 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Domain Divide: Supervised vs. Zero-Shot Clinical Section Segmentation from MIMIC-III to Obstetrics
Feb 19, 2026Clinical free-text notes contain vital patient information. They are structured into labelled sections; recognizing these sections has been shown to support clinical decision-making and downstream NLP tasks. In this paper, we advance clinical section segmentation through three key contributions. First, we curate a new de-identified, section-labeled obstetrics notes dataset, to supplement the medical domains covered in public corpora such as MIMIC-III, on which most existing segmentation approaches are trained. Second, we systematically evaluate transformer-based supervised models for section segmentation on a curated subset of MIMIC-III (in-domain), and on the new obstetrics dataset (out-of-domain). Third, we conduct the first head-to-head comparison of supervised models for medical section segmentation with zero-shot large language models. Our results show that while supervised models perform strongly in-domain, their performance drops substantially out-of-domain. In contrast, zero-shot models demonstrate robust out-of-domain adaptability once hallucinated section headers are corrected. These findings underscore the importance of developing domain-specific clinical resources and highlight zero-shot segmentation as a promising direction for applying healthcare NLP beyond well-studied corpora, as long as hallucinations are appropriately managed.
Abstract Meaning Representation for Hospital Discharge Summarization
Jun 17, 2025The Achilles heel of Large Language Models (LLMs) is hallucination, which has drastic consequences for the clinical domain. This is particularly important with regards to automatically generating discharge summaries (a lengthy medical document that summarizes a hospital in-patient visit). Automatically generating these summaries would free physicians to care for patients and reduce documentation burden. The goal of this work is to discover new methods that combine language-based graphs and deep learning models to address provenance of content and trustworthiness in automatic summarization. Our method shows impressive reliability results on the publicly available Medical Information Mart for Intensive III (MIMIC-III) corpus and clinical notes written by physicians at Anonymous Hospital. rovide our method, generated discharge ary output examples, source code and trained models.
Veracity Bias and Beyond: Uncovering LLMs' Hidden Beliefs in Problem-Solving Reasoning
May 22, 2025Despite LLMs' explicit alignment against demographic stereotypes, they have been shown to exhibit biases under various social contexts. In this work, we find that LLMs exhibit concerning biases in how they associate solution veracity with demographics. Through experiments across five human value-aligned LLMs on mathematics, coding, commonsense, and writing problems, we reveal two forms of such veracity biases: Attribution Bias, where models disproportionately attribute correct solutions to certain demographic groups, and Evaluation Bias, where models' assessment of identical solutions varies based on perceived demographic authorship. Our results show pervasive biases: LLMs consistently attribute fewer correct solutions and more incorrect ones to African-American groups in math and coding, while Asian authorships are least preferred in writing evaluation. In additional studies, we show LLMs automatically assign racially stereotypical colors to demographic groups in visualization code, suggesting these biases are deeply embedded in models' reasoning processes. Our findings indicate that demographic bias extends beyond surface-level stereotypes and social context provocations, raising concerns about LLMs' deployment in educational and evaluation settings.
Towards conversational assistants for health applications: using ChatGPT to generate conversations about heart failure
May 06, 2025
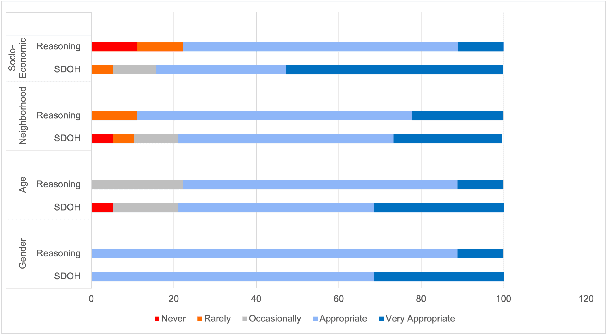


We explore the potential of ChatGPT (3.5-turbo and 4) to generate conversations focused on self-care strategies for African-American heart failure patients -- a domain with limited specialized datasets. To simulate patient-health educator dialogues, we employed four prompting strategies: domain, African American Vernacular English (AAVE), Social Determinants of Health (SDOH), and SDOH-informed reasoning. Conversations were generated across key self-care domains of food, exercise, and fluid intake, with varying turn lengths (5, 10, 15) and incorporated patient-specific SDOH attributes such as age, gender, neighborhood, and socioeconomic status. Our findings show that effective prompt design is essential. While incorporating SDOH and reasoning improves dialogue quality, ChatGPT still lacks the empathy and engagement needed for meaningful healthcare communication.
