 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLooP: Zero-Shot Abstractive Summarization using Large Language Models with Bigram Lookahead Promotion
Mar 12, 2026Abstractive summarization requires models to generate summaries that convey information in the source document. While large language models can generate summaries without fine-tuning, they often miss key details and include extraneous information. We propose BLooP (Bigram Lookahead Promotion), a simple training-free decoding intervention that encourages large language models (LLMs) to generate tokens that form bigrams from the source document. BLooP operates through a hash table lookup at each decoding step, requiring no training, fine-tuning, or model modification. We demonstrate improvements in ROUGE and BARTScore for Llama-3.1-8B-Instruct, Mistral-Nemo-Instruct-2407, and Gemma-2-9b-it on CNN/DM, CCSum, Multi-News, and SciTLDR. Human evaluation shows that BLooP significantly improves faithfulness without reducing readability. We make the code available at https://github.com/varuniyer/BLooP
CalibrateMix: Guided-Mixup Calibration of Image Semi-Supervised Models
Nov 17, 2025Semi-supervised learning (SSL) has demonstrated high performance in image classification tasks by effectively utilizing both labeled and unlabeled data. However, existing SSL methods often suffer from poor calibration, with models yielding overconfident predictions that misrepresent actual prediction likelihoods. Recently, neural networks trained with {\tt mixup} that linearly interpolates random examples from the training set have shown better calibration in supervised settings. However, calibration of neural models remains under-explored in semi-supervised settings. Although effective in supervised model calibration, random mixup of pseudolabels in SSL presents challenges due to the overconfidence and unreliability of pseudolabels. In this work, we introduce CalibrateMix, a targeted mixup-based approach that aims to improve the calibration of SSL models while maintaining or even improving their classification accuracy. Our method leverages training dynamics of labeled and unlabeled samples to identify ``easy-to-learn'' and ``hard-to-learn'' samples, which in turn are utilized in a targeted mixup of easy and hard samples. Experimental results across several benchmark image datasets show that our method achieves lower expected calibration error (ECE) and superior accuracy compared to existing SSL approaches.
Let's Use ChatGPT To Write Our Paper! Benchmarking LLMs To Write the Introduction of a Research Paper
Aug 19, 2025
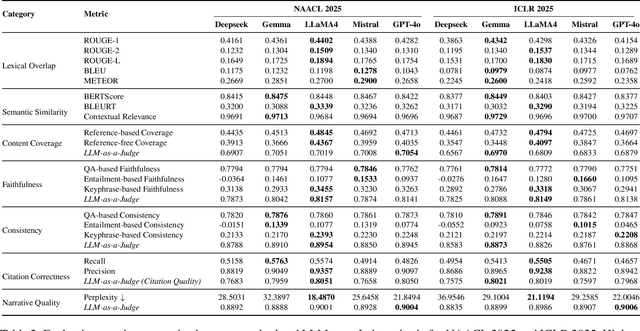
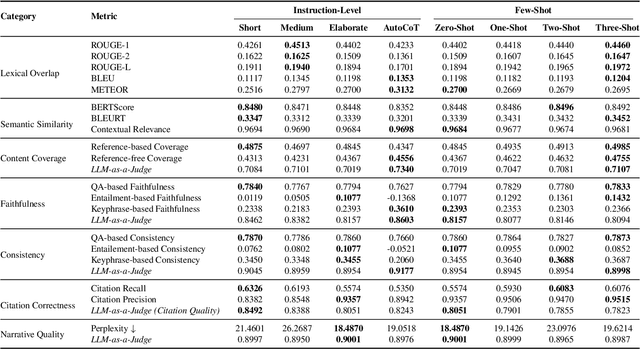
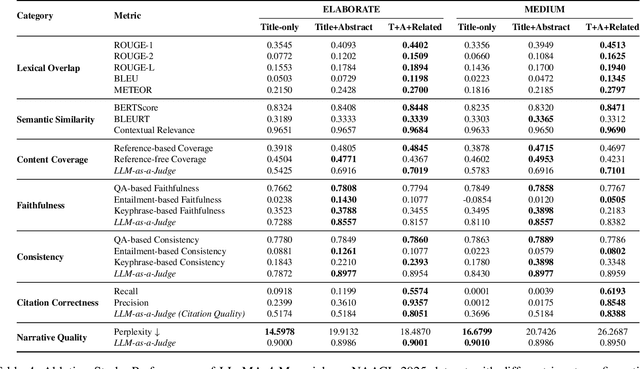
As researchers increasingly adopt LLMs as writing assistants, generating high-quality research paper introductions remains both challenging and essential. We introduce Scientific Introduction Generation (SciIG), a task that evaluates LLMs' ability to produce coherent introductions from titles, abstracts, and related works. Curating new datasets from NAACL 2025 and ICLR 2025 papers, we assess five state-of-the-art models, including both open-source (DeepSeek-v3, Gemma-3-12B, LLaMA 4-Maverick, MistralAI Small 3.1) and closed-source GPT-4o systems, across multiple dimensions: lexical overlap, semantic similarity, content coverage, faithfulness, consistency, citation correctness, and narrative quality. Our comprehensive framework combines automated metrics with LLM-as-a-judge evaluations. Results demonstrate LLaMA-4 Maverick's superior performance on most metrics, particularly in semantic similarity and faithfulness. Moreover, three-shot prompting consistently outperforms fewer-shot approaches. These findings provide practical insights into developing effective research writing assistants and set realistic expectations for LLM-assisted academic writing. To foster reproducibility and future research, we will publicly release all code and datasets.
