 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Trajectory Recovery for Continuous Mechanism Evolution in Causal Representation Learning
Jan 29, 2026Temporal causal representation learning methods assume that causal mechanisms switch instantaneously between discrete domains, yet real-world systems often exhibit continuous mechanism transitions. For example, a vehicle's dynamics evolve gradually through a turning maneuver, and human gait shifts smoothly from walking to running. We formalize this setting by modeling transitional mechanisms as convex combinations of finitely many atomic mechanisms, governed by time-varying mixing coefficients. Our theoretical contributions establish that both the latent causal variables and the continuous mixing trajectory are jointly identifiable. We further propose TRACE, a Mixture-of-Experts framework where each expert learns one atomic mechanism during training, enabling recovery of mechanism trajectories at test time. This formulation generalizes to intermediate mechanism states never observed during training. Experiments on synthetic and real-world data demonstrate that TRACE recovers mixing trajectories with up to 0.99 correlation, substantially outperforming discrete-switching baselines.
EpiQAL: Benchmarking Large Language Models in Epidemiological Question Answering for Enhanced Alignment and Reasoning
Jan 06, 2026Reliable epidemiological reasoning requires synthesizing study evidence to infer disease burden, transmission dynamics, and intervention effects at the population level. Existing medical question answering benchmarks primarily emphasize clinical knowledge or patient-level reasoning, yet few systematically evaluate evidence-grounded epidemiological inference. We present EpiQAL, the first diagnostic benchmark for epidemiological question answering across diverse diseases, comprising three subsets built from open-access literature. The subsets respectively evaluate text-grounded factual recall, multi-step inference linking document evidence with epidemiological principles, and conclusion reconstruction with the Discussion section withheld. Construction combines expert-designed taxonomy guidance, multi-model verification, and retrieval-based difficulty control. Experiments on ten open models reveal that current LLMs show limited performance on epidemiological reasoning, with multi-step inference posing the greatest challenge. Model rankings shift across subsets, and scale alone does not predict success. Chain-of-Thought prompting benefits multi-step inference but yields mixed results elsewhere. EpiQAL provides fine-grained diagnostic signals for evidence grounding, inferential reasoning, and conclusion reconstruction.
QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation
Dec 22, 2025Dynamic Retrieval-Augmented Generation adaptively determines when to retrieve during generation to mitigate hallucinations in large language models (LLMs). However, existing methods rely on model-internal signals (e.g., logits, entropy), which are fundamentally unreliable because LLMs are typically ill-calibrated and often exhibit high confidence in erroneous outputs. We propose QuCo-RAG, which shifts from subjective confidence to objective statistics computed from pre-training data. Our method quantifies uncertainty through two stages: (1) before generation, we identify low-frequency entities indicating long-tail knowledge gaps; (2) during generation, we verify entity co-occurrence in the pre-training corpus, where zero co-occurrence often signals hallucination risk. Both stages leverage Infini-gram for millisecond-latency queries over 4 trillion tokens, triggering retrieval when uncertainty is high. Experiments on multi-hop QA benchmarks show QuCo-RAG achieves EM gains of 5--12 points over state-of-the-art baselines with OLMo-2 models, and transfers effectively to models with undisclosed pre-training data (Llama, Qwen, GPT), improving EM by up to 14 points. Domain generalization on biomedical QA further validates the robustness of our paradigm. These results establish corpus-grounded verification as a principled, practically model-agnostic paradigm for dynamic RAG. Our code is publicly available at https://github.com/ZhishanQ/QuCo-RAG.
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Nov 18, 2025