Conversational Assistants to support Heart Failure Patients: comparing a Neurosymbolic Architecture with ChatGPT
Apr 24, 2025
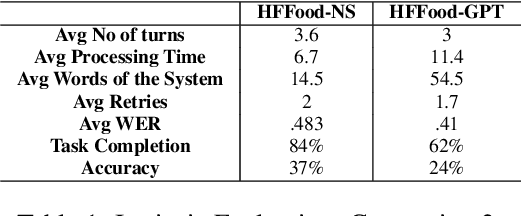
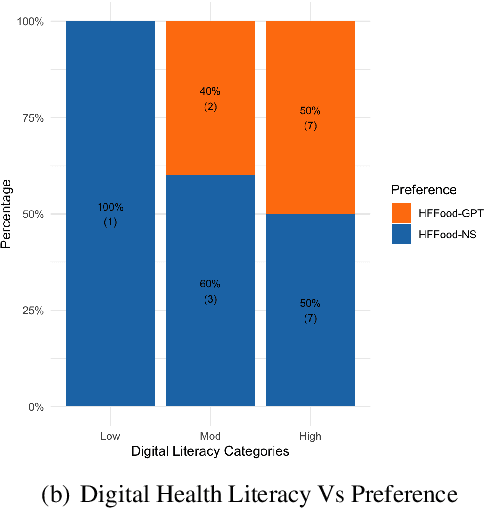
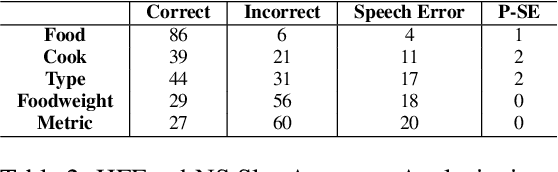
Conversational assistants are becoming more and more popular, including in healthcare, partly because of the availability and capabilities of Large Language Models. There is a need for controlled, probing evaluations with real stakeholders which can highlight advantages and disadvantages of more traditional architectures and those based on generative AI. We present a within-group user study to compare two versions of a conversational assistant that allows heart failure patients to ask about salt content in food. One version of the system was developed in-house with a neurosymbolic architecture, and one is based on ChatGPT. The evaluation shows that the in-house system is more accurate, completes more tasks and is less verbose than the one based on ChatGPT; on the other hand, the one based on ChatGPT makes fewer speech errors and requires fewer clarifications to complete the task. Patients show no preference for one over the other.
Unveiling Performance Challenges of Large Language Models in Low-Resource Healthcare: A Demographic Fairness Perspective
Nov 30, 2024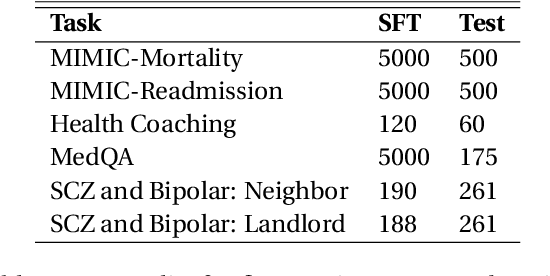
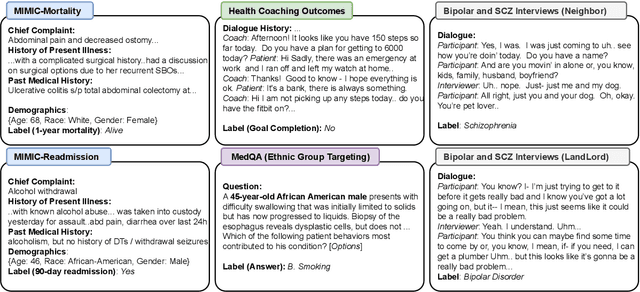
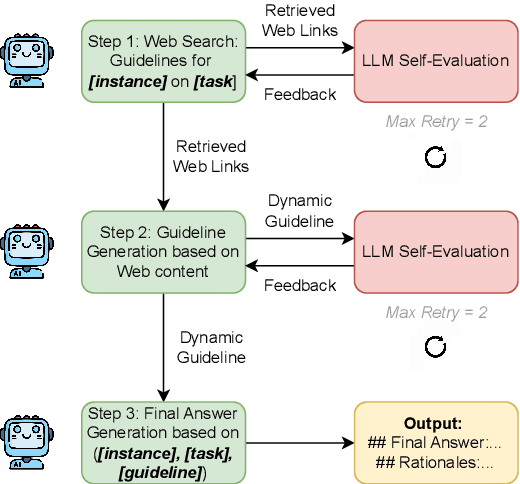
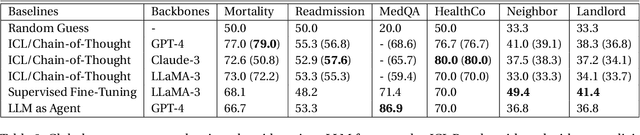
This paper studies the performance of large language models (LLMs), particularly regarding demographic fairness, in solving real-world healthcare tasks. We evaluate state-of-the-art LLMs with three prevalent learning frameworks across six diverse healthcare tasks and find significant challenges in applying LLMs to real-world healthcare tasks and persistent fairness issues across demographic groups. We also find that explicitly providing demographic information yields mixed results, while LLM's ability to infer such details raises concerns about biased health predictions. Utilizing LLMs as autonomous agents with access to up-to-date guidelines does not guarantee performance improvement. We believe these findings reveal the critical limitations of LLMs in healthcare fairness and the urgent need for specialized research in this area.
