 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Aware Numerical Representations for Transformer Language Models
Jan 14, 2026Transformer-based language models often achieve strong results on mathematical reasoning benchmarks while remaining fragile on basic numerical understanding and arithmetic operations. A central limitation is that numbers are processed as symbolic tokens whose embeddings do not explicitly encode numerical value, leading to systematic errors. We introduce a value-aware numerical representation that augments standard tokenized inputs with a dedicated prefix token whose embedding is explicitly conditioned on the underlying numerical value. This mechanism injects magnitude information directly into the model's input space while remaining compatible with existing tokenizers and decoder-only Transformer architectures. Evaluation on arithmetic tasks shows that the proposed approach outperforms baselines across numerical formats, tasks, and operand lengths. These results indicate that explicitly encoding numerical value is an effective and efficient way to improve fundamental numerical robustness in language models.
Training Language Models with homotokens Leads to Delayed Overfitting
Jan 06, 2026Subword tokenization introduces a computational layer in language models where many distinct token sequences decode to the same surface form and preserve meaning, yet induce different internal computations. Despite this non-uniqueness, language models are typically trained using a single canonical longest-prefix tokenization. We formalize homotokens-alternative valid subword segmentations of the same lexical item-as a strictly meaning-preserving form of data augmentation. We introduce a lightweight training architecture that conditions canonical next-token prediction on sampled homotoken variants via an auxiliary causal encoder and block-causal cross-attention, without modifying the training objective or token interface. In data-constrained pretraining, homotoken augmentation consistently delays overfitting under repeated data exposure and improves generalization across diverse evaluation datasets. In multilingual fine-tuning, we find that the effectiveness of homotokens depends on tokenizer quality: gains are strongest when canonical tokens are highly compressed and diminish when the tokenizer already over-fragments the input. Overall, homotokens provide a simple and modular mechanism for inducing tokenization invariance in language models.
The Strawberry Problem: Emergence of Character-level Understanding in Tokenized Language Models
May 21, 2025Despite their remarkable progress across diverse domains, Large Language Models (LLMs) consistently fail at simple character-level tasks, such as counting letters in words, due to a fundamental limitation: tokenization. In this work, we frame this limitation as a problem of low mutual information and analyze it in terms of concept emergence. Using a suite of 19 synthetic tasks that isolate character-level reasoning in a controlled setting, we show that such capabilities emerge slowly, suddenly, and only late in training. We further show that percolation-based models of concept emergence explain these patterns, suggesting that learning character composition is not fundamentally different from learning commonsense knowledge. To address this bottleneck, we propose a lightweight architectural modification that significantly improves character-level reasoning while preserving the inductive advantages of subword models. Together, our results bridge low-level perceptual gaps in tokenized LMs and provide a principled framework for understanding and mitigating their structural blind spots. We make our code publicly available.
How Hard is this Test Set? NLI Characterization by Exploiting Training Dynamics
Oct 04, 2024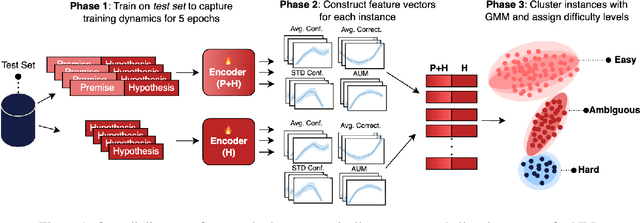
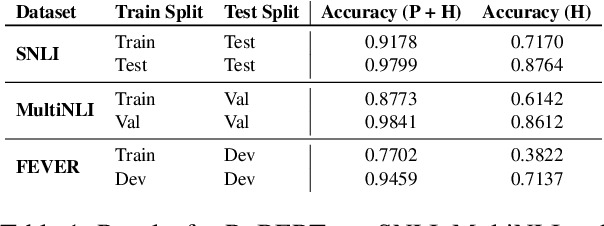

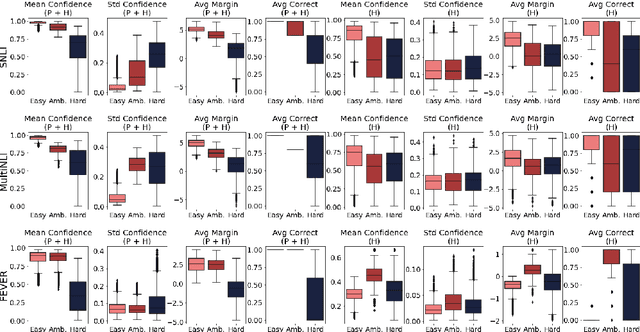
Natural Language Inference (NLI) evaluation is crucial for assessing language understanding models; however, popular datasets suffer from systematic spurious correlations that artificially inflate actual model performance. To address this, we propose a method for the automated creation of a challenging test set without relying on the manual construction of artificial and unrealistic examples. We categorize the test set of popular NLI datasets into three difficulty levels by leveraging methods that exploit training dynamics. This categorization significantly reduces spurious correlation measures, with examples labeled as having the highest difficulty showing markedly decreased performance and encompassing more realistic and diverse linguistic phenomena. When our characterization method is applied to the training set, models trained with only a fraction of the data achieve comparable performance to those trained on the full dataset, surpassing other dataset characterization techniques. Our research addresses limitations in NLI dataset construction, providing a more authentic evaluation of model performance with implications for diverse NLU applications.
