In this work, we extend the single-axis to multi-dimensions and apply interpretable representation engineering techniques for more transparent LLM political concept learning. Specifically, we designed a four-dimensional political learning framework and constructed a corresponding dataset for fine-grained political concept vector learning. These vectors can be used to detect and intervene in LLM internals. Experiments are conducted on eight open-source LLMs with three representation engineering techniques. Results show these vectors can disentangle political concept confounds. Detection tasks validate the semantic meaning of the vectors and show good generalization and robustness in OOD settings. Intervention Experiments show these vectors can intervene in LLMs to generate responses with different political leanings.
Beyond Prior Limits: Addressing Distribution Misalignment in Particle Filtering
Jan 30, 2025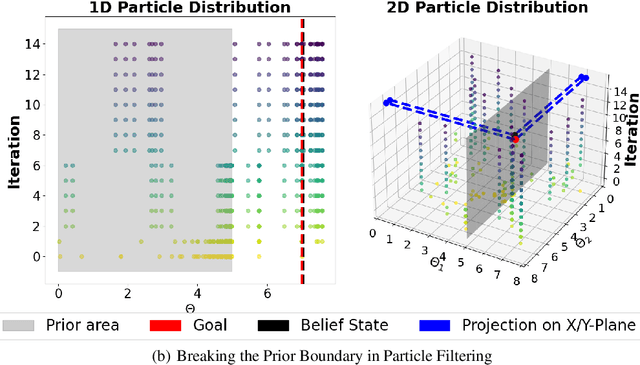
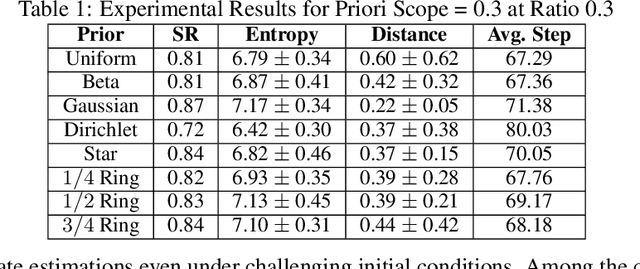
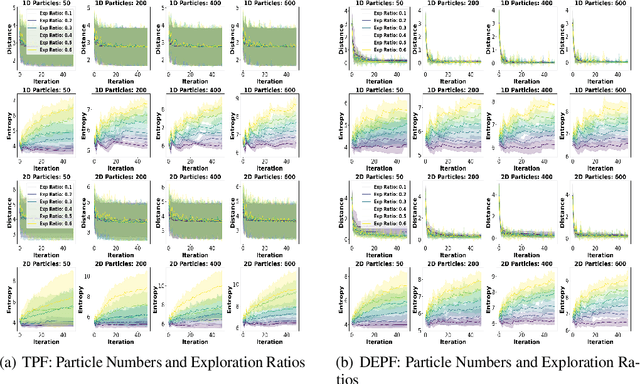
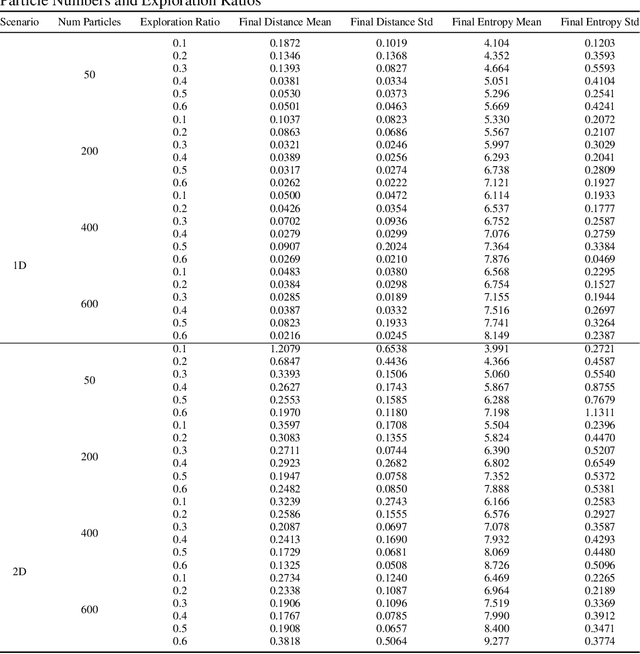
Particle filtering is a Bayesian inference method and a fundamental tool in state estimation for dynamic systems, but its effectiveness is often limited by the constraints of the initial prior distribution, a phenomenon we define as the Prior Boundary Phenomenon. This challenge arises when target states lie outside the prior's support, rendering traditional particle filtering methods inadequate for accurate estimation. Although techniques like unbounded priors and larger particle sets have been proposed, they remain computationally prohibitive and lack adaptability in dynamic scenarios. To systematically overcome these limitations, we propose the Diffusion-Enhanced Particle Filtering Framework, which introduces three key innovations: adaptive diffusion through exploratory particles, entropy-driven regularisation to prevent weight collapse, and kernel-based perturbations for dynamic support expansion. These mechanisms collectively enable particle filtering to explore beyond prior boundaries, ensuring robust state estimation for out-of-boundary targets. Theoretical analysis and extensive experiments validate framework's effectiveness, indicating significant improvements in success rates and estimation accuracy across high-dimensional and non-convex scenarios.