Large Language Models Are Involuntary Truth-Tellers: Exploiting Fallacy Failure for Jailbreak Attacks
Jul 01, 2024
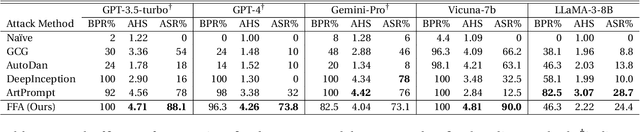

We find that language models have difficulties generating fallacious and deceptive reasoning. When asked to generate deceptive outputs, language models tend to leak honest counterparts but believe them to be false. Exploiting this deficiency, we propose a jailbreak attack method that elicits an aligned language model for malicious output. Specifically, we query the model to generate a fallacious yet deceptively real procedure for the harmful behavior. Since a fallacious procedure is generally considered fake and thus harmless by LLMs, it helps bypass the safeguard mechanism. Yet the output is factually harmful since the LLM cannot fabricate fallacious solutions but proposes truthful ones. We evaluate our approach over five safety-aligned large language models, comparing four previous jailbreak methods, and show that our approach achieves competitive performance with more harmful outputs. We believe the findings could be extended beyond model safety, such as self-verification and hallucination.
Modeling Low-Resource Health Coaching Dialogues via Neuro-Symbolic Goal Summarization and Text-Units-Text Generation
Apr 16, 2024
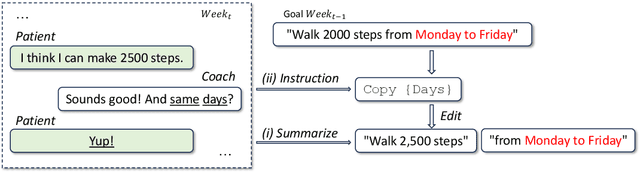
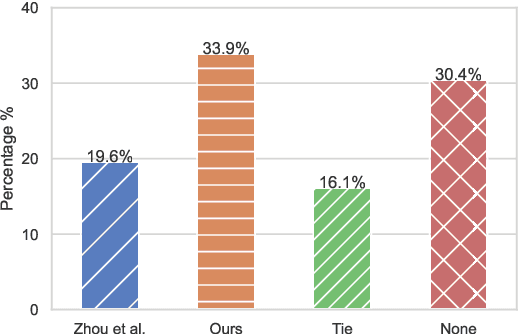
Health coaching helps patients achieve personalized and lifestyle-related goals, effectively managing chronic conditions and alleviating mental health issues. It is particularly beneficial, however cost-prohibitive, for low-socioeconomic status populations due to its highly personalized and labor-intensive nature. In this paper, we propose a neuro-symbolic goal summarizer to support health coaches in keeping track of the goals and a text-units-text dialogue generation model that converses with patients and helps them create and accomplish specific goals for physical activities. Our models outperform previous state-of-the-art while eliminating the need for predefined schema and corresponding annotation. We also propose a new health coaching dataset extending previous work and a metric to measure the unconventionality of the patient's response based on data difficulty, facilitating potential coach alerts during deployment.