Romanian Diacritics Restoration Using Recurrent Neural Networks
Sep 06, 2020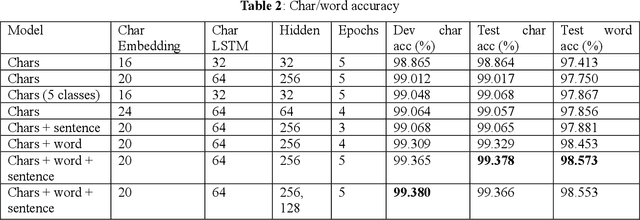
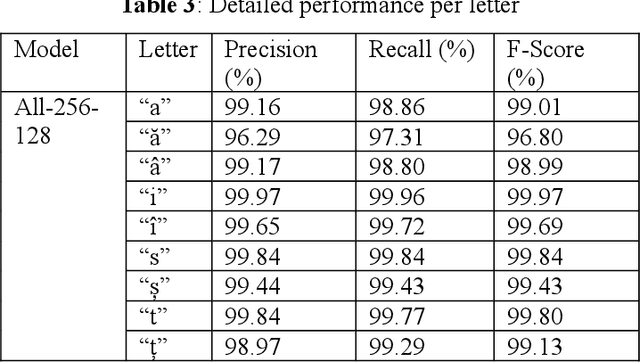
Diacritics restoration is a mandatory step for adequately processing Romanian texts, and not a trivial one, as you generally need context in order to properly restore a character. Most previous methods which were experimented for Romanian restoration of diacritics do not use neural networks. Among those that do, there are no solutions specifically optimized for this particular language (i.e., they were generally designed to work on many different languages). Therefore we propose a novel neural architecture based on recurrent neural networks that can attend information at different levels of abstractions in order to restore diacritics.
Answering questions by learning to rank -- Learning to rank by answering questions
Sep 02, 2019



Answering multiple-choice questions in a setting in which no supporting documents are explicitly provided continues to stand as a core problem in natural language processing. The contribution of this article is two-fold. First, it describes a method which can be used to semantically rank documents extracted from Wikipedia or similar natural language corpora. Second, we propose a model employing the semantic ranking that holds the first place in two of the most popular leaderboards for answering multiple-choice questions: ARC Easy and Challenge. To achieve this, we introduce a self-attention based neural network that latently learns to rank documents by their importance related to a given question, whilst optimizing the objective of predicting the correct answer. These documents are considered relevant contexts for the underlying question. We have published the ranked documents so that they can be used off-the-shelf to improve downstream decision models.