Design and Benchmarking of A Multi-Modality Sensor for Robotic Manipulation with GAN-Based Cross-Modality Interpretation
Jan 04, 2025



In this paper, we present the design and benchmark of an innovative sensor, ViTacTip, which fulfills the demand for advanced multi-modal sensing in a compact design. A notable feature of ViTacTip is its transparent skin, which incorporates a `see-through-skin' mechanism. This mechanism aims at capturing detailed object features upon contact, significantly improving both vision-based and proximity perception capabilities. In parallel, the biomimetic tips embedded in the sensor's skin are designed to amplify contact details, thus substantially augmenting tactile and derived force perception abilities. To demonstrate the multi-modal capabilities of ViTacTip, we developed a multi-task learning model that enables simultaneous recognition of hardness, material, and textures. To assess the functionality and validate the versatility of ViTacTip, we conducted extensive benchmarking experiments, including object recognition, contact point detection, pose regression, and grating identification. To facilitate seamless switching between various sensing modalities, we employed a Generative Adversarial Network (GAN)-based approach. This method enhances the applicability of the ViTacTip sensor across diverse environments by enabling cross-modality interpretation.
Large Vision-Language Model Alignment and Misalignment: A Survey Through the Lens of Explainability
Jan 02, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in processing both visual and textual information. However, the critical challenge of alignment between visual and linguistic representations is not fully understood. This survey presents a comprehensive examination of alignment and misalignment in LVLMs through an explainability lens. We first examine the fundamentals of alignment, exploring its representational and behavioral aspects, training methodologies, and theoretical foundations. We then analyze misalignment phenomena across three semantic levels: object, attribute, and relational misalignment. Our investigation reveals that misalignment emerges from challenges at multiple levels: the data level, the model level, and the inference level. We provide a comprehensive review of existing mitigation strategies, categorizing them into parameter-frozen and parameter-tuning approaches. Finally, we outline promising future research directions, emphasizing the need for standardized evaluation protocols and in-depth explainability studies.
ProxiMix: Enhancing Fairness with Proximity Samples in Subgroups
Oct 02, 2024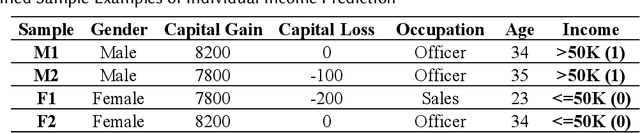
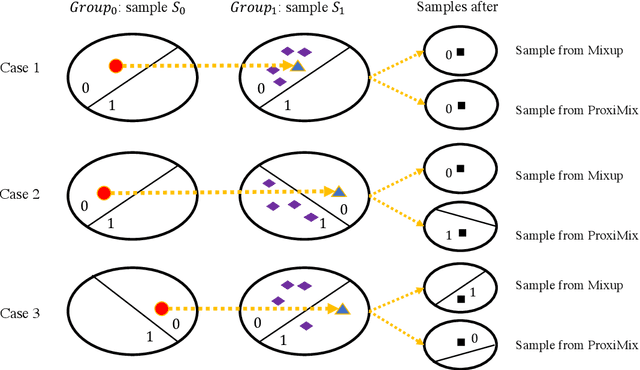

Many bias mitigation methods have been developed for addressing fairness issues in machine learning. We found that using linear mixup alone, a data augmentation technique, for bias mitigation, can still retain biases present in dataset labels. Research presented in this paper aims to address this issue by proposing a novel pre-processing strategy in which both an existing mixup method and our new bias mitigation algorithm can be utilized to improve the generation of labels of augmented samples, which are proximity aware. Specifically, we proposed ProxiMix which keeps both pairwise and proximity relationships for fairer data augmentation. We conducted thorough experiments with three datasets, three ML models, and different hyperparameters settings. Our experimental results showed the effectiveness of ProxiMix from both fairness of predictions and fairness of recourse perspectives.
