Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepZensols: Deep Natural Language Processing Framework
Paper and Code
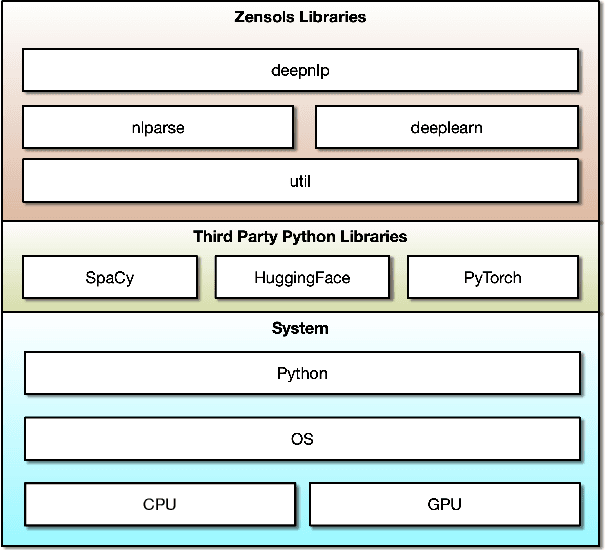



Reproducing results in publications by distributing publicly available source code is becoming ever more popular. Given the difficulty of reproducing machine learning (ML) experiments, there have been significant efforts in reducing the variance of these results. As in any science, the ability to consistently reproduce results effectively strengthens the underlying hypothesis of the work, and thus, should be regarded as important as the novel aspect of the research itself. The contribution of this work is a framework that is able to reproduce consistent results and provides a means of easily creating, training, and evaluating natural language processing (NLP) deep learning (DL) models.
View paper on