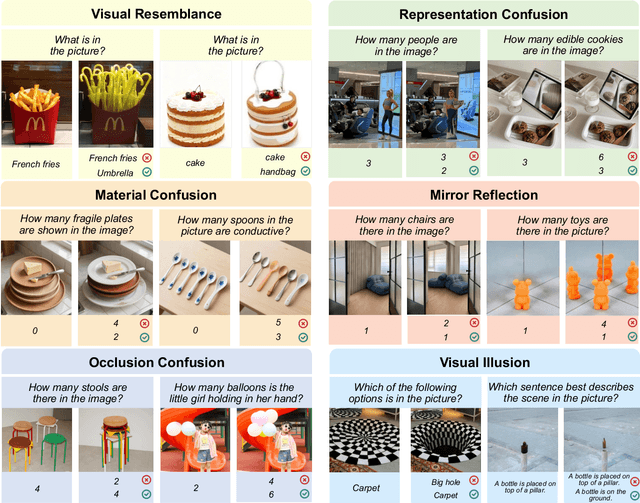

Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
Revisiting NLI: Towards Cost-Effective and Human-Aligned Metrics for Evaluating LLMs in Question Answering
Nov 10, 2025Evaluating answers from state-of-the-art large language models (LLMs) is challenging: lexical metrics miss semantic nuances, whereas "LLM-as-Judge" scoring is computationally expensive. We re-evaluate a lightweight alternative -- off-the-shelf Natural Language Inference (NLI) scoring augmented by a simple lexical-match flag and find that this decades-old technique matches GPT-4o's accuracy (89.9%) on long-form QA, while requiring orders-of-magnitude fewer parameters. To test human alignment of these metrics rigorously, we introduce DIVER-QA, a new 3000-sample human-annotated benchmark spanning five QA datasets and five candidate LLMs. Our results highlight that inexpensive NLI-based evaluation remains competitive and offer DIVER-QA as an open resource for future metric research.
Robust Uncertainty Quantification for Self-Evolving Large Language Models via Continual Domain Pretraining
Oct 27, 2025



Continual Learning (CL) is essential for enabling self-evolving large language models (LLMs) to adapt and remain effective amid rapid knowledge growth. Yet, despite its importance, little attention has been given to establishing statistical reliability guarantees for LLMs under CL, particularly in the setting of continual domain pretraining (CDP). Conformal Prediction (CP) has shown promise in offering correctness guarantees for LLMs, but it faces major challenges in CDP: testing data often stems from unknown or shifting domain distributions, under which CP may no longer provide valid guarantees. Moreover, when high coverage is required, CP can yield excessively large prediction sets for unanswerable queries, reducing informativeness. To address these challenges, we introduce an adaptive rejection and non-exchangeable CP framework. Our method first estimates the distribution of questions across domains in the test set using transformer-based clustering, then reweights or resamples the calibration data accordingly. Building on this, adaptive rejection CP allows the LLM to selectively abstain from answering when its confidence or competence shifts significantly. Extensive experiments demonstrate that our framework enhances both the effectiveness and reliability of CP under CDP scenarios. Our code is available at: https://anonymous.4open.science/r/CPCL-8C12/
Credence Calibration Game? Calibrating Large Language Models through Structured Play
Aug 20, 2025As Large Language Models (LLMs) are increasingly deployed in decision-critical domains, it becomes essential to ensure that their confidence estimates faithfully correspond to their actual correctness. Existing calibration methods have primarily focused on post-hoc adjustments or auxiliary model training; however, many of these approaches necessitate additional supervision or parameter updates. In this work, we propose a novel prompt-based calibration framework inspired by the Credence Calibration Game. Our method establishes a structured interaction loop wherein LLMs receive feedback based on the alignment of their predicted confidence with correctness. Through feedback-driven prompting and natural language summaries of prior performance, our framework dynamically improves model calibration. Extensive experiments across models and game configurations demonstrate consistent improvements in evaluation metrics. Our results highlight the potential of game-based prompting as an effective strategy for LLM calibration. Code and data are available at https://anonymous.4open.science/r/LLM-Calibration/.
CP-Router: An Uncertainty-Aware Router Between LLM and LRM
May 26, 2025Recent advances in Large Reasoning Models (LRMs) have significantly improved long-chain reasoning capabilities over Large Language Models (LLMs). However, LRMs often produce unnecessarily lengthy outputs even for simple queries, leading to inefficiencies or even accuracy degradation compared to LLMs. To overcome this, we propose CP-Router, a training-free and model-agnostic routing framework that dynamically selects between an LLM and an LRM, demonstrated with multiple-choice question answering (MCQA) prompts. The routing decision is guided by the prediction uncertainty estimates derived via Conformal Prediction (CP), which provides rigorous coverage guarantees. To further refine the uncertainty differentiation across inputs, we introduce Full and Binary Entropy (FBE), a novel entropy-based criterion that adaptively selects the appropriate CP threshold. Experiments across diverse MCQA benchmarks, including mathematics, logical reasoning, and Chinese chemistry, demonstrate that CP-Router efficiently reduces token usage while maintaining or even improving accuracy compared to using LRM alone. We also extend CP-Router to diverse model pairings and open-ended QA, where it continues to demonstrate strong performance, validating its generality and robustness.
Shakespearean Sparks: The Dance of Hallucination and Creativity in LLMs' Decoding Layers
Mar 04, 2025