MultiMatch: Multihead Consistency Regularization Matching for Semi-Supervised Text Classification
Jun 09, 2025



We introduce MultiMatch, a novel semi-supervised learning (SSL) algorithm combining the paradigms of co-training and consistency regularization with pseudo-labeling. At its core, MultiMatch features a three-fold pseudo-label weighting module designed for three key purposes: selecting and filtering pseudo-labels based on head agreement and model confidence, and weighting them according to the perceived classification difficulty. This novel module enhances and unifies three existing techniques -- heads agreement from Multihead Co-training, self-adaptive thresholds from FreeMatch, and Average Pseudo-Margins from MarginMatch -- resulting in a holistic approach that improves robustness and performance in SSL settings. Experimental results on benchmark datasets highlight the superior performance of MultiMatch, achieving state-of-the-art results on 9 out of 10 setups from 5 natural language processing datasets and ranking first according to the Friedman test among 19 methods. Furthermore, MultiMatch demonstrates exceptional robustness in highly imbalanced settings, outperforming the second-best approach by 3.26% -- and data imbalance is a key factor for many text classification tasks.
A MISMATCHED Benchmark for Scientific Natural Language Inference
Jun 05, 2025Scientific Natural Language Inference (NLI) is the task of predicting the semantic relation between a pair of sentences extracted from research articles. Existing datasets for this task are derived from various computer science (CS) domains, whereas non-CS domains are completely ignored. In this paper, we introduce a novel evaluation benchmark for scientific NLI, called MISMATCHED. The new MISMATCHED benchmark covers three non-CS domains-PSYCHOLOGY, ENGINEERING, and PUBLIC HEALTH, and contains 2,700 human annotated sentence pairs. We establish strong baselines on MISMATCHED using both Pre-trained Small Language Models (SLMs) and Large Language Models (LLMs). Our best performing baseline shows a Macro F1 of only 78.17% illustrating the substantial headroom for future improvements. In addition to introducing the MISMATCHED benchmark, we show that incorporating sentence pairs having an implicit scientific NLI relation between them in model training improves their performance on scientific NLI. We make our dataset and code publicly available on GitHub.
DynClean: Training Dynamics-based Label Cleaning for Distantly-Supervised Named Entity Recognition
Apr 06, 2025Distantly Supervised Named Entity Recognition (DS-NER) has attracted attention due to its scalability and ability to automatically generate labeled data. However, distant annotation introduces many mislabeled instances, limiting its performance. Most of the existing work attempt to solve this problem by developing intricate models to learn from the noisy labels. An alternative approach is to attempt to clean the labeled data, thus increasing the quality of distant labels. This approach has received little attention for NER. In this paper, we propose a training dynamics-based label cleaning approach, which leverages the behavior of a model as training progresses to characterize the distantly annotated samples. We also introduce an automatic threshold estimation strategy to locate the errors in distant labels. Extensive experimental results demonstrate that: (1) models trained on our cleaned DS-NER datasets, which were refined by directly removing identified erroneous annotations, achieve significant improvements in F1-score, ranging from 3.18% to 8.95%; and (2) our method outperforms numerous advanced DS-NER approaches across four datasets.
Active Few-Shot Learning for Text Classification
Feb 26, 2025The rise of Large Language Models (LLMs) has boosted the use of Few-Shot Learning (FSL) methods in natural language processing, achieving acceptable performance even when working with limited training data. The goal of FSL is to effectively utilize a small number of annotated samples in the learning process. However, the performance of FSL suffers when unsuitable support samples are chosen. This problem arises due to the heavy reliance on a limited number of support samples, which hampers consistent performance improvement even when more support samples are added. To address this challenge, we propose an active learning-based instance selection mechanism that identifies effective support instances from the unlabeled pool and can work with different LLMs. Our experiments on five tasks show that our method frequently improves the performance of FSL. We make our implementation available on GitHub.