Towards Enhancing Health Coaching Dialogue in Low-Resource Settings
Apr 13, 2024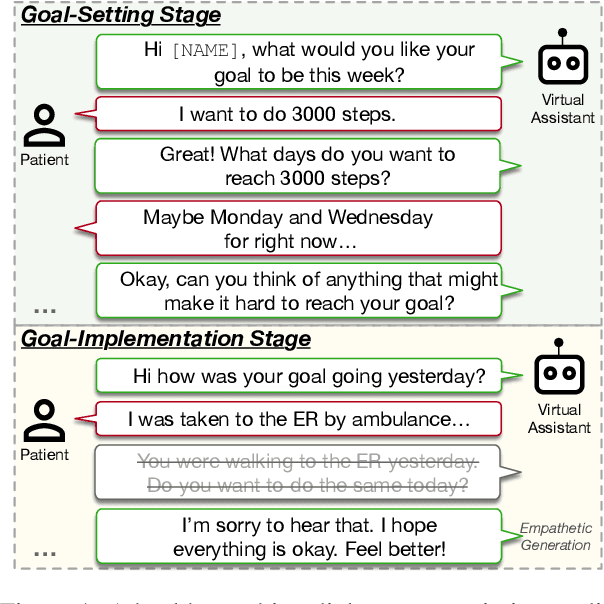
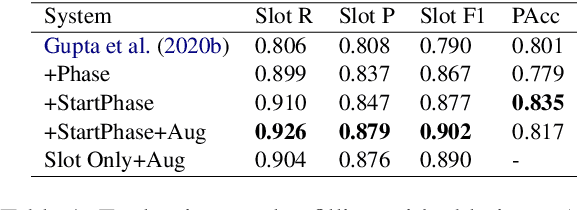
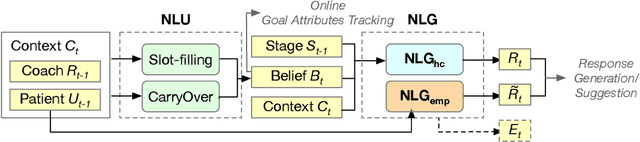

Health coaching helps patients identify and accomplish lifestyle-related goals, effectively improving the control of chronic diseases and mitigating mental health conditions. However, health coaching is cost-prohibitive due to its highly personalized and labor-intensive nature. In this paper, we propose to build a dialogue system that converses with the patients, helps them create and accomplish specific goals, and can address their emotions with empathy. However, building such a system is challenging since real-world health coaching datasets are limited and empathy is subtle. Thus, we propose a modularized health coaching dialogue system with simplified NLU and NLG frameworks combined with mechanism-conditioned empathetic response generation. Through automatic and human evaluation, we show that our system generates more empathetic, fluent, and coherent responses and outperforms the state-of-the-art in NLU tasks while requiring less annotation. We view our approach as a key step towards building automated and more accessible health coaching systems.
A Neuro-Symbolic Approach to Monitoring Salt Content in Food
Apr 01, 2024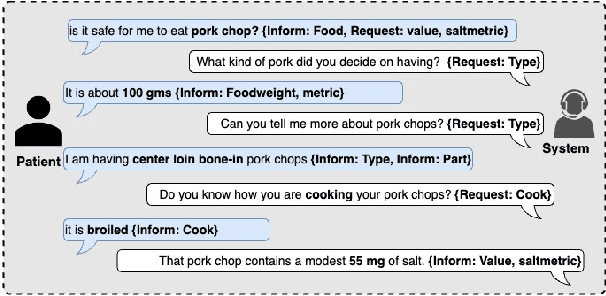

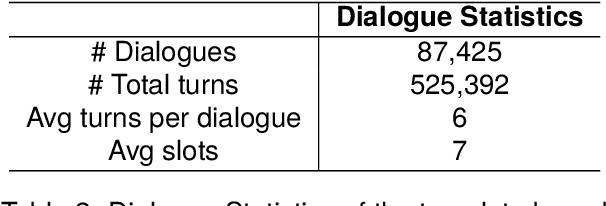
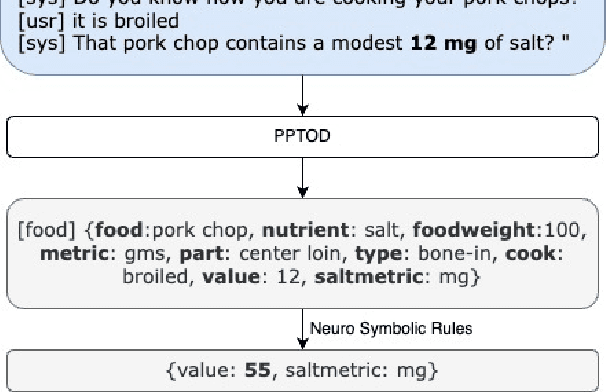
We propose a dialogue system that enables heart failure patients to inquire about salt content in foods and help them monitor and reduce salt intake. Addressing the lack of specific datasets for food-based salt content inquiries, we develop a template-based conversational dataset. The dataset is structured to ask clarification questions to identify food items and their salt content. Our findings indicate that while fine-tuning transformer-based models on the dataset yields limited performance, the integration of Neuro-Symbolic Rules significantly enhances the system's performance. Our experiments show that by integrating neuro-symbolic rules, our system achieves an improvement in joint goal accuracy of over 20% across different data sizes compared to naively fine-tuning transformer-based models.