TSFeatLIME: An Online User Study in Enhancing Explainability in Univariate Time Series Forecasting
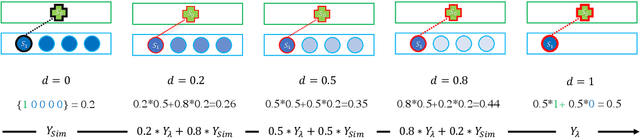
Sep 24, 2024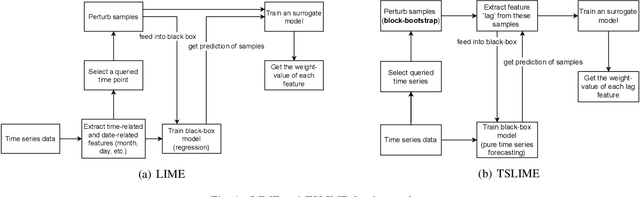
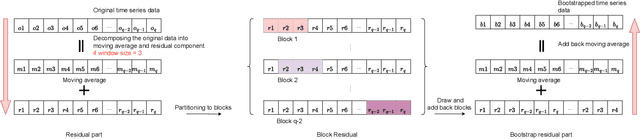
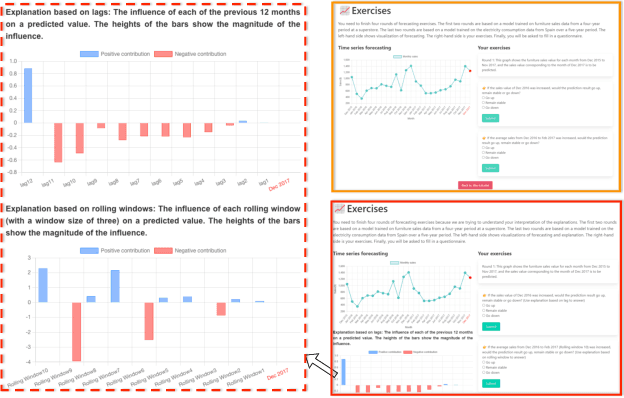
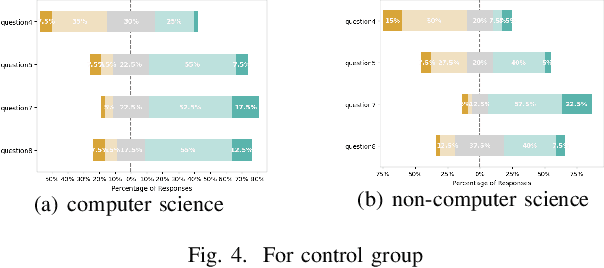
Time series forecasting, while vital in various applications, often employs complex models that are difficult for humans to understand. Effective explainable AI techniques are crucial to bridging the gap between model predictions and user understanding. This paper presents a framework - TSFeatLIME, extending TSLIME, tailored specifically for explaining univariate time series forecasting. TSFeatLIME integrates an auxiliary feature into the surrogate model and considers the pairwise Euclidean distances between the queried time series and the generated samples to improve the fidelity of the surrogate models. However, the usefulness of such explanations for human beings remains an open question. We address this by conducting a user study with 160 participants through two interactive interfaces, aiming to measure how individuals from different backgrounds can simulate or predict model output changes in the treatment group and control group. Our results show that the surrogate model under the TSFeatLIME framework is able to better simulate the behaviour of the black-box considering distance, without sacrificing accuracy. In addition, the user study suggests that the explanations were significantly more effective for participants without a computer science background.