SciER: An Entity and Relation Extraction Dataset for Datasets, Methods, and Tasks in Scientific Documents
Oct 28, 2024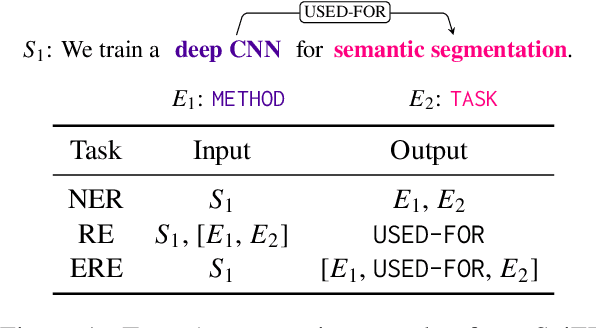
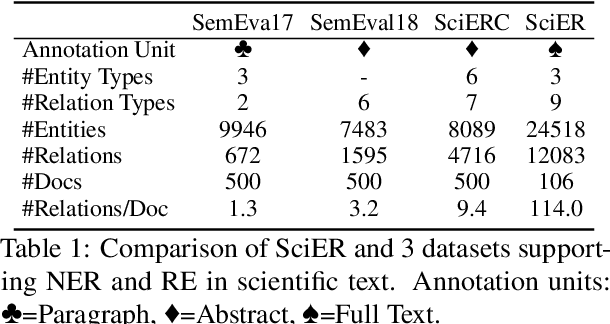


Scientific information extraction (SciIE) is critical for converting unstructured knowledge from scholarly articles into structured data (entities and relations). Several datasets have been proposed for training and validating SciIE models. However, due to the high complexity and cost of annotating scientific texts, those datasets restrict their annotations to specific parts of paper, such as abstracts, resulting in the loss of diverse entity mentions and relations in context. In this paper, we release a new entity and relation extraction dataset for entities related to datasets, methods, and tasks in scientific articles. Our dataset contains 106 manually annotated full-text scientific publications with over 24k entities and 12k relations. To capture the intricate use and interactions among entities in full texts, our dataset contains a fine-grained tag set for relations. Additionally, we provide an out-of-distribution test set to offer a more realistic evaluation. We conduct comprehensive experiments, including state-of-the-art supervised models and our proposed LLM-based baselines, and highlight the challenges presented by our dataset, encouraging the development of innovative models to further the field of SciIE.
Stanceformer: Target-Aware Transformer for Stance Detection
Oct 09, 2024The task of Stance Detection involves discerning the stance expressed in a text towards a specific subject or target. Prior works have relied on existing transformer models that lack the capability to prioritize targets effectively. Consequently, these models yield similar performance regardless of whether we utilize or disregard target information, undermining the task's significance. To address this challenge, we introduce Stanceformer, a target-aware transformer model that incorporates enhanced attention towards the targets during both training and inference. Specifically, we design a \textit{Target Awareness} matrix that increases the self-attention scores assigned to the targets. We demonstrate the efficacy of the Stanceformer with various BERT-based models, including state-of-the-art models and Large Language Models (LLMs), and evaluate its performance across three stance detection datasets, alongside a zero-shot dataset. Our approach Stanceformer not only provides superior performance but also generalizes even to other domains, such as Aspect-based Sentiment Analysis. We make the code publicly available.\footnote{\scriptsize\url{https://github.com/kgarg8/Stanceformer}}
How Hard is this Test Set? NLI Characterization by Exploiting Training Dynamics
Oct 04, 2024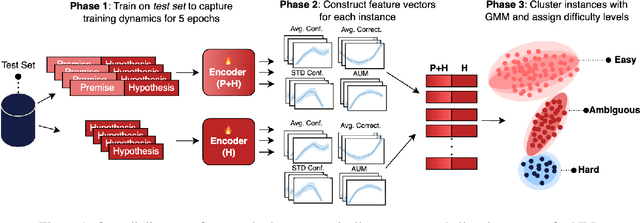
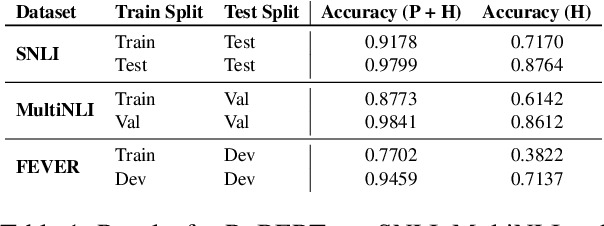

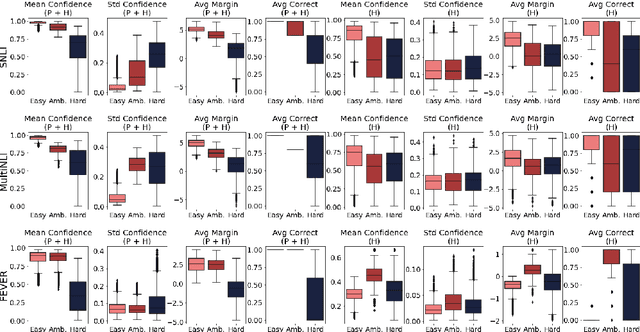
Natural Language Inference (NLI) evaluation is crucial for assessing language understanding models; however, popular datasets suffer from systematic spurious correlations that artificially inflate actual model performance. To address this, we propose a method for the automated creation of a challenging test set without relying on the manual construction of artificial and unrealistic examples. We categorize the test set of popular NLI datasets into three difficulty levels by leveraging methods that exploit training dynamics. This categorization significantly reduces spurious correlation measures, with examples labeled as having the highest difficulty showing markedly decreased performance and encompassing more realistic and diverse linguistic phenomena. When our characterization method is applied to the training set, models trained with only a fraction of the data achieve comparable performance to those trained on the full dataset, surpassing other dataset characterization techniques. Our research addresses limitations in NLI dataset construction, providing a more authentic evaluation of model performance with implications for diverse NLU applications.