 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyHealth 2.0: A Comprehensive Open-Source Toolkit for Accessible and Reproducible Clinical Deep Learning
Jan 23, 2026Difficulty replicating baselines, high computational costs, and required domain expertise create persistent barriers to clinical AI research. To address these challenges, we introduce PyHealth 2.0, an enhanced clinical deep learning toolkit that enables predictive modeling in as few as 7 lines of code. PyHealth 2.0 offers three key contributions: (1) a comprehensive toolkit addressing reproducibility and compatibility challenges by unifying 15+ datasets, 20+ clinical tasks, 25+ models, 5+ interpretability methods, and uncertainty quantification including conformal prediction within a single framework that supports diverse clinical data modalities - signals, imaging, and electronic health records - with translation of 5+ medical coding standards; (2) accessibility-focused design accommodating multimodal data and diverse computational resources with up to 39x faster processing and 20x lower memory usage, enabling work from 16GB laptops to production systems; and (3) an active open-source community of 400+ members lowering domain expertise barriers through extensive documentation, reproducible research contributions, and collaborations with academic health systems and industry partners, including multi-language support via RHealth. PyHealth 2.0 establishes an open-source foundation and community advancing accessible, reproducible healthcare AI. Available at pip install pyhealth.
Abstract Meaning Representation for Hospital Discharge Summarization
Jun 17, 2025The Achilles heel of Large Language Models (LLMs) is hallucination, which has drastic consequences for the clinical domain. This is particularly important with regards to automatically generating discharge summaries (a lengthy medical document that summarizes a hospital in-patient visit). Automatically generating these summaries would free physicians to care for patients and reduce documentation burden. The goal of this work is to discover new methods that combine language-based graphs and deep learning models to address provenance of content and trustworthiness in automatic summarization. Our method shows impressive reliability results on the publicly available Medical Information Mart for Intensive III (MIMIC-III) corpus and clinical notes written by physicians at Anonymous Hospital. rovide our method, generated discharge ary output examples, source code and trained models.
Enhancing Clinical Models with Pseudo Data for De-identification
Jun 15, 2025Many models are pretrained on redacted text for privacy reasons. Clinical foundation models are often trained on de-identified text, which uses special syntax (masked) text in place of protected health information. Even though these models have increased in popularity, there has been little effort in understanding the effects of training them on redacted text. In this work, we pretrain several encoder-only models on a dataset that contains redacted text and a version with replaced realistic pseudo text. We then fine-tuned models for the protected health information de-identification task and show how our methods significantly outperform previous baselines. The contributions of this work include: a) our novel, and yet surprising findings with training recommendations, b) redacted text replacements used to produce the pseudo dataset, c) pretrained embeddings and fine-tuned task specific models, and d) freely available pseudo training dataset generation and model source code used in our experiments.
Integration of Large Language Models and Traditional Deep Learning for Social Determinants of Health Prediction
May 06, 2025Social Determinants of Health (SDoH) are economic, social and personal circumstances that affect or influence an individual's health status. SDoHs have shown to be correlated to wellness outcomes, and therefore, are useful to physicians in diagnosing diseases and in decision-making. In this work, we automatically extract SDoHs from clinical text using traditional deep learning and Large Language Models (LLMs) to find the advantages and disadvantages of each on an existing publicly available dataset. Our models outperform a previous reference point on a multilabel SDoH classification by 10 points, and we present a method and model to drastically speed up classification (12X execution time) by eliminating expensive LLM processing. The method we present combines a more nimble and efficient solution that leverages the power of the LLM for precision and traditional deep learning methods for efficiency. We also show highly performant results on a dataset supplemented with synthetic data and several traditional deep learning models that outperform LLMs. Our models and methods offer the next iteration of automatic prediction of SDoHs that impact at-risk patients.
DeepZensols: Deep Natural Language Processing Framework
Sep 08, 2021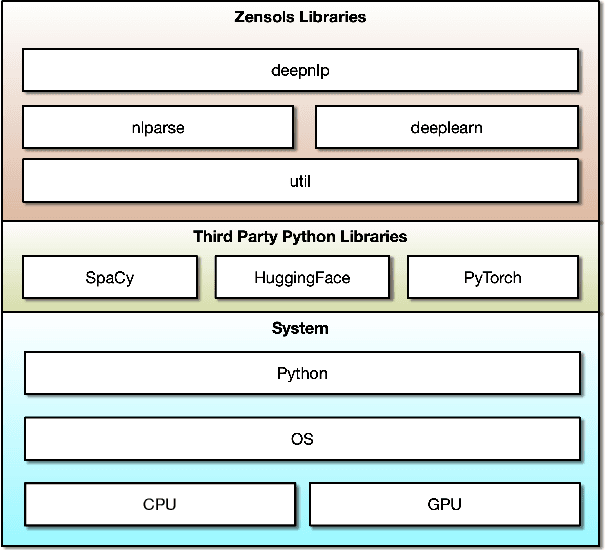



Reproducing results in publications by distributing publicly available source code is becoming ever more popular. Given the difficulty of reproducing machine learning (ML) experiments, there have been significant efforts in reducing the variance of these results. As in any science, the ability to consistently reproduce results effectively strengthens the underlying hypothesis of the work, and thus, should be regarded as important as the novel aspect of the research itself. The contribution of this work is a framework that is able to reproduce consistent results and provides a means of easily creating, training, and evaluating natural language processing (NLP) deep learning (DL) models.
A Supervised Approach To The Interpretation Of Imperative To-Do Lists
Jun 20, 2018



To-do lists are a popular medium for personal information management. As to-do tasks are increasingly tracked in electronic form with mobile and desktop organizers, so does the potential for software support for the corresponding tasks by means of intelligent agents. While there has been work in the area of personal assistants for to-do tasks, no work has focused on classifying user intention and information extraction as we do. We show that our methods perform well across two corpora that span sub-domains, one of which we released.