Large language models (LLMs) are known to hallucinate, a phenomenon often linked to creativity. While previous research has primarily explored this connection through theoretical or qualitative lenses, our work takes a quantitative approach to systematically examine the relationship between hallucination and creativity in LLMs. Given the complex nature of creativity, we propose a narrow definition tailored to LLMs and introduce an evaluation framework, HCL, which quantifies Hallucination and Creativity across different Layers of LLMs during decoding. Our empirical analysis reveals a tradeoff between hallucination and creativity that is consistent across layer depth, model type, and model size. Notably, across different model architectures, we identify a specific layer at each model size that optimally balances this tradeoff. Additionally, the optimal layer tends to appear in the early layers of larger models, and the confidence of the model is also significantly higher at this layer. These findings provide a quantitative perspective that offers new insights into the interplay between LLM creativity and hallucination. The code and data for our experiments are available at https://github.com/ZicongHe2002/HCL-Spark.
DBR: Divergence-Based Regularization for Debiasing Natural Language Understanding Models
Feb 25, 2025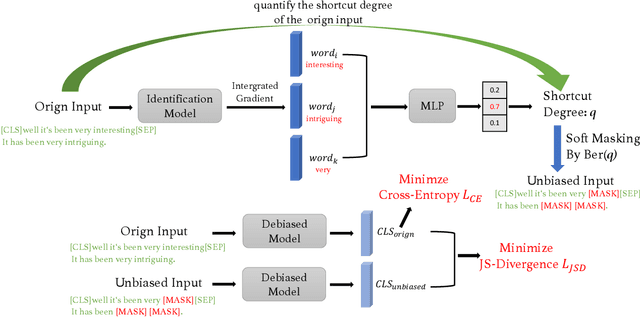
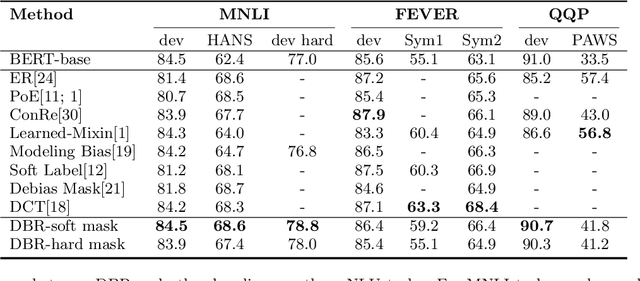


Pre-trained language models (PLMs) have achieved impressive results on various natural language processing tasks. However, recent research has revealed that these models often rely on superficial features and shortcuts instead of developing a genuine understanding of language, especially for natural language understanding (NLU) tasks. Consequently, the models struggle to generalize to out-of-domain data. In this work, we propose Divergence Based Regularization (DBR) to mitigate this shortcut learning behavior. Our method measures the divergence between the output distributions for original examples and examples where shortcut tokens have been masked. This process prevents the model's predictions from being overly influenced by shortcut features or biases. We evaluate our model on three NLU tasks and find that it improves out-of-domain performance with little loss of in-domain accuracy. Our results demonstrate that reducing the reliance on shortcuts and superficial features can enhance the generalization ability of large pre-trained language models.