Improving Retrieval-Based Question Answering with Deep Inference Models
Dec 07, 2018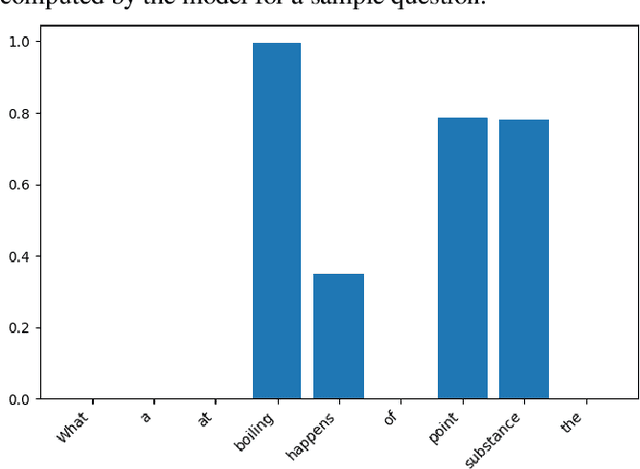
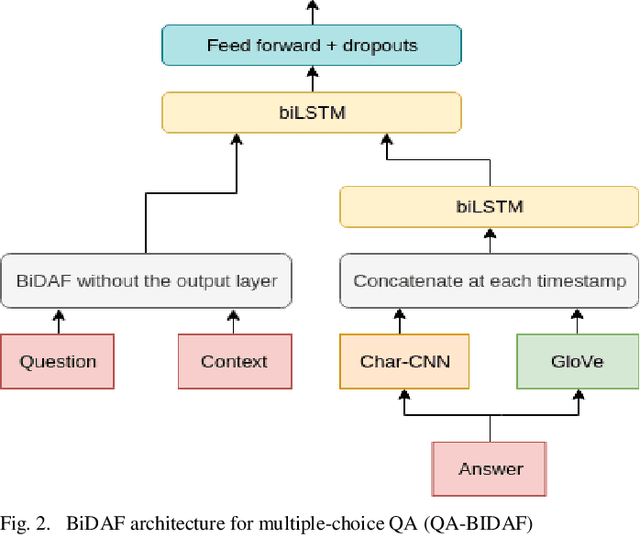
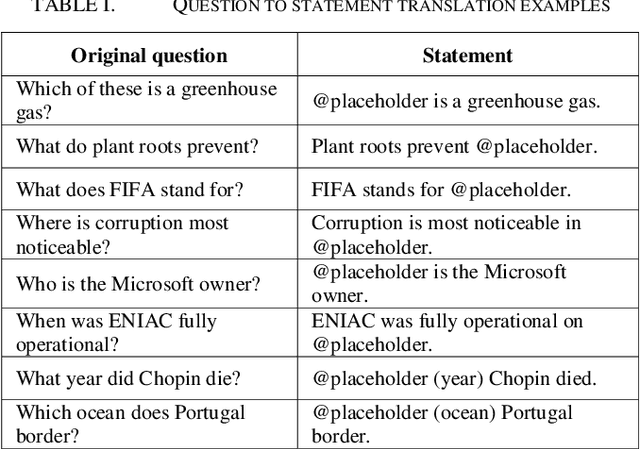
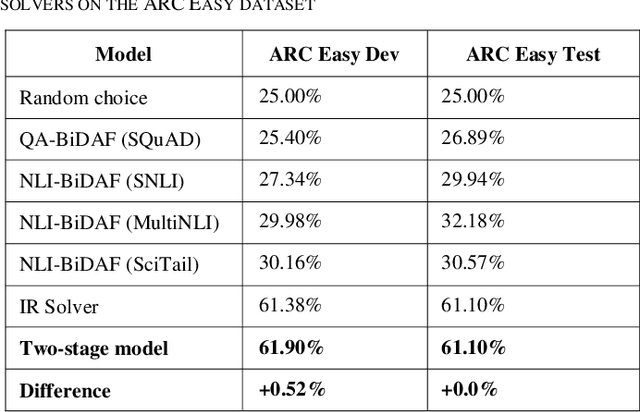
Question answering is one of the most important and difficult applications at the border of information retrieval and natural language processing, especially when we talk about complex science questions which require some form of inference to determine the correct answer. In this paper, we present a two-step method that combines information retrieval techniques optimized for question answering with deep learning models for natural language inference in order to tackle the multi-choice question answering in the science domain. For each question-answer pair, we use standard retrieval-based models to find relevant candidate contexts and decompose the main problem into two different sub-problems. First, assign correctness scores for each candidate answer based on the context using retrieval models from Lucene. Second, we use deep learning architectures to compute if a candidate answer can be inferred from some well-chosen context consisting of sentences retrieved from the knowledge base. In the end, all these solvers are combined using a simple neural network to predict the correct answer. This proposed two-step model outperforms the best retrieval-based solver by over 3% in absolute